MySQL一些常用高級SQL語句
MySQL高級SQL語句
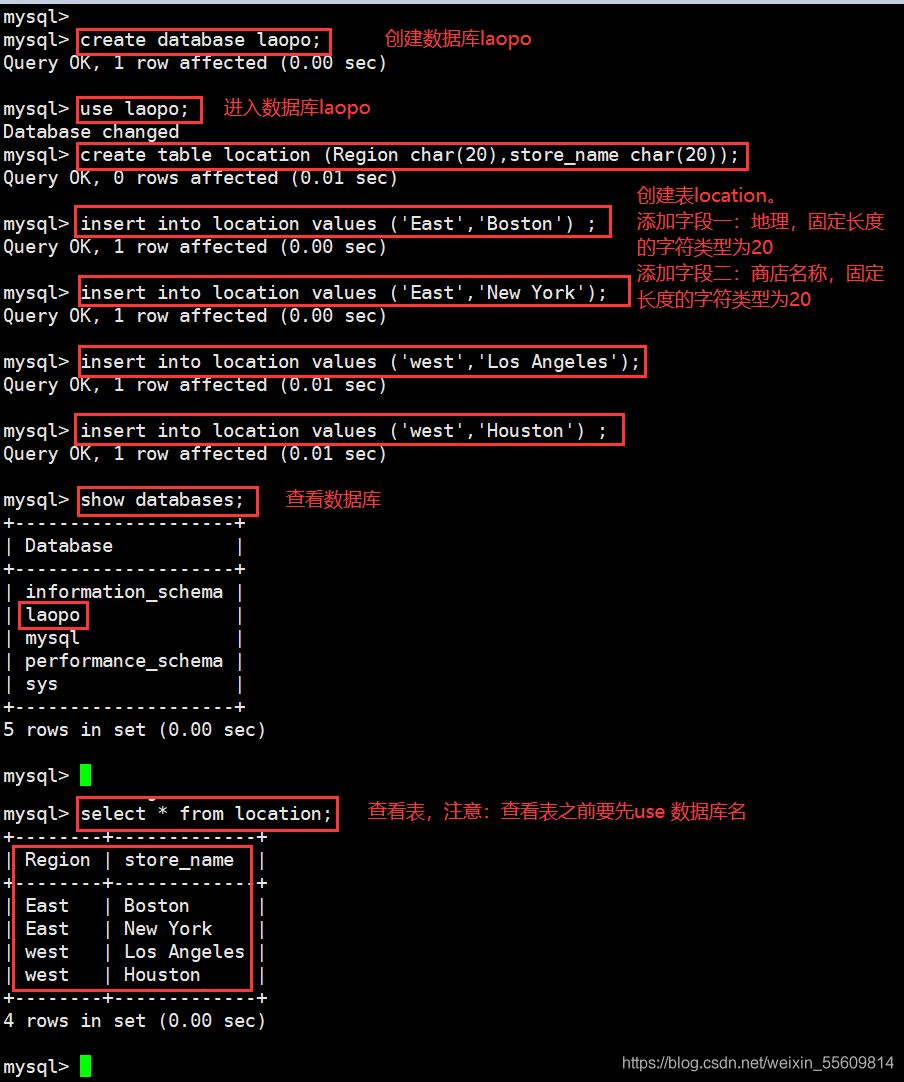
use kgc;
create table location (Region char(20),store_name char(20));
insert into location values ('East','Boston') ;
insert into location values ('East','New York');
insert into location values ('west','Los Angeles');
insert into location values ('west','Houston') ;
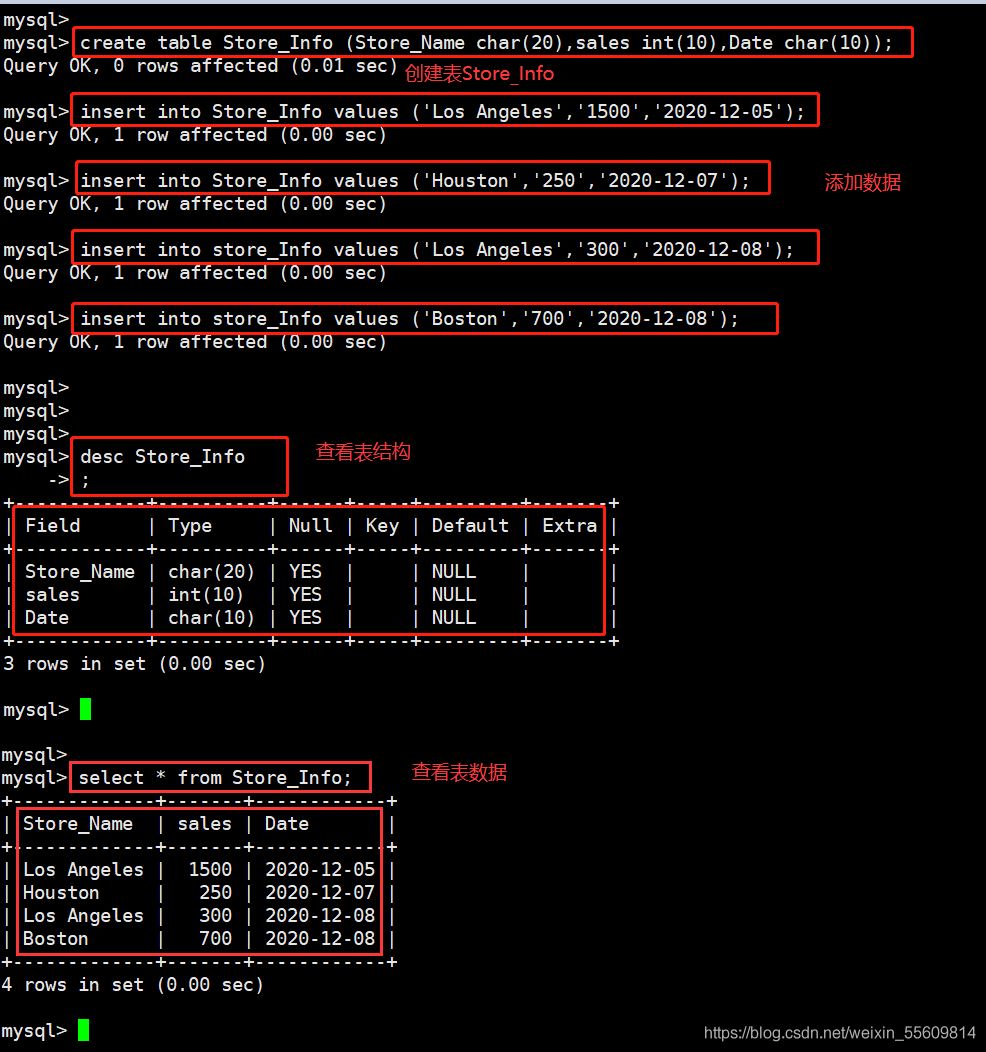
create table Store_Info (Store_Name char(20),sales int(10),Date char(10));
insert into Store_Info values ('Los Angeles','1500','2020-12-05');
insert into Store_Info values ('Houston','250','2020-12-07');
insert into Store_Info values ('Los Angeles','300','2020-12-08');
insert into Store_Info values ('Boston','700','2020-12-08');
SELECT
---- SELECT ---- 顯示表格中一個或數個欄位的所有資料 語法: SELECT "欄位" FROM "表名"; SELECT Store_Name FROM Store_Info;

