關於keras多任務多loss回傳的思考
如果有一個多任務多loss的網絡,那麼在訓練時,loss是如何工作的呢?
比如下面:
model = Model(inputs = input, outputs = [y1, y2]) l1 = 0.5 l2 = 0.3 model.compile(loss = [loss1, loss2], loss_weights=[l1, l2], ...)
其實我們最終得到的loss為
final_loss = l1 * loss1 + l2 * loss2
我們最終的優化效果是最小化final_loss。
問題來瞭,在訓練過程中,是否loss2隻更新得到y2的網絡通路,還是loss2會更新所有的網絡層呢?
此問題的關鍵在梯度回傳上,即反向傳播算法。
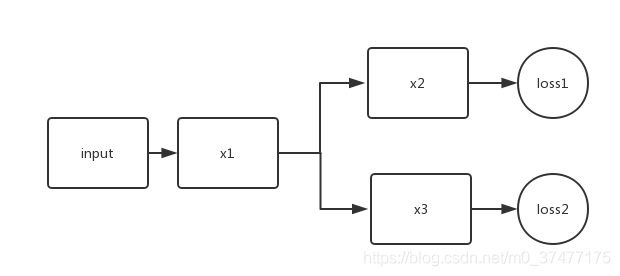

所以loss1隻對x1和x2有影響,而loss2隻對x1和x3有影響。
補充:keras 多個LOSS總和定義
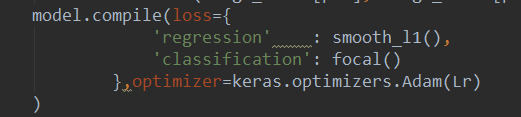
用字典形式,名字是模型中輸出那一層的名字,這裡的loss可以是自己定義的,也可是自帶的
補充:keras實戰-多類別分割loss實現
本文樣例均為3d數據的onehot標簽形式,即y_true(batch_size,x,y,z,class_num)
1、dice loss
def dice_coef_fun(smooth=1):
def dice_coef(y_true, y_pred):
#求得每個sample的每個類的dice
intersection = K.sum(y_true * y_pred, axis=(1,2,3))
union = K.sum(y_true, axis=(1,2,3)) + K.sum(y_pred, axis=(1,2,3))
sample_dices=(2. * intersection + smooth) / (union + smooth) #一維數組 為各個類別的dice
#求得每個類的dice
dices=K.mean(sample_dices,axis=0)
return K.mean(dices) #所有類別dice求平均的dice
return dice_coef
def dice_coef_loss_fun(smooth=0):
def dice_coef_loss(y_true,y_pred):
return 1-1-dice_coef_fun(smooth=smooth)(y_true=y_true,y_pred=y_pred)
return dice_coef_loss
2、generalized dice loss
def generalized_dice_coef_fun(smooth=0):
def generalized_dice(y_true, y_pred):
# Compute weights: "the contribution of each label is corrected by the inverse of its volume"
w = K.sum(y_true, axis=(0, 1, 2, 3))
w = 1 / (w ** 2 + 0.00001)
# w為各個類別的權重,占比越大,權重越小
# Compute gen dice coef:
numerator = y_true * y_pred
numerator = w * K.sum(numerator, axis=(0, 1, 2, 3))
numerator = K.sum(numerator)
denominator = y_true + y_pred
denominator = w * K.sum(denominator, axis=(0, 1, 2, 3))
denominator = K.sum(denominator)
gen_dice_coef = numerator / denominator
return 2 * gen_dice_coef
return generalized_dice
def generalized_dice_loss_fun(smooth=0):
def generalized_dice_loss(y_true,y_pred):
return 1 - generalized_dice_coef_fun(smooth=smooth)(y_true=y_true,y_pred=y_pred)
return generalized_dice_loss
3、tversky coefficient loss
# Ref: salehi17, "Twersky loss function for image segmentation using 3D FCDN"
# -> the score is computed for each class separately and then summed
# alpha=beta=0.5 : dice coefficient
# alpha=beta=1 : tanimoto coefficient (also known as jaccard)
# alpha+beta=1 : produces set of F*-scores
# implemented by E. Moebel, 06/04/18
def tversky_coef_fun(alpha,beta):
def tversky_coef(y_true, y_pred):
p0 = y_pred # proba that voxels are class i
p1 = 1 - y_pred # proba that voxels are not class i
g0 = y_true
g1 = 1 - y_true
# 求得每個sample的每個類的dice
num = K.sum(p0 * g0, axis=( 1, 2, 3))
den = num + alpha * K.sum(p0 * g1,axis= ( 1, 2, 3)) + beta * K.sum(p1 * g0, axis=( 1, 2, 3))
T = num / den #[batch_size,class_num]
# 求得每個類的dice
dices=K.mean(T,axis=0) #[class_num]
return K.mean(dices)
return tversky_coef
def tversky_coef_loss_fun(alpha,beta):
def tversky_coef_loss(y_true,y_pred):
return 1-tversky_coef_fun(alpha=alpha,beta=beta)(y_true=y_true,y_pred=y_pred)
return tversky_coef_loss
4、IoU loss
def IoU_fun(eps=1e-6):
def IoU(y_true, y_pred):
# if np.max(y_true) == 0.0:
# return IoU(1-y_true, 1-y_pred) ## empty image; calc IoU of zeros
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3]) - intersection
#
ious=K.mean((intersection + eps) / (union + eps),axis=0)
return K.mean(ious)
return IoU
def IoU_loss_fun(eps=1e-6):
def IoU_loss(y_true,y_pred):
return 1-IoU_fun(eps=eps)(y_true=y_true,y_pred=y_pred)
return IoU_loss
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。