python實現語音常用度量方法的代碼詳解
語音信號處理一般都要進行主觀評價實驗和客觀評價實驗。
- 主觀評價:邀請測聽者對語音進行測聽,給出主觀意見得分
- 客觀評價:根據算法來衡量語音質量
主觀投票受多種因素影響,如個體受試者的偏好和實驗的語境(其他條件)。一個好的客觀質量度量應該與許多不同的主觀實驗有很高的相關性
信噪比(SNR)
有用信號功率與噪聲功率的比(此處功率為平均功率),也等於幅度比的平方
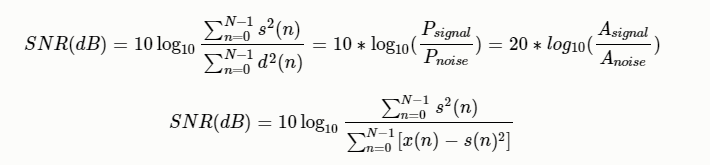
其中:$P_{signal}$為信號功率(平均功率或者實際功率);$P_{noise}$為噪聲功率;$A_{signal}$為信號幅度;$A_{noise}$為噪聲幅度值,功率等於幅度值的平方
MATLAB版本代碼
# 信號與噪聲長度應該一樣 function snr=SNR_singlech(Signal,Noise) P_signal = sum(Signal-mean(Signal)).^2; # 信號的能量 P_noise = sum(Noise-mean(Noise)).^2; # 噪聲的能量 snr = 10 * log10(P_signal/P_noise)
tensorflow版本SNR
def tf_compute_snr(labels, logits):
# labels和logits都是三維數組 (batch_size, wav_data, 1)
signal = tf.reduce_mean(labels ** 2, axis=[1, 2])
noise = tf.reduce_mean((logits - labels) ** 2, axis=[1, 2])
noise = tf.reduce_mean((logits - labels) ** 2 + 1e-6, axis=[1, 2])
snr = 10 * tf.log(signal / noise) / tf.log(10.)
# snr = 10 * tf.log(signal / noise + 1e-8) / tf.log(10.)
snr = tf.reduce_mean(snr, axis=0)
return snr
def Volodymyr_snr(labels, logits):
# labels和logits都是三維數組 (batch_size, wav_data, 1)
noise = tf.sqrt(tf.reduce_mean((logits - labels) ** 2 + 1e-6, axis=[1, 2]))
signal = tf.sqrt(tf.reduce_mean(labels ** 2, axis=[1, 2]))
snr = 20 * tf.log(signal / noise + 1e-8) / tf.log(10.)
avg_snr = tf.reduce_mean(snr, axis=0)
return avg_snr
Volodymyr Kuleshov論文實現方法
批註:這裡的1e-6和1e-8,目的是為瞭防止出現Nan值,如果沒有這個需求可以去除
numpy版本代碼
def numpy_SNR(labels, logits):
# origianl_waveform和target_waveform都是一維數組 (seq_len, )
# np.sum實際功率;np.mean平均功率,二者結果一樣
signal = np.sum(labels ** 2)
noise = np.sum((labels - logits) ** 2)
snr = 10 * np.log10(signal / noise)
return snr
峰值信噪比(PSNR)
表示信號的最大瞬時功率和噪聲功率的比值,最大瞬時功率為語音數據中最大值得平方。
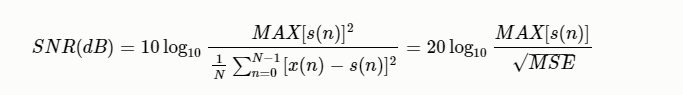
def psnr(label, logits):
MAX = np.max(label) ** 2 # 信號的最大平時功率
MSE = np.mean((label - logits) ** 2)
return np.log10(MAX / MSE)
分段信噪比(SegSNR)
由於語音信號是一種緩慢變化的短時平穩信號,因而在不同時間段上的信噪比也應不一樣。為瞭改善上面的問題,可以采用分段信噪比。分段信噪比即是先對語音進行分幀,然後對每一幀語音求信噪比,最好求均值。
MATLAB版本的代碼
function [segSNR] = Evaluation(clean_speech,enhanced)
N = 25*16000/1000; %length of the segment in terms of samples
M = fix(size(clean_speech,1)/N); %number of segments
segSNR = zeros(size(enhanced));
for i = 1:size(enhanced,1)
for m = 0:M-1
sum1 =0;
sum2 =0;
for n = m*N +1 : m*N+N
sum1 = sum1 +clean_speech(n)^2;
sum2 = sum2 +(enhanced{i}(n) - clean_speech(n))^2;
end
r = 10*log10(sum1/sum2);
if r>55
r = 55;
elseif r < -10
r = -10;
end
segSNR(i) = segSNR(i) +r;
end
segSNR(i) = segSNR(i)/M;
end
python代碼
def SegSNR(ref_wav, in_wav, windowsize, shift):
if len(ref_wav) == len(in_wav):
pass
else:
print('音頻的長度不相等!')