DISTINCT
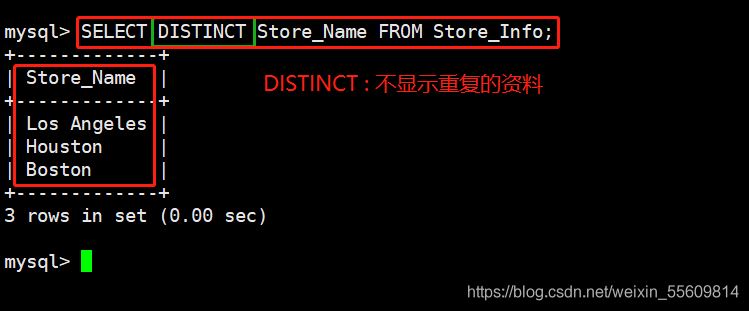
---- DISTINCT ---- 不顯示重復的資料 語法: SELECT DISTINCT "欄位" FROM "表名"; SELECT DISTINCT Store_Name FROM Store_Info;
WHERE
---- WHERE ---- 有條件查詢 語法:SELECT "欄位” FROM "表名" WHERE "條件"; SELECT Store_Name FROM Store_Info WHERE Sales > 1000;

AND OR
---- AND OR ---- 且 或
語法:SELECT "欄位" FROM "表名” WHERE "條件1" {[ANDIOR] "條件2"}+;
SELECT Store_Name FROM Store_Info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);

IN
---- IN ---- 顯示己知的值的資料
語法: SELECT "欄位" FROM "表名" WHERE "欄位" IN ('值1','值2', ...);
SELECT * FROM Store_Info WHERE Store_Name IN ('Los Angeles','Houston');

BETWEEN
---- BETWEEN ---- 顯示兩個值范圍內的資料 語法:SELECT "欄位" FROM "表名" WHERE "欄位" BETWEEN '值1' AND '值2'; SELECT * FROM Store_Info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';

通配符
---- 通配符 ---- 通常通配符都是跟LIKE一起使用的
% : 百分號表示零個、一個或多個字符
_ : 下劃線表示單個字符
'A_Z':所有以‘A'起頭,另一個任何值的字符,且以Z'為結尾的字符串。例如,'A.BZ'和‘A.22'都符合這一個模式,而‘AKK2'並不符合(因為在A和Z之間有兩個字符,而不是一個字符)。
'ABC%':所有以'ABC'起頭的字符串。例如,'ABCD'和'ABCABC'都符合這個模式。
'%XYZ':所有以'XYZ'結尾的字符串。例如,'WXYZ'和‘ZZXYZ'都符合這個模式。
'%AN%':所有含有'AN'這個模式的字符串。例如,'LOS ANGELES'和'SAN FRANCISCO'都符合這個模式。
'_AN%':所有第二個字母為‘A'和第三個字母為'N'的字符串。例如,'SAMN FRANCITSCO'符合這個模式,而'LOS ANGELES'則不符合這個模式。
---- LIKE ---- 匹配一個模式來找出我們要的資料
語法:SELECT "欄位" FROM "表名" WHERE "欄位" LIKE {模式};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';
---- ORDER BY ---- 按關鍵字排序
語法:SELECT "欄位" FROM "表名" [WHERE "條件"] ORDER BY "欄位" [ASC,DESC];
#ASC是按照升序進行排序的,是默認的排序方式。
#DESC是按降序方式進行排序。
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;

函數 數學函數
abs(x) #返回x的絕對值 rand() #返回0到1的隨機數 mod(x,y) #返回x除以y以後的餘數 power(x,y) #返回x的y次方 round(x) #返回離x最近的整數 round(x,y) #保留x的y位小數四舍五入後的值 sqrt(x) #返回x的平方根 truncate(x,y) #返回數字x截斷為y位小數的值 ceil(×) #返回大於或等於x的最小整數 floor(x) #返回小於或等於x的最大整數 greatest(x1,x2...) #返回集合中最大的值 least(x1,x2...) #返回集合中最小的值 SELECT abs(-1),rand(),mod(5,3),power(2,3),round(1.89); SELECT round(1.8937,3),truncate(1.235,2),ceil(5.2),floor(2.1),least(1.89,3,6.1,2.1);

聚合函數
聚合函數: avg() #返回指定列的平均值 count() #返回指定列中非 NULL值的個數 min() #返回指定列的最小值 max() #返回指定列的最大值 sum(x) #返回指定列的所有值之和 SELECT avg(Sales) FROM Store_Info; SELECT count(store_Name) FROM Store_Info; SELECT count(DISTINCT store_Name) FROM Store_Info; SELECT max(Sales) FROM Store_Info; SELECT min(sales) FROM Store_Info; SELECT sum(sales) FROM Store_Info; SELECT count(DISTINCT store_Name) FROM Store_Info; SELECT count(*) FROM Store_Info; #count(*)包括瞭所有的列的行數,在統計結果的時候,不會忽略列值為NULL #count(列名)隻包括列名那一列的行數,在統計結果的時候,會忽略列值為NULL的行

