Python爬取csnd文章並轉為PDF文件
本篇文章流程(爬蟲基本思路):
數據來源分析 (隻有當你找到數據來源的時候, 才能通過代碼實現)
- 確定需求(要爬取的內容是什麼?)爬取CSDN文章內容 保存pdf
- 通過開發者工具進行抓包分析 分析數據從哪裡來的?
代碼實現過程:
- 發送請求 對於文章列表頁面發送請求
- 獲取數據 獲取網頁源代碼
- 解析數據 文章的url 以及 文章標題
- 發送請求 對於文章詳情頁url地址發送請求
- 獲取數據 獲取網頁源代碼
- 解析數據 提取文章標題 / 文章內容
- 保存數據 把文章內容保存成html文件
- 把html文件轉成pdf文件
- 多頁爬取
1.導入模塊
import requests # 數據請求 發送請求 第三方模塊 pip install requests import parsel # 數據解析模塊 第三方模塊 pip install parsel import os # 文件操作模塊 import re # 正則表達式模塊 import pdfkit # pip install pdfkit
2.創建文件夾
filename = 'pdf\\' # 文件名字 filename_1 = 'html\\' if not os.path.exists(filename): #如果沒有這個文件夾的話 os.mkdir(filename) # 自動創建一下這個文件夾 if not os.path.exists(filename_1): #如果沒有這個文件夾的話 os.mkdir(filename_1) # 自動創建一下這個文件夾
3.發送請求
for page in range(1, 11):
print(f'=================正在爬取第{page}頁數據內容=================')
url = f'https://blog.csdn.net/qdPython/article/list/{page}'
# python代碼對於服務器發送請求 >>> 服務器接收之後(如果沒有偽裝)被識別出來, 是爬蟲程序, >>> 不會給你返回數據
# 客戶端(瀏覽器) 對於 服務器發送請求 >>> 服務器接收到請求之後 >>> 瀏覽器返回一個response響應數據
# headers 請求頭 就是把python代碼偽裝成瀏覽器進行請求
# headers參數字段 是可以在開發者工具裡面進行查詢 復制
# 並不是所有的參數字段都是需要的
# user-agent: 瀏覽器的基本信息 (相當於披著羊皮的狼, 這樣可以混進羊群裡面)
# cookie: 用戶信息 檢測是否登錄賬號 (某些網站 是需要登錄之後才能看到數據, B站一些數據內容)
# referer: 防盜鏈 請求你的網址 是從哪裡跳轉過來的 (B站視頻內容 / 妹子圖圖片下載 / 唯品會商品數據)
# 根據不同的網站內容 具體情況 具體分析
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 請求方式: get請求 post請求 通過開發者工具可以查看url請求方式是什麼樣的