minlenth = min(len(ref_wav), len(in_wav))
ref_wav = ref_wav[: minlenth]
in_wav = in_wav[: minlenth]
# 每幀語音中有重疊部分,除瞭重疊部分都是幀移,overlap=windowsize-shift
# num_frame = (len(ref_wav)-overlap) // shift
# = (len(ref_wav)-windowsize+shift) // shift
num_frame = (len(ref_wav) - windowsize + shift) // shift # 計算幀的數量
SegSNR = np.zeros(num_frame)
# 計算每一幀的信噪比
for i in range(num_frame):
noise_frame_energy = np.sum(ref_wav[i * shift: i * shift + windowsize] ** 2) # 每一幀噪聲的功率
speech_frame_energy = np.sum(in_wav[i * shift: i * shift + windowsize] ** 2) # 每一幀信號的功率
SegSNR[i] = np.log10(speech_frame_energy / noise_frame_energy)
return 10 * np.mean(SegSNR)
信號回聲比 (Signal to echo ratio, SER)
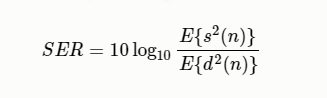
其中E是統計 期望操作,$s(n)$是近端語音,$d(n)$是遠端回聲
def SER(near_speech, far_echo):
"""signal to echo ratio, 信號回聲比
:param near_speech: 近端語音
:param far_echo: 遠端回聲
"""
return 10*np.log10(np.mean(near_speech**2)/np.mean(far_echo**2))
回聲損失增強 (Echo Return Loss Enhancement, ERLE)
回波損失增強度量(ERLE)通常用於評估系統在沒有近端信號的單通話情況下 的回聲減少。ERLE的定義是
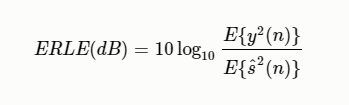
其中E是統計 期望操作,$y(n)$是麥克風信號,$\hat{s}(n)$是估計的近端語音信號。
def compute_ERLE(mic_wav, predict_near_end_wav):
"""
:param mic_wav: 麥克風信號(y) = 近端語音(s) + 遠端語音回聲(s) + 噪聲(v)
:param predict_near_end_wav: 估計的近端語音信號 \hat{s}
麥克風信號
"""
mic_mear = np.mean(mic_wav**2)
predict_near_end_wav = np.mean(predict_near_end_wav**2)
ERLE = 10 * np.log10(mic_mear/predict_near_end_wav)
return ERLE
為瞭評估系統在雙講情況下的性能,通常采用PESQ(語音質量感知評價)或STOI (短時語音可懂度),他是通過將估計的近端語音和僅在雙講通話期間真實的近端語音進行比較得到的。PESQ評分范圍為-0.5 ~ 4.5,分數越高質量越好。STOI評分范圍為0~1,分數越高越好。
對數擬然對比度 (log Likelihood Ratio Measure)
坂倉距離測度是通過語音信號的線性預測分析來實現的。ISD基於兩組線性預測參數(分別從原純凈語音和處理過的語音的同步幀得到)之間的差異。LLR可以看成一種坂倉距離(Itakura Distance,IS)但是IS距離需要考慮模型增益。而LLR不需要考慮模型爭議引起的幅度位移,更重視整體譜包絡的相似度。