字符串函數
字符串函數: trim() #返回去除指定格式的值 concat(x,y) #將提供的參數x和y拼接成一個字符串 substr(x,y) #獲取從字符串x中的第y個位置開始的字符串,跟substring()函數作用相同 substr(x,y,z) #獲取從字符串x中的第y個位置開始長度為z的字符串 length(x) #返回字符串x的長度 replace(x,y,z) #將字符串z替代字符串x中的字符串y upper(x) #將字符串x的所有字母變成大寫字母 lower(x) #將字符串x的所有字母變成小寫字母 left(x,y) #返回字符串x的前y個字符 right(x,y) #返回字符串x的後y個字符 repeat(x,y) #將字符串x重復y次 space(x) #返回x個空格 strcmp (x,y) #比較x和y,返回的值可以為-1,0,1 reverse(x) #將字符串x反轉 SELECT concat(Region,Store_Name) FROM location WHERE Store_Name = 'Boston'; #如sql_mode開啟開啟瞭PIPES_AS_CONCAT,"||"視為字符串的連接操作符而非或運算符,和字符串的拼接函數concat相類似,這和Oracle數據庫使用方法一樣的 SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston'; SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles'; SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York'; SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串); #[位置]:的值可以為 LEADING(起頭),TRAILING(結尾),BOTH(起頭及結尾)。 #[要移除的字符串]:從字串的起頭、結尾,或起頭及結尾移除的字符串。缺省時為空格 SELECT TRIM(LEADING 'Ne' FROM 'New York'); SELECT Region,length(Store_Name) FROM location; SELECT REPLACE(Region,'ast','astern')FROM location;


---- GROUP BY ---- 對GROUP BY後面的欄位的查詢結果進行匯總分組,通常是結合聚合函數一起使用的
GROUP BY有一個原則,就是SELECT後面的所有列中,沒有使用聚合函數的列,必須出現在GROUP BY後面。
語法:SELECT "欄位1",SUM("欄位2") FROM "表名" GROUP BY "欄位1";
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;
---- HAVING ---- 用來過濾由GROUP BY語句返回的記錄集,通常與GROUP BY語句聯合使用
HAVING語句的存在彌補瞭wHERE關鍵字不能與聚合函數聯合使用的不足。如果被SELECcT的隻有函數欄,那就不需要GROUP BY子句。
語法:SELECT "欄位1",SUM("欄位2") FROM "表格名" GROUP BY "欄位1" HAVING (函數條件);
SELECT Store_Name,SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM (Sales) > 1500;
---- 別名 ---- 欄位別名表格別名
語法:SELECT "表格別名"."欄位1” [AS] "欄位別名" FROM "表格名" [AS] "表格別名"
SELECT A.Store_Name Store,SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;
---- 子查詢 ---- 連接表格,在WHERE子句或 HAVING子句中插入另一個 SQL語句
語法: SELECT "欄位1" FROM "表格1" WHERE "欄位2" [比較運算符] #外查詢
(SELECT "欄位1" FROM "表格2" WHERE "條件"); #內查詢
可以是符號的運算符,例如 =、>、<、>=、<= ;也可以是文字的運算符,例如LIKE、IN、BETWEEN
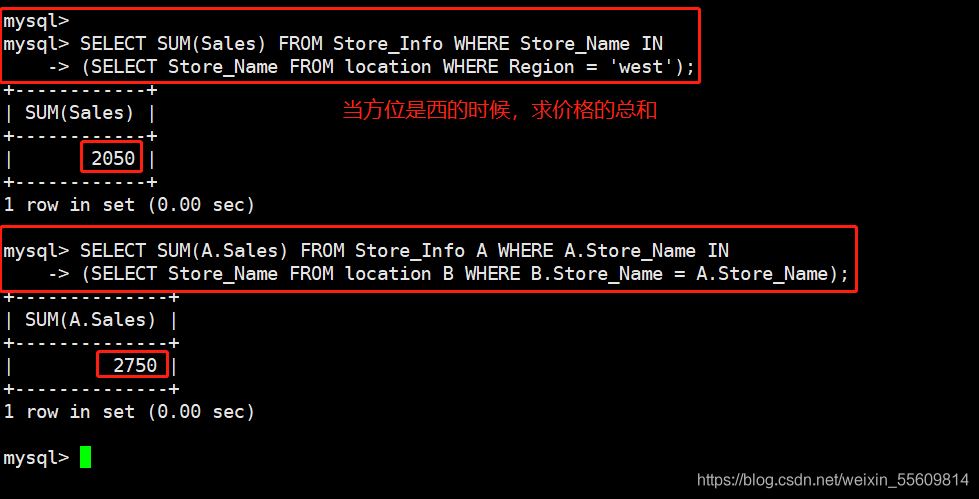
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'west');
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);
EXISTS
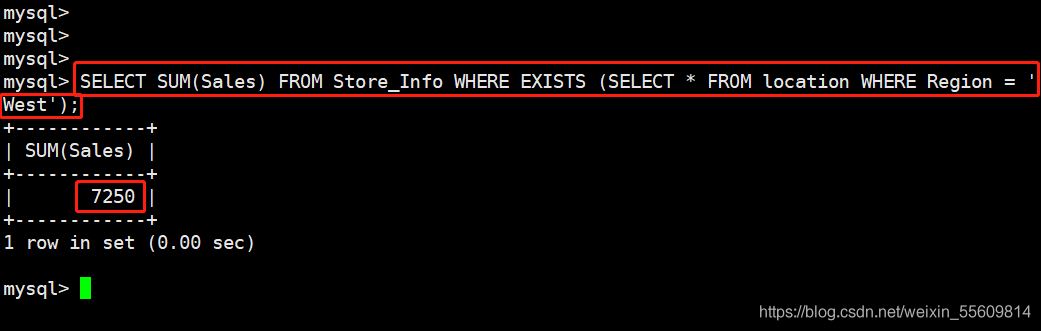
---- EXISTS ---- 用來測試內查詢有沒有產生任何結果,類似佈爾值是否為真 #如果有的話,系統就會執行外查詢中的SQL語句。若是沒有的話,那整個SQL語句就不會產生任何結果。 語法: SELECT "欄位1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "條件"); SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');
連接查詢
location 表格
UPDATE Store_Info SET store_name='washington'WHERE sales=300;
Store_Info表格