# 搜索 / 登錄 /查詢 這樣是post請求
response = requests.get(url=url, headers=headers)
4.數據解析
# 需要把獲取到的html字符串數據轉成 selector 解析對象
selector = parsel.Selector(response.text)
# getall 返回的是列表
href = selector.css('.article-list a::attr(href)').getall()
5.如果把列表裡面每一個元素 都提取出來
for index in href:
# 發送請求 對於文章詳情頁url地址發送請求
response_1 = requests.get(url=index, headers=headers)
selector_1 = parsel.Selector(response_1.text)
title = selector_1.css('#articleContentId::text').get()
new_title = change_title(title)
content_views = selector_1.css('#content_views').get()
html_content = html_str.format(article=content_views)
html_path = filename_1 + new_title + '.html'
pdf_path = filename + new_title + '.pdf'
with open(html_path, mode='w', encoding='utf-8') as f:
f.write(html_content)
print('正在保存: ', title)
6.替換特殊字符
def change_title(name): mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]') new_name = re.sub(mode, '_', name) return new_name
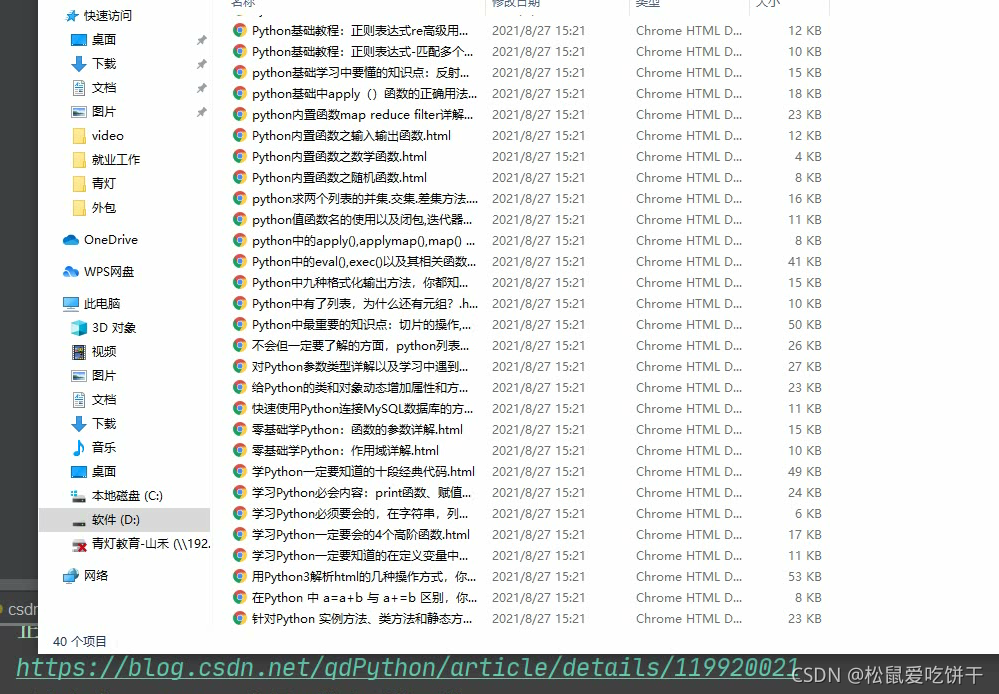
運行代碼,即可下載HTML文件:
7.轉換成PDF文件
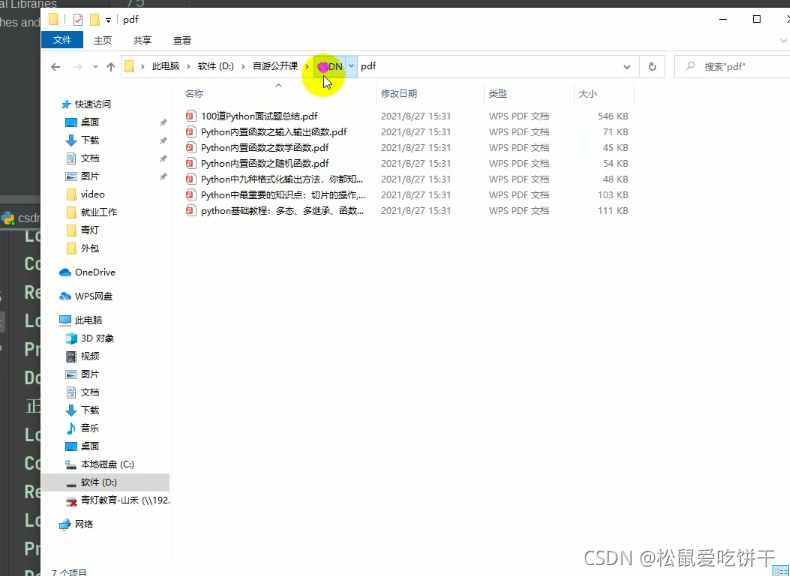
config = pdfkit.configuration(wkhtmltopdf=r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe') pdfkit.from_file(html_path, pdf_path, configuration=config)
到此這篇關於Python爬取csnd文章並轉為PDF文件的文章就介紹到這瞭,更多相關Python爬取csnd文章內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python實現csdn全部博文下載並轉PDF
- Python爬蟲入門教程02之筆趣閣小說爬取
- python 多線程爬取壁紙網站的示例
- Python爬蟲實戰演練之采集糗事百科段子數據
- Python實現多線程爬表情包詳解