MySQL之MyISAM存儲引擎的非聚簇索引詳解
在InnoDB中索引即數據,也就是聚簇索引的那顆B+樹的葉子節點中已經包含瞭所有完整的用戶記錄。MyISAM的索引方案雖然也是使用樹形結構,但是卻將索引和數據分開存儲,這種索引也叫非聚簇索引。
create table index_demo( c1 int, c2 int, c3 char(1), primary key(c1) ) ROW_FORMAT=COMPACT;
將表中的記錄按照記錄的插入順序單獨存儲在一個文件中,這個文件並不劃分為若幹個數據頁,有多少記錄就往這個文件中塞多少個記錄,這樣一來,我們就可以通過行號快速訪問到一條記錄。在表中使用MyISAM作為存儲引擎時,它的記錄在存儲空間中的表示如圖:
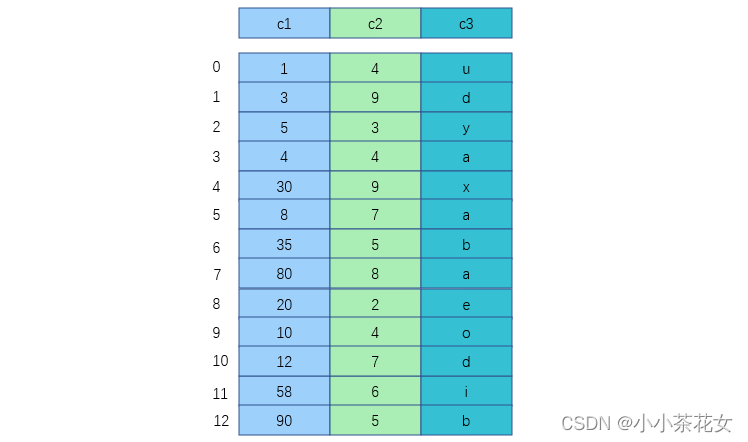
由於在插入數據時並沒有刻意按照主鍵大小排序,所以我們不能再這些數據上使用二分法進行查找,使用MyISAM存儲引擎的表會把索引信息單獨存儲在另外一個文件中,稱為索引文件。MyISAM會為表的主鍵單獨創建一個索引,隻不過在索引的葉子節點中存儲的不是完整的用戶記錄,而是主鍵值和行號的組合。也就是先通過索引找到對應的行號,再通過行號去找對應的記錄。
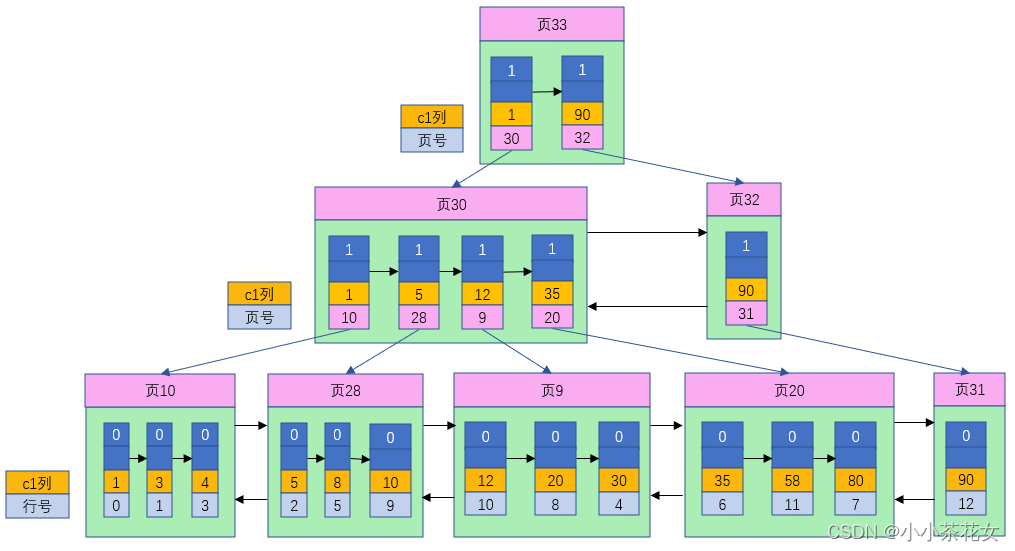
在InnoDB存儲引擎中,我們隻需要根據主鍵值對聚簇索引進行一次查找就能找到對應的記錄;在MyISAM存儲引擎中,需要進行一次回表操作,這也意味著MyISAM中建立的索引相當於全部都是二級索引。
MyISAM會直接在索引葉子節點處存儲該條記錄在數據文件中的地址偏移量。由此可以看出MyISAM的回表操作時十分快速的,因為它是拿著地址偏移量直接到文件中取數據,而InnoDB是通過獲取主鍵之後再去聚簇索引中找記錄,雖然說不慢,但是也比不上直接用地址去訪問。
如果有必要,我們也可以為其他列分別建立索引或者建立聯合索引,其原理與InnoDB中索引差不多,隻不過在葉子節點處存儲的是相應的列+行號,這些索引頁全部都是二級索引。
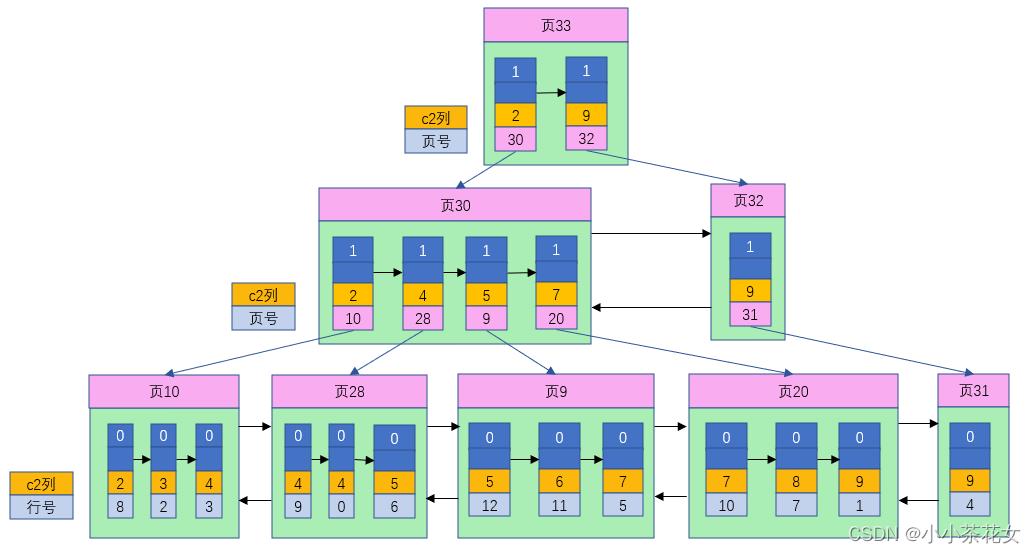
可以看到對於非聚簇索引,不管是以主鍵為排序規則還是以非主鍵為排序規則,它的結構都是相同的,即葉子節點存放的都是相應的列+行號。
總結
本篇文章就到這裡瞭,希望能夠給你帶來幫助,也希望您能夠多多關註WalkonNet的更多內容!