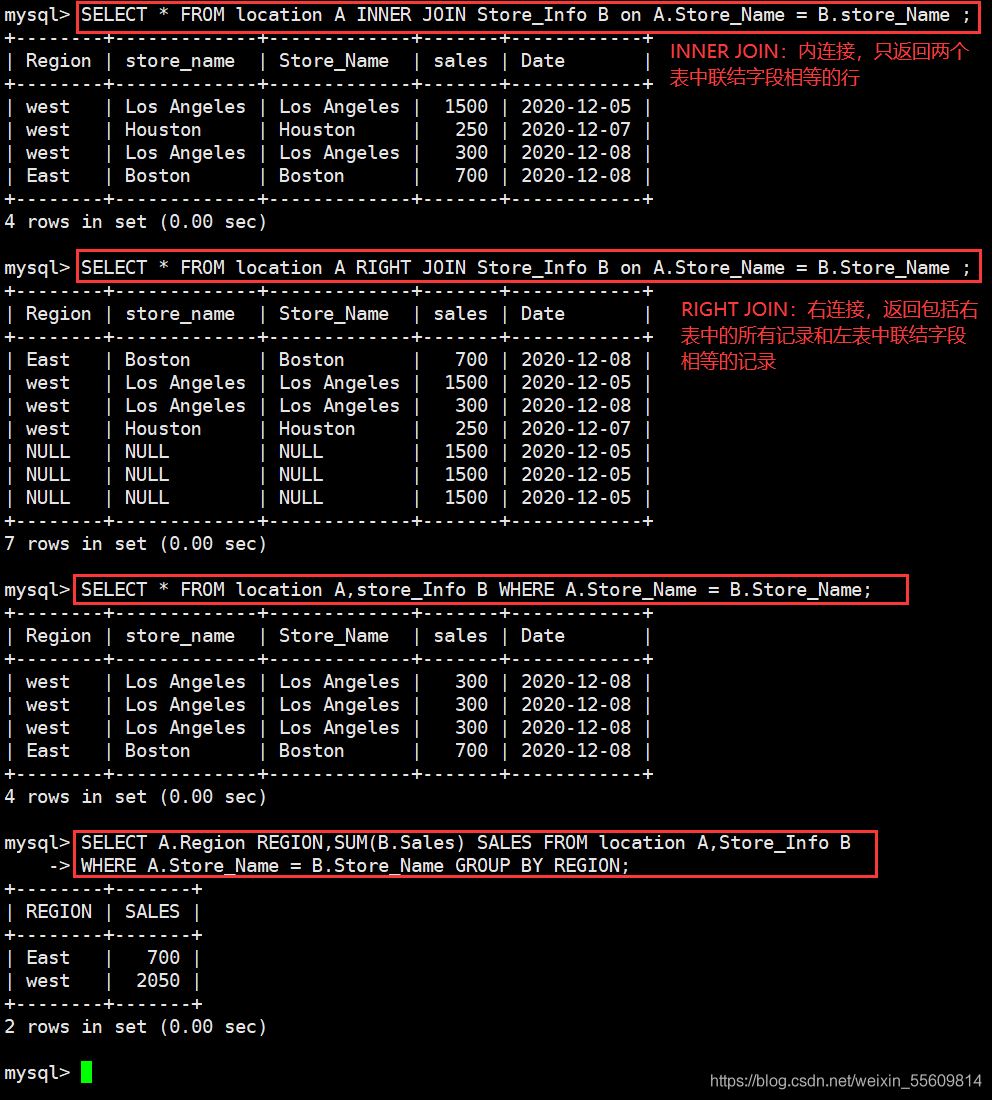
inner join(內連接):隻返回兩個表中聯結字段相等的行 left join(左連接):返回包括左表中的所有記錄和右表中聯結字段相等的記錄 right join(右連接):返回包括右表中的所有記錄和左表中聯結字段相等的記錄 SELECT * FROM location A INNER JOIN Store_Info B on A.Store_Name = B.store_Name ; SELECT * FROM location A RIGHT JOIN Store_Info B on A.Store_Name = B.Store_Name ; SELECT * FROM location A,store_Info B WHERE A.Store_Name = B.Store_Name; SELECT A.Region REGION,SUM(B.Sales) SALES FROM location A,Store_Info B WHERE A.Store_Name = B.Store_Name GROUP BY REGION;
CREATE VIEW
---- CREATE VIEW ---- 視圖,可以被當作是虛擬表或存儲查詢。 ·視圖跟表格的不同是,表格中有實際儲存資料,而視圖是建立在表格之上的一個架構,它本身並不實際儲存資料。 ·臨時表在用戶退出或同數據庫的連接斷開後就自動消失瞭,而視圖不會消失。 ·視圖不含有數據,隻存儲它的定義,它的用途一般可以簡化復雜的查詢。比如你要對幾個表進行連接查詢,而且還要進行統計排序等操作,寫SQT語句會很麻煩的,用視圖將幾個表聯結起來,然後對這個視圖進行查詢操作,就和對一個表查詢一樣,很方便。 語法:CREATE VIEW "視圖表名” AS "SELECT語句"; CREATE VIEW V_REGION_SALES AS SELECT A.Region REGION, SUM(B.Sales) SALES FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION; SELECT * FROM V_REGION_SALES; DROP VIEW V_REGION_SALES;

UNION
---- UNION ---- 聯集,將兩個SQL語句的結果合並起來,兩個SQI語句所產生的欄位需要是同樣的資料種類 UNION:生成結果的資料值將沒有重復,且按照字段的順序進行排序 語法:[SELECT 語句 1] UNION [SELECT 語句2]; UNION ALL:將生成結果的資料值都列出來,無論有無重復 語法:[SELECT 語句 1] UNION ALL [SELECT 語句 2]; SELECT Store_Name FROM location UNION SELECT Store_Name FROM Store_Info; SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM Store_Info;

