python 多線程爬取壁紙網站的示例
基本開發環境
· Python 3.6
· Pycharm
需要導入的庫

目標網頁分析
網站是靜態網站,沒有加密,可以直接爬取
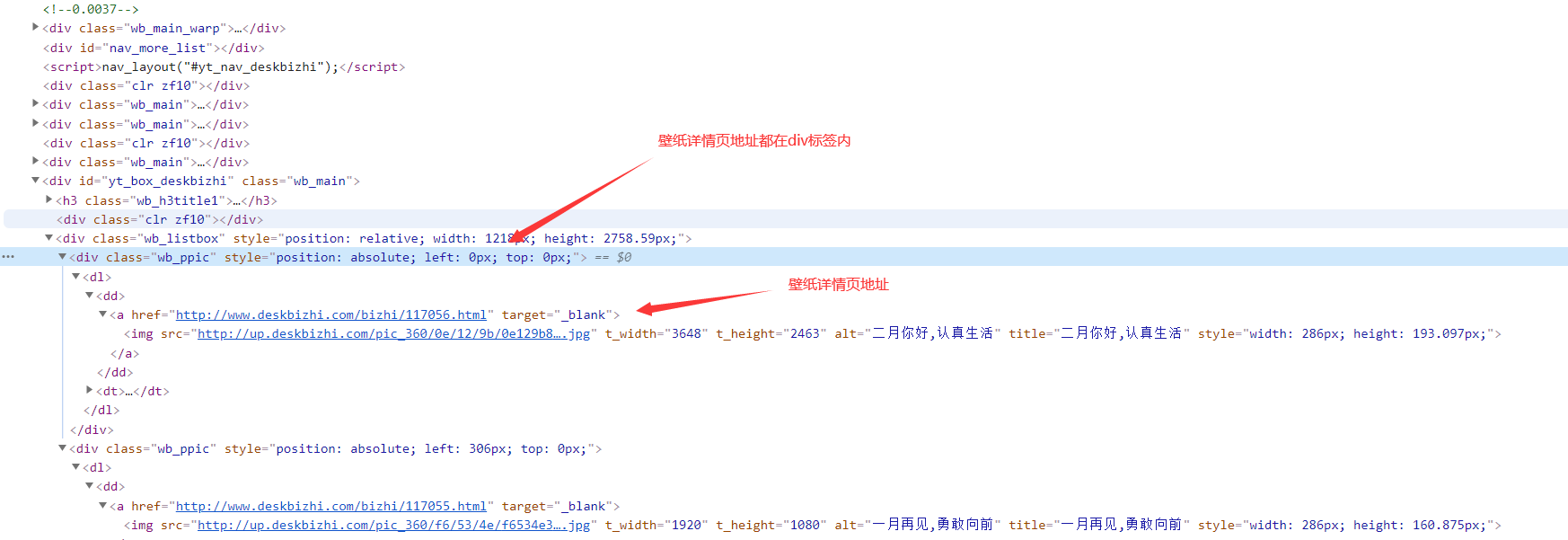
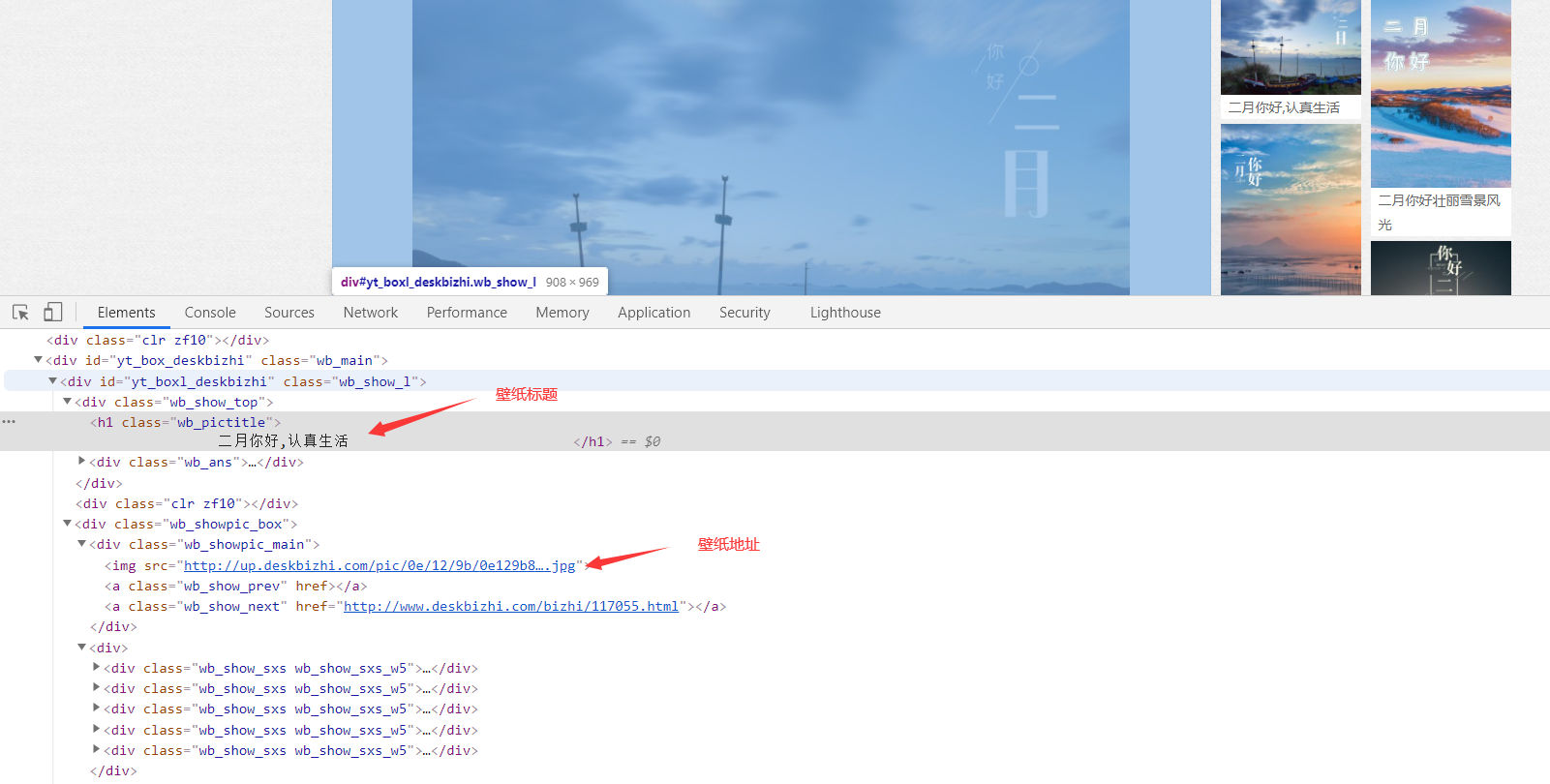
整體思路:
1、先在列表頁面獲取每張壁紙的詳情頁地址
2、在壁紙詳情頁面獲取壁紙真實高清url地址
3、保存地址
代碼實現
模擬瀏覽器請請求網頁,獲取網頁數據
這裡隻選擇爬取前10頁的數據
代碼如下
import threading
import parsel
import requests
def get_html(html_url):
'''
獲取網頁源代碼
:param html_url: 網頁url
:return:
'''
response = requests.get(url=html_url, headers=headers)
return response
def get_par(html_data):
'''
把 response.text 轉換成 selector 對象 解析提取數據
:param html_data: response.text
:return: selector 對象
'''
selector = parsel.Selector(html_data)
return selector
def download(img_url, title):
'''
保存數據
:param img_url: 圖片地址
:param title: 圖片標題
:return:
'''
content = get_html(img_url).content
path = '壁紙\\' + title + '.jpg'
with open(path, mode='wb') as f:
f.write(content)
print('正在保存', title)
def main(url):
'''
主函數
:param url: 列表頁面 url
:return:
'''
html_data = get_html(url).text
selector = get_par(html_data)
lis = selector.css('.wb_listbox div dl dd a::attr(href)').getall()
for li in lis:
img_data = get_html(li).text
img_selector = get_par(img_data)
img_url = img_selector.css('.wb_showpic_main img::attr(src)').get()
title = img_selector.css('.wb_pictitle::text').get().strip()
download(img_url, title)
end_time = time.time() - s_time
print(end_time)
if __name__ == '__main__':
for page in range(1, 11):
url = 'http://www.deskbizhi.com/min/list-{}.html'.format(page)
main_thread = threading.Thread(target=main, args=(url,))
main_thread.start()
以上就是python 多線程爬取壁紙網站的示例的詳細內容,更多關於python 爬取壁紙網站的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- Python實現多線程爬表情包詳解
- Python爬取csnd文章並轉為PDF文件
- Python爬蟲入門教程02之筆趣閣小說爬取
- Python爬蟲實戰之虎牙視頻爬取附源碼
- 如何用Python一次性下載抖音上音樂