PyTorch 遷移學習實踐(幾分鐘即可訓練好自己的模型)
前言
如果你認為深度學習非常的吃GPU,或者說非常的耗時間,訓練一個模型要非常久,但是你如果瞭解瞭遷移學習那你的模型可能隻需要幾分鐘,而且準確率不比你自己訓練的模型準確率低,本節我們將會介紹兩種方法來實現遷移學習
遷移學習方法介紹
微調網絡的方法實現遷移學習,更改最後一層全連接,並且微調訓練網絡將模型看成特征提取器,如果一個模型的預訓練模型非常的好,那完全就把前面的層看成特征提取器,凍結所有層並且更改最後一層,隻訓練最後一層,這樣我們隻訓練瞭最後一層,訓練會非常的快速
遷移基本步驟
- 數據的準備
- 選擇數據增廣的方式
- 選擇合適的模型
- 更換最後一層全連接
- 凍結層,開始訓練
- 選擇預測結果最好的模型保存
需要導入的包
import zipfile # 解壓文件 import torchvision from torchvision import datasets, transforms, models import torch from torch.utils.data import DataLoader, Dataset import os import cv2 import numpy as np import matplotlib.pyplot as plt from PIL import Image import copy
數據準備
本次實驗的數據到這裡下載
首先按照上一章節講的數據讀取方法來準備數據
# 解壓數據到指定文件
def unzip(filename, dst_dir):
z = zipfile.ZipFile(filename)
z.extractall(dst_dir)
unzip('./data/hymenoptera_data.zip', './data/')
# 實現自己的Dataset方法,主要實現兩個方法__len__和__getitem__
class MyDataset(Dataset):
def __init__(self, dirname, transform=None):
super(MyDataset, self).__init__()
self.classes = os.listdir(dirname)
self.images = []
self.transform = transform
for i, classes in enumerate(self.classes):
classes_path = os.path.join(dirname, classes)
for image_name in os.listdir(classes_path):
self.images.append((os.path.join(classes_path, image_name), i))
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image_name, classes = self.images[idx]
image = Image.open(image_name)
if self.transform:
image = self.transform(image)
return image, classes
def get_claesses(self):
return self.classes
# 分佈實現訓練和預測的transform
train_transform = transforms.Compose([
transforms.Grayscale(3),
transforms.RandomResizedCrop(224), #隨機裁剪一個area然後再resize
transforms.RandomHorizontalFlip(), #隨機水平翻轉
transforms.Resize(size=(256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Grayscale(3),
transforms.Resize(size=(256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 分別實現loader
train_dataset = MyDataset('./data/hymenoptera_data/train/', train_transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=32)
val_dataset = MyDataset('./data/hymenoptera_data/val/', val_transform)
val_loader = DataLoader(val_dataset, shuffle=True, batch_size=32)
選擇預訓練的模型
這裡我們選擇瞭resnet18在ImageNet 1000類上進行瞭預訓練的
model = models.resnet18(pretrained=True) # 使用預訓練
使用model.buffers查看網絡基本結構
<bound method Module.buffers of ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)>
我們現在需要做的就是將最後一層進行替換
only_train_fc = True
if only_train_fc:
for param in model.parameters():
param.requires_grad_(False)
fc_in_features = model.fc.in_features
model.fc = torch.nn.Linear(fc_in_features, 2, bias=True)
註釋:only_train_fc如果我們設置為True那麼就隻訓練最後的fc層
現在觀察一下可導的參數有那些(在隻訓練最後一層的情況下)
for i in model.parameters():
if i.requires_grad:
print(i)
Parameter containing:
tensor([[ 0.0342, -0.0336, 0.0279, ..., -0.0428, 0.0421, 0.0366],
[-0.0162, 0.0286, -0.0379, ..., -0.0203, -0.0016, -0.0440]],
requires_grad=True)
Parameter containing:
tensor([-0.0120, -0.0086], requires_grad=True)
註釋:由於最後一層使用瞭bias因此我們會多加兩個參數
訓練主體的實現
epochs = 50
loss_fn = torch.nn.CrossEntropyLoss()
opt = torch.optim.SGD(lr=0.01, params=model.parameters())
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# device = torch.device('cpu')
model.to(device)
opt_step = torch.optim.lr_scheduler.StepLR(opt, step_size=20, gamma=0.1)
max_acc = 0
epoch_acc = []
epoch_loss = []
for epoch in range(epochs):
for type_id, loader in enumerate([train_loader, val_loader]):
mean_loss = []
mean_acc = []
for images, labels in loader:
if type_id == 0:
# opt_step.step()
model.train()
else:
model.eval()
images = images.to(device)
labels = labels.to(device).long()
opt.zero_grad()
with torch.set_grad_enabled(type_id==0):
outputs = model(images)
_, pre_labels = torch.max(outputs, 1)
loss = loss_fn(outputs, labels)
if type_id == 0:
loss.backward()
opt.step()
acc = torch.sum(pre_labels==labels) / torch.tensor(labels.shape[0], dtype=torch.float32)
mean_loss.append(loss.cpu().detach().numpy())
mean_acc.append(acc.cpu().detach().numpy())
if type_id == 1:
epoch_acc.append(np.mean(mean_acc))
epoch_loss.append(np.mean(mean_loss))
if max_acc < np.mean(mean_acc):
max_acc = np.mean(mean_acc)
print(type_id, np.mean(mean_loss),np.mean(mean_acc))
print(max_acc)
在使用cpu訓練的情況,也能快速得到較好的結果,這裡訓練瞭50次,其實很快的就已經得到瞭很好的結果瞭
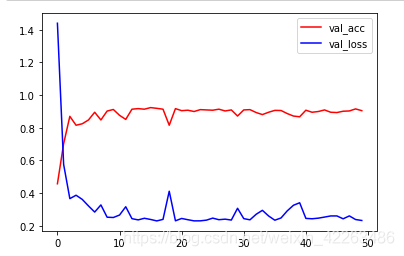
總結
本節我們使用瞭預訓練模型,發現大概10個epoch就可以很快的得到較好的結果瞭,即使在使用cpu情況下訓練,這也是遷移學習為什麼這麼受歡迎的原因之一瞭,如果讀者有興趣可以自己試一試在不凍結層的情況下,使用方法一能否得到更好的結果
到此這篇關於PyTorch 遷移學習實踐(幾分鐘即可訓練好自己的模型)的文章就介紹到這瞭,更多相關PyTorch 遷移內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- PyTorch實現圖像識別實戰指南
- Pytorch中關於BatchNorm2d的參數解釋
- pytorch中LN(LayerNorm)及Relu和其變相的輸出操作
- Pytorch實現ResNet網絡之Residual Block殘差塊
- 淺談Pytorch 定義的網絡結構層能否重復使用