交集值
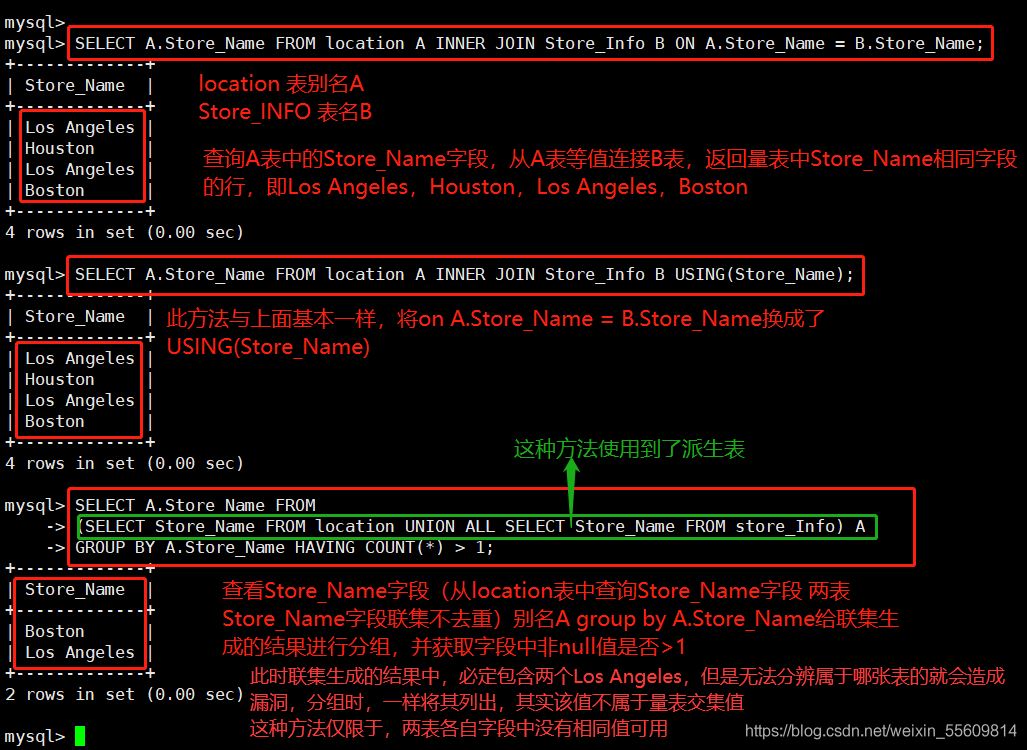
----- 交集值 ---- 取兩個SQL語句結果的交集 SELECT A.Store_Name FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name; SELECT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name); #兩表基中的一個表沒有指定的行,而另一個表這個行有重復,並且確實有交集的時候用 SELECT A.Store_Name FROM (SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM store_Info) A GROUP BY A.Store_Name HAVING COUNT(*) > 1; #取兩個sQL語句結果的交集,且沒有重復 SELECT A.Store_Name FRONM (SELECT B.Store_Name FROM location B INNER JOIN Store_Info C ON B.Store_Name = C.store_Name) A GROUP BY A.Store_Name; SELECT DISTINCT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name); SELECT DISTIMCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM Store_Info); SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
無交集值
---- 無交集值 ---- 顯示第一個sQL語句的結果,且與第二個SQL語句沒有交集的結果,且沒有重復 SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM Store_Info); SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NULL;

CASE
---- CASE ---- 是 SQL 用來做為 IF-THEN-ELSE 之類邏輯的關鍵字
語法:
SELECT CASE ("欄位名")
WHEN "條件1” THEN "結果1"
WHEN "條件2" THEN "結果2"
...
[ELSE "結果N"]
END
FROM "表名";
#"條件"可以是一個數值或是公式。ELSE子句則並不是必須的。
SELECT store_Name, CASE Store_Name
WHEN 'Los Angeles' THEN Sales * 2
WHEN 'Boston' THEN Sales * 1.5
ELSE Sales
END
"New Sales",Date
FROM Store_Info;
#"New Sales"是用於CASE 那個欄位的欄位名。
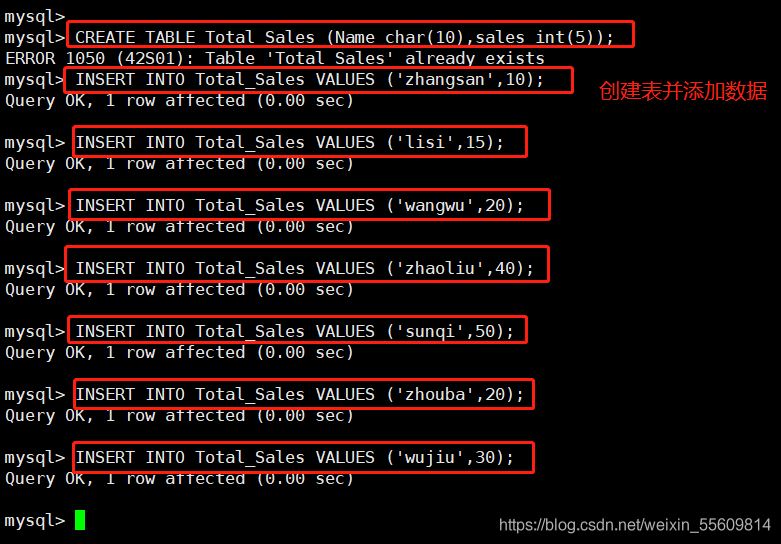
CREATE TABLE Total_Sales (Name char(10),sales int(5));
INSERT INTO Total_Sales VALUES ('zhangsan',10);
INSERT INTO Total_Sales VALUES ('lisi',15);
INSERT INTO Total_Sales VALUES ('wangwu',20);
INSERT INTO Total_Sales VALUES ('zhaoliu',40);
INSERT INTO Total_Sales VALUES ('sunqi',50);
INSERT INTO Total_Sales VALUES ('zhouba',20);
INSERT INTO Total_Sales VALUES ('wujiu',30);

