如何使用正則匹配最後一個字符串詳解
前幾天遇到一個需求,輸入的是
<user>
<user>
<name>a</name>
</user>
<user>
<name>a</name>
</user>
</user>
<password>123</password>
要求拿到
<user>
<user>
<name>a</name>
</user>
<user>
<name>a</name>
</user>
</user>
也就是去掉最後一個</user>後面的字符串。
方法有很多,我首先想到的是用正則匹配去掉</user>後面的字符串。
最後寫出來的表達式是
(?<=</user>)(?![\w\W]*</user>)[\w\W]+。
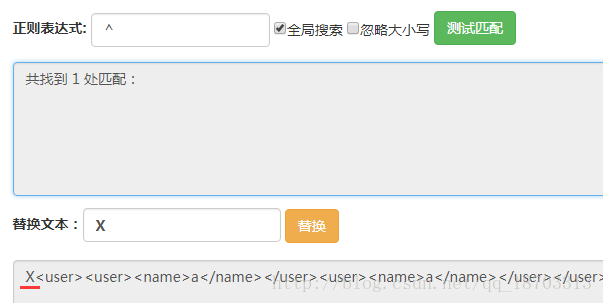
首先用(?<=</user>)匹配所有前面是</user>的位置,如圖,總共有三個位置。

這裡我們正則表達式(?<=</user>)的意思就是匹配的位置之前的字符串是</user>,也就是我們匹配到的位置在</user>之後。
這裡用到瞭正則表達式語法中的斷言,有的書上也稱該語法為預查或者環視,都是一樣的用法。有如下語法:
(?=pattern) 零寬正向先行斷言 (?!pattern) 零寬負向先行斷言 (?<=pattern) 零寬正向後行斷言 (?<!pattern) 零寬負向後行斷言
這裡用到的是(?<=pattern),零寬表示它匹配的是在字符串中的位置,如同^匹配字符串串首,$匹配字符串串尾。正向代表它必須滿足pattern。後行代表它匹配的位置在pattern之後。
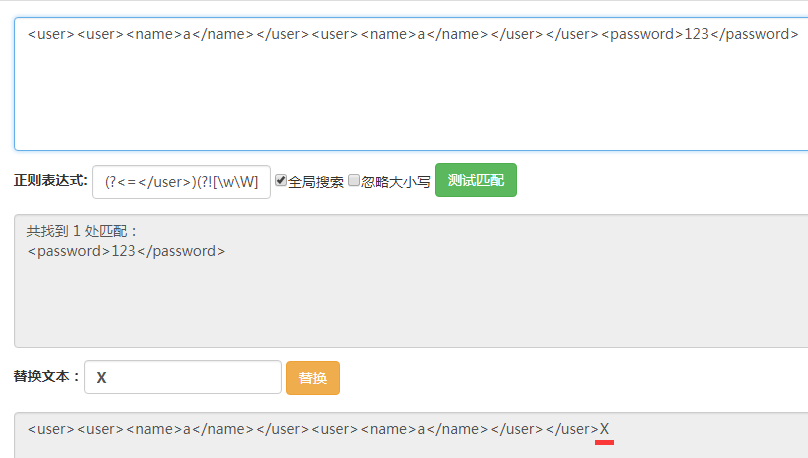
其次,再這三個位置上進行篩選,能夠看出這三個位置的區別是後面是否有</user>,如果沒有的話那麼它就是最後一個</user>後面的位置。在之前的表達式後面添上(?![\w\W]*?</user>)此時表達式變為(?<=</user>)(?![\w\W]*?</user>)。

能夠看到得到瞭最後一個匹配結果。
這裡的正則表達式(?!pattern) 是零寬負向先行斷言,也就是它會往後匹配pattern,匹配到的位置在pattern之前,並且匹配到的字符串必須不滿足pattern。
(?![\w\W]*?</user>)的意思是在匹配到的位置後面必須不是[\w\W]*?</user>,\w匹配的是[a-zA-Z0-9_]即匹配字母數字和下劃線,而\W匹配的是[^a-zA-Z0-9_]即不是字母數字也不是下劃線的字符,同時匹配這兩個就相當於匹配任意字符。[\w\W]後面的*代表匹配0-任意多次,後面的?代表懶惰模式,即隻要滿足條件就立即返回。
最後,在之前的正則表達式後面加上[\w\W]+貪婪匹配即盡可能多的匹配該位置後面的字符串。最終的正則表達式是(?<=</user>)(?![\w\W]*?</user>)[\w\W]*
最後的最後用四張圖簡單地描述四種斷言的不同之處。
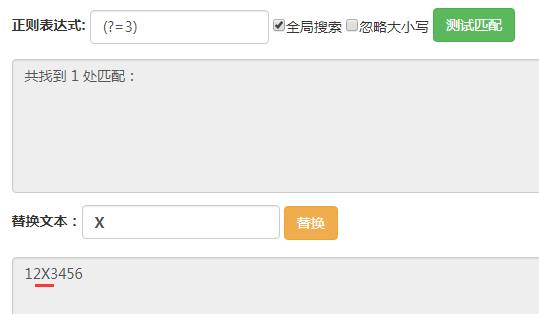
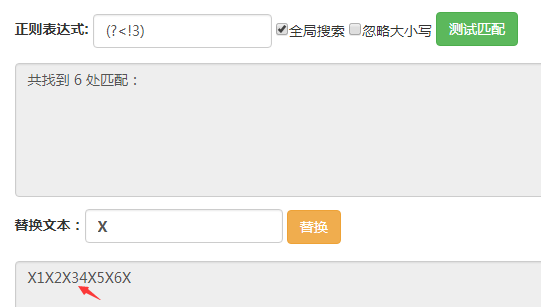
這裡輸入的字符串都是123456。
(?=3),它匹配的位置是後面的字符為3的位置。
(?<=3),它匹配的位置是前面的字符為3的位置。

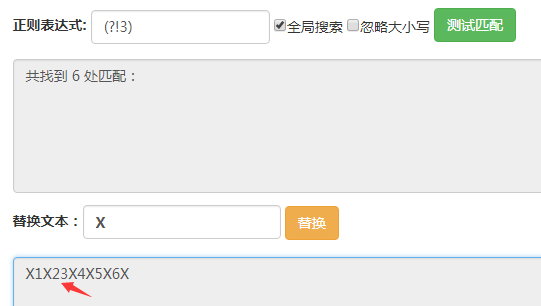
(?!3)匹配的位置是後面的字符不為3的位置,可以看到箭頭所指的地方沒有被匹配到,其他位置都被匹配到瞭。
(?<!3)匹配的位置是前面的字符不為3的位置,可以看到箭頭所指的地方沒有被匹配到,其他位置都被匹配到瞭。
總結
到此這篇關於如何使用正則匹配最後一個字符串詳解的文章就介紹到這瞭,更多相關正則匹配最後一個字符串內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found