C# 解決在Dictionary中使用枚舉的效率問題
使用字典的好處
System.Collections.Generic命名空間下的Dictionary,它的功能非常好用,且功能與現實中的字典是一樣的。
它同樣擁有目錄和正文,目錄用來進行第一次的粗略查找,正文進行第二次精確查找。通過將數據進行分組,形成目錄,正文則是分組後的結果。它是一種空間換時間的方式,犧牲大的內存換取高效的查詢效率。所以,功能使用率查詢>新增時優先考慮字典。
public static Tvalue DicTool<Tkey, Tvalue>(Tkey key, Dictionary<Tkey, Tvalue> dic)
{
return dic.TryGetValue(key, out Tvalue _value) ? _value : (Tvalue)default;
}
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 1; i++)
{
DicTool(0, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
執行時間00:00:00.0003135
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 10000; i++)
{
DicTool(0, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
執行時間00:00:00.0005091
從上面可以看出,它進行大量查詢時的用時非常短,查詢效率極高。但使用時需要避免使用枚舉作為關鍵詞進行查詢;它會造成查詢效率降低。
使用枚舉作為key時查詢效率變低
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 10000; i++)
{
DicTool(MyEnum.one, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
執行時間00:00:00.0011010
從這裡的執行時間可以看出,查詢效率大大降低。
優化方案: 使用int代替enum,enum強制轉型後間接查詢;可使查詢效率與非枚舉的直接查詢相近。(還有其他的優化方案,個人隻使用過這個)
using System;
using System.Diagnostics;
using System.Collections.Generic;
namespace Test
{
public class Program
{
public enum MyEnum : int
{
one,
two,
three
}
public static void Main(string[] args)
{
Dictionary<int, int> Dic = new Dictionary<int, int>()
{
{ (int)MyEnum.one,1},
{ (int)MyEnum.two,2},
{ (int)MyEnum.three,3}
};
Stopwatch stopwatch = Stopwatch.StartNew();
for (int i = 0; i < 10000; i++)
{
DicTool((int)MyEnum.one, Dic);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.Elapsed);
}
public static Tvalue DicTool<Tkey, Tvalue>(Tkey key, Dictionary<Tkey, Tvalue> dic)
{
return dic.TryGetValue(key, out Tvalue _value) ? _value : (Tvalue)default;
}
}
}
執行時間 00:00:00.0005005
為什麼使用枚舉會降低效率
使用ILSpy軟件反編譯源碼,得到以下:
public bool TryGetValue(TKey key, out TValue value)
{
int num = this.FindEntry(key);
if (num >= 0)
{
value = this.entries[num].value;
return true;
}
value = default(TValue);
return false;
}
private int FindEntry(TKey key)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (this.buckets != null)
{
int num = this.comparer.GetHashCode(key) & 2147483647;
for (int i = this.buckets[num % this.buckets.Length]; i >= 0; i = this.entries[i].next)
{
if (this.entries[i].hashCode == num && this.comparer.Equals(this.entries[i].key, key))
{
return i;
}
}
}
return -1;
}
查看Dictionary源碼後可以知道,效率減低來源於this.comparer.GetHashCode(key) 這段代碼。
comparer是使用瞭泛型的成員,它內部使用int類型不會發生裝箱,但是由於Enum沒有IEquatable接口,內部運行時會引起裝箱行為,該行為降低瞭查詢的效率。
IEquatable源碼:
namespace System
{
[__DynamicallyInvokable]
public interface IEquatable<T>
{
[__DynamicallyInvokable]
bool Equals(T other);
}
}
裝箱:值類型轉換為引用類型(隱式轉換)
把數據從棧復制到托管堆中,棧中改為存儲數據地址。
拆箱:引用類型轉換為值類型(顯式轉換)
補充:C#中Dictionary<Key,Value>中[]操作的效率問題
今天有朋友問到如果一個Dictionary<Key,Value>中如果數據量很大時,那麼[ ]操作會不會效率很低。
感謝微軟開源C#,讓我們有機會通過代碼驗證自己的猜想。
此處是微軟C#的源代碼地址
先上結論:Dictionary<Key,Value>的[ ]操作的時間 = 一次調用GetHashCode + n次調用Key.Equals的時間之和。
期中n受傳入的key的GetHashCode 的重復率影響,比如傳入的key的hash值為5,Dictionary中hash值為5的值有100個,這100值相當於用鏈表存儲,如果要查找的值在第20個那麼n的值就是19。如果GetHashCode 基本沒什麼重復率,那麼n始終1,極端情況下n可能為一個很大的數(參考測試代碼)。
C#中的關鍵代碼如下:
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
同時在這裡我想說一下Dictionary<Key,Value>類中數據的組織結構:
private struct Entry {
public int hashCode; // Lower 31 bits of hash code, -1 if unused
public int next; // Index of next entry, -1 if last
public TKey key; // Key of entry
public TValue value; // Value of entry
}
private int[] buckets;
private Entry[] entries;
期中buckets是保存所有的相同hash值的Entry的鏈表頭,而相同hash值的Entry是通過Entry .next連接起來的。在新加入的Value時,如果已經存在相同hash值會將buckets中的值更新,如果不存在則會加入新的值,關鍵代碼如下:
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
註意最後一句,將新加入值的下標inddex的值賦值給瞭buckets,這樣相當於就更新瞭鏈表頭指針。這個鏈表就是前面產生n的原因。
下面我放一些測試的結果:
當GetHashCode的消耗為1ms時:
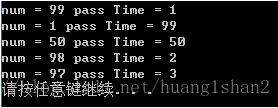
當GetHashCode的消耗為100ms時:

增加的消耗是99ms也就是GetHashCode增加的消耗,後面的尾數就是上面公式裡的n。
附測試代碼如下:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Threading;
namespace ConsoleApplication1
{
class Program
{
public class Test1
{
private ushort num = 0;
public Test1(ushort a)
{
num = a;
}
public override int GetHashCode()
{
Thread.Sleep(1);
return num / 100;
}
public override bool Equals(object obj)
{
Thread.Sleep(1);
return num.Equals((obj as Test1).num);
}
}
static void Main(string[] args)
{
Dictionary<Test1, string> testDic = new Dictionary<Test1, string>();
for (ushort a = 0; a < 100; a++)
{
Test1 temp = new Test1(a);
testDic.Add(temp, a.ToString());
}
Stopwatch stopWatch = new Stopwatch();
string str = "";
stopWatch.Start();
str = testDic[new Test1(99)];
stopWatch.Stop();
Console.WriteLine("num = " + str +" pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(1)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(50)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(98)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
stopWatch.Restart();
str = testDic[new Test1(97)];
stopWatch.Stop();
Console.WriteLine("num = " + str + " pass Time = " + stopWatch.ElapsedMilliseconds);
}
}
}
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。如有錯誤或未考慮完全的地方,望不吝賜教。
推薦閱讀:
- None Found