1、算排名
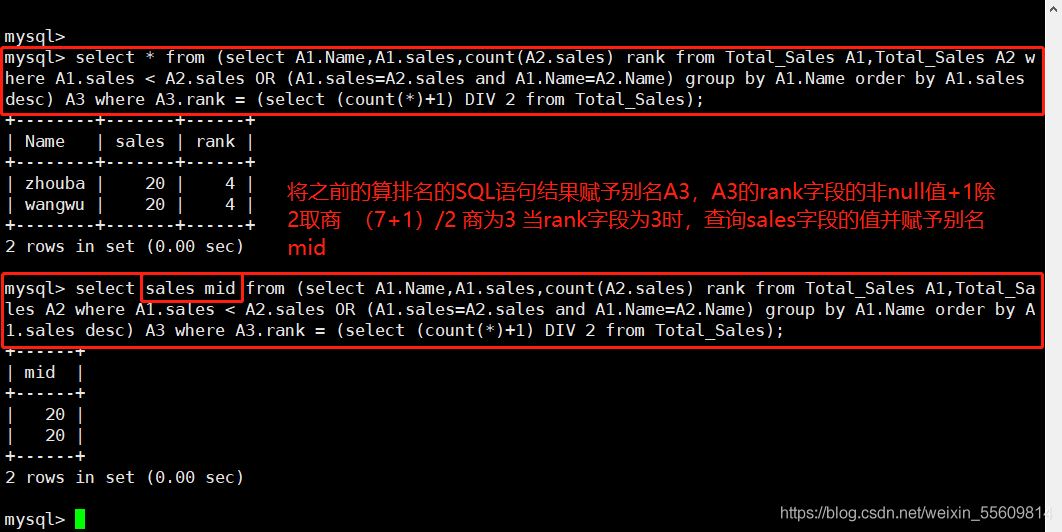
----算排名----表格自我連結(Self Join),然後將結果依序列出,算出每一行之前〈包含那一行本身)有多少行數 SELECT A1.Name, A1.sales,COUNT(A2.sales) Rank FROM Total_sales A1,Total_sales A2 WHERE A1.sales < A2.sales 0R (A1.sales = A2.sales AND A1.Name = A2.Name) GROUP BY A1.Name, A1.sales ORDER BY A1.sales DESC; 例如: select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc; 解釋: 當A1的sales字段值小於A2的sales字段值、或者兩表sales字段值相等並且Name字段值相等時, 從A1和A2表中查詢A1的Name字段值、A1的sales字段值、和A2的sales字段的非空值rank是別名,並為A1的Name字段分組,A1的sales字段降序排序

2、算中位數
---- 算中位數 ---- SELECT Sales Middle FROM (SELECT A1.Name,A1.Sales,COUNT(A2.Sales) Rank FROM Total_Sales A1,Total_Sales A2 WHERE A1.Sales < A2.Sales 0R (A1.Sales = A2.Sales AND A1.Name >= A2.Name) GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales DESC) A3 WHERE A3.Rank = (SELECT (COUNT(*)+1) DIV 2 FROM Total_Sales); 例如: select * from (select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from Total_Sales); select sales mid from (select A1.Name,A1.sales,count(A2.sales) rank from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales OR (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc) A3 where A3.rank = (select (count(*)+1) DIV 2 from Total_Sales); #每個派生表必須有自己的別名,所以別名A3必須要有 #DIV 是在MySQL中算出商的方式
3、算累積總計
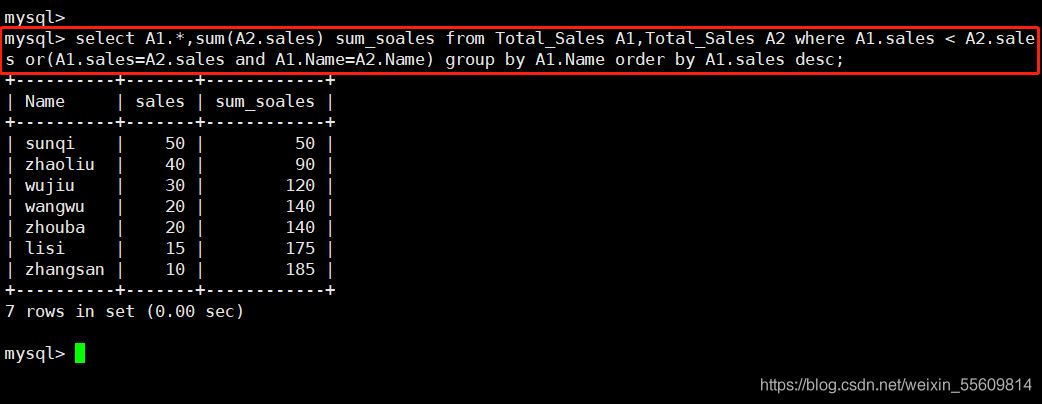
---- 算累積總計 ---- 表格自我連結(Self Join),然後將結果依序列出,算出每一行之前(包含那一行本身)的總合 SELECT A1.Name, A1.Sales, SUM(A2.Sales) Sum_Total FROM Total_Sales A1,Total_Sales A2 WHERE A1.Sales < A2.Sales OR (A1.Sales=A2.Sales AND A1.Name = A2.Name) GROUP BY A1.Name,A1.Sales ORDER BY A1.Sales DESC; 例如: select A1.*,sum(A2.sales) sum_soales from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or(A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;
4、算總合百分比
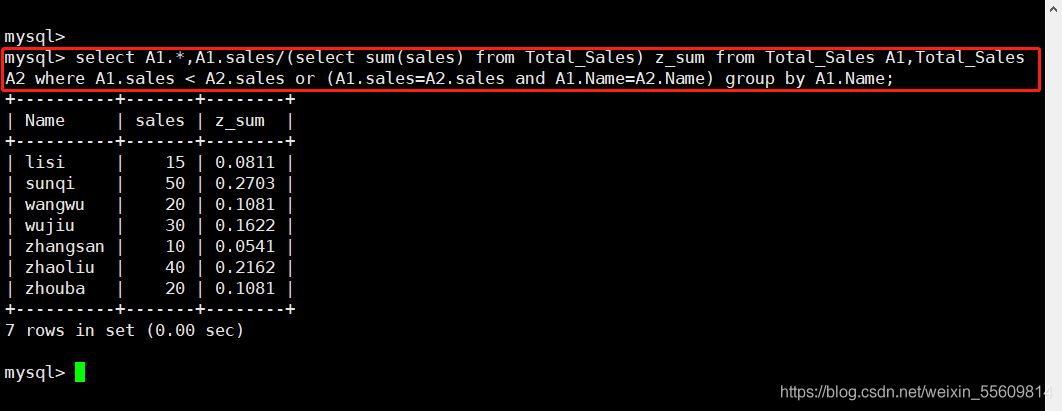
例如: select A1.*,A1.sales/(select sum(sales) from Total_Sales) z_sum from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name; #select sum(sales) from Total_Sales 是為瞭算出字段值總合,然後每一行一一除以總合,算出每行的總合百分比。
5、算累計總合百分比
例如: select A1.Name,A1.sales,sum(A2.sales),sum(A2.sales)/(select sum(sales) from Total_Sales) Z from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc; select A1.Name,A1.sales,sum(A2.sales),TRUNCATE(sum(A2.sales)/(select sum(sales) from Total_Sales),2) ||'%' Z from Total_Sales A1,Total_Sales A2 where A1.sales < A2.sales or (A1.sales=A2.sales and A1.Name=A2.Name) group by A1.Name order by A1.sales desc;

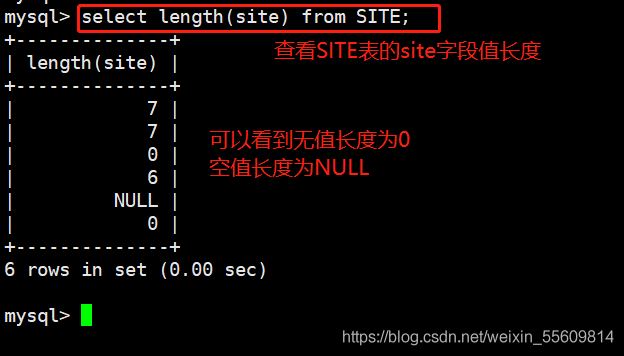
6、空值(null)和無值(’ ‘)的區別
1、無值的長度為0,不占用空間;而空值null 的長度是null,是占用空間的
2、IS NULL或者IS NOT NULL,是用來判斷字段是不是NULL或者不是NULL,是不能查出是不是無值的
3、無值的判斷使用=’‘或者<>”來處理。<>代表不等於
4、在通過count()指定字段統計又多少行數時,如果遇到NULL值會自動忽略掉,遇到空值會自動加入記錄中進行計算
例如:
create table SITE(site varchar(20));
insert into SITE values('nanjing');
insert into SITE values('beijing');
insert into SITE values('');
insert into SITE values('taijin');
insert into SITE values();
insert into SITE values('');
select * from SITE;

select length(site) from SITE; select * from SITE where site is NULL; select * from SITE where site is not NULL; select * from SITE where site =''; select * from SITE where site <> '';
7、正則表達式(與Shell部分一樣)
匹配模式 描述 實例
^ 匹配文本的開始字符 ‘^bd' 匹配以 bd 開頭的字符串
$ 匹配文本的結束字符 ‘qn$' 匹配以 qn 結尾的字符串
. 匹配任何單個字符 ‘s.t' 匹配任何 s 和 t 之間有一個字符的字符串
* 匹配零個或多個在它前面的字符 ‘fo*t' 匹配 t 前面有任意個 o
+ 匹配前面的字符 1 次或多次 ‘hom+' 匹配以 ho 開頭,後面至少一個m 的字符串
字符串 匹配包含指定的字符串 ‘clo' 匹配含有 clo 的字符串
p1|p2 匹配 p1 或 p2 ‘bg|fg' 匹配 bg 或者 fg
[...] 匹配字符集合中的任意一個字符 ‘[abc]' 匹配 a 或者 b 或者 c
[^...] 匹配不在括號中的任何字符 ‘[^ab]' 匹配不包含 a 或者 b 的字符串
{n} 匹配前面的字符串 n 次 ‘g{2}' 匹配含有 2 個 g 的字符串
{n,m} 匹配前面的字符串至少 n 次,至多m 次 ‘f{1,3}' 匹配 f 最少 1 次,最多 3 次
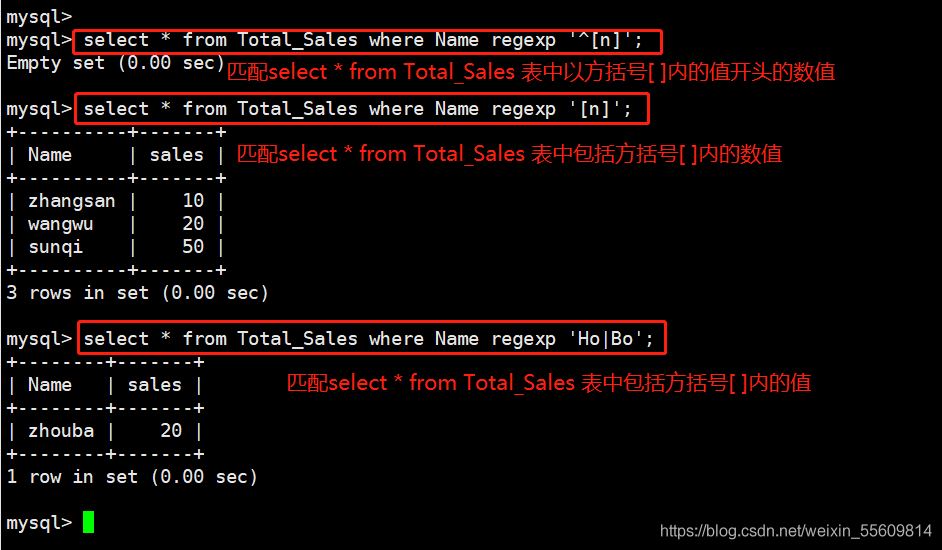
語法:SELECT 字段 FROM 表名 WHERE 字段 REGEXP 匹配模式
例如: select * from Total_Sales where Name regexp '^[n]'; select * from Total_Sales where Name regexp '[n]'; select * from Total_Sales where Name regexp 'Ho|Bo';
8、存儲過程(與Shell函數差不多,代碼的復用) 存儲過程是一組為瞭完成特定功能的SQL語句集合
存儲過程在使用過程中是將常用或者復雜的工作預先使用SQL語句寫好並用一個指定的名稱來進行儲存,這個過程經編譯和優化後存儲在數據庫服務器中,當需要使用該存儲過程時,隻需要調用它即可,存儲過程在執行上比傳統SQL速度更快,執行效率更高。
存儲過程的優點
1、執行一次後,會將生成的二進制代碼駐留緩沖區,提高執行效率
2、SQL語句加上控制語句的集合,靈活性高
3、在服務器端存儲,客戶端調用時,降低網絡負載
4、可多次重復被調用,可隨時修改,不影響客戶端調用
5、可完成所有的數據庫操作,也可控制數據庫的信息訪問權限
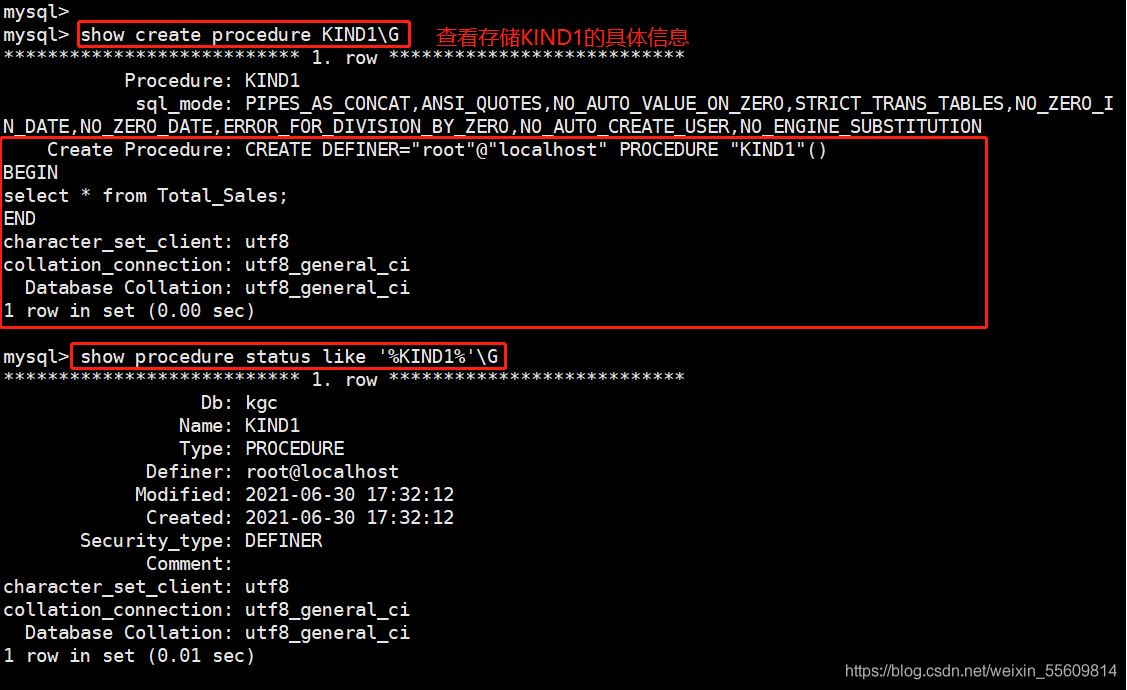
語法: DELIMITER !! #將語句的結束符號從分號;臨時修改,以防出問題,可以自定義 CREATE PROCEDURE XXX() #創建存儲過程,過程名自定義,()可帶參數 BEGIN #過程體以關鍵字BEGIN開始 select * from xxx; #過程體語句 END!! #過程體以關鍵字END結尾 DELIMITER ; #將語句的結束符號恢復為分號 call XXX; #調用存儲過程 ====查看存儲過程==== show create procedure [數據庫.]儲存過程名; #查看某個儲存過程的具體信息 show create procedure XXX; show procedure status [like '%XXX%'] \G
例如: DELIMITER !! CREATE PROCEDURE KIND1() BEGIN select * from Total_Sales; END!! DELIMITER ; CALL KIND1; show create procedure KIND1\G show procedure status like '%KIND1%'\G
存儲過程的參數:
IN 輸入參數,表示調用者向過程傳入值(傳入值可以是字面量或變量)
OUT 輸出參數:表示過程向調用者傳出值(可以返回多個值,傳出值隻能是變量)
例如:
DELIMITER !!
CREATE PROCEDURE KIND2(IN people char(20))
BEGIN
select * from Total_Sales where Name=people;
END!!
DELIMITER ;
CALL KIND2('lisi');

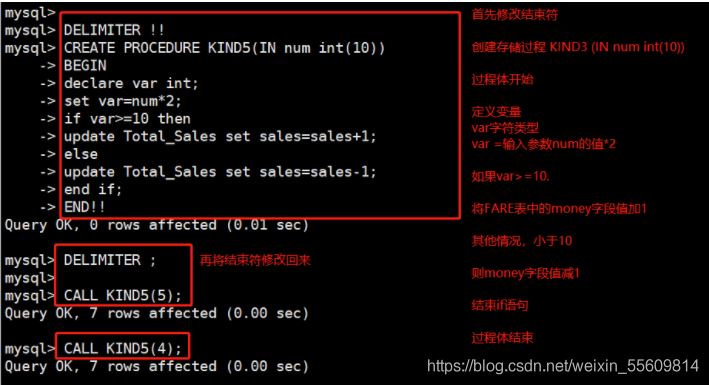
8.1、存儲過程的條件語句
例如: DELIMITER !! CREATE PROCEDURE KIND7(IN num int(10)) BEGIN declare var int; set var=num*2; if var>=10 then update Total_Sales set sales=sales+1; else update Total_Sales set sales=sales-1; end if; END!! DELIMITER ; CALL KIND7(5); CALL KIND7(4);

8.2、循環語句while
例如: create table akg(id int); DELIMITER !! CREATE PROCEDURE KIND6() BEGIN declare var int; set var=0; while var<5 do insert into akg values(var); set var=var+1; end while; END!! DELIMITER ; CALL KIND6; select * from akg;

到此這篇關於MySQL高級SQL語句的文章就介紹到這瞭,更多相關mysql高級sql語句內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!