語音質量感知評估 (Perceptual Evaluation of Speech Quality, PESQ)
引言:我先做個簡要介紹,再講使用。使用之前建議還是詳細瞭解一下,不要用錯瞭,導致論文被拒,或者做瞭偽研究,以下內容是我挑重點摘自ITU-T P862建議書,比較權威,重要的地方我會加粗。想要進一步瞭解的自行去下載原文。
PESQ是由國際電信聯盟(International Telecommunication Union,ITU) 2001年提供的ITU-T P862建議書:語音質量的感知評估(PESQ):窄帶電話網絡和語音編解碼器的端到端語音質量評估的客觀方法,並提供瞭ANSI-C語言實現代碼。真實系統可能包括濾波和可變延遲,以及由於信道誤差和低比特率編解碼器引起的失真。國際電聯電信政策861中描述的PSQM方法僅被推薦用於評估語音編解碼器,不能適當考慮濾波、可變延遲和短時局部失真。PESQ通過傳遞函數均衡、時間校準和一種新的時間平均失真算法來解決這些影響。PESQ的驗證包括許多實驗,這些實驗專門測試瞭它在濾波、可變延遲、編碼失真和信道誤差等因素組合下的性能。
建議將PESQ用於3.1kHz(窄帶)手機電話和窄帶語音編解碼器的語音質量評估。PESQ是屬於客觀評價,和主觀分數之間的相關性約為0.935,但PESQ算法不能用來代替主觀測試。
PESQ算法沒有提供傳輸質量的綜合評估。它隻測量單向語音失真和噪聲對語音質量的影響。響度損失、延遲、側音、回聲和其他與雙向互動相關的損傷(如中央削波器)的影響不會反映在PESQ分數中。因此,有可能有很高的PESQ分數,但整體連接質量很差。
PESQ的感知模型用於計算原始信號$X(t)$與退化信號$Y(t)$之間的距離(PESQ分數),退化信號$Y(t)$是$X(t)$通過通信系統的結果。PESQ的輸出是對受試者在主觀聽力測試中給予$Y(t)$的感知質量的預測。取值在-0.5到4.5的范圍內,得分越高表示語音質量越好,盡管在大多數情況下輸出范圍在1.0到4.5之間。

ITU提供瞭C語言代碼,下載請點擊這裡,但是在使用之前我們需要先編譯C腳本,生成可執行文件exe
編譯方式為:在命令行進入下載好的文件
- cd\Software\source
- gcc -o PESQ *.c
經過編譯,會在當前文件夾生成一個pesq.exe的可執行文件
使用方式為:
- 命令行進入pesq.exe所在的文件夾
- 執行命令:pesq 采樣率 “原始文件路徑名” “退化文件路徑名”,采樣率必須選擇+8000(窄帶)或+16000(寬帶),
- 回車
- 等待結果即可,值越大,質量越好。
例如:pesq +16000 raw.wav processed.wav
python代碼實現
參考地址:https://github.com/ludlows/python-pesq
首先我們需要安裝pesq庫:pip install pesq
from scipy.io import wavfile
from pesq import pesq
rate, ref = wavfile.read("./audio/speech.wav")
rate, deg = wavfile.read("./audio/speech_bab_0dB.wav")
print(pesq(rate, ref, deg, 'wb'))
print(pesq(rate, ref, deg, 'nb'))
該python庫返回的是MOS-LQO,屬於pesq的映射,現在用的更多的也是MOS-LQO。如果你硬是想要PESQ得分,你可以自行逆變換回去,公式見下一節
MOS-LQO
MOS-LQO (Mean Opinion Score – Listening Quality Objective),使用客觀測量技術評估主觀聽力質量)與之相對的還有MOS-LQS(Mean Opinion Score – Listening Quality Subjective),使用樣本的主觀評分直接衡量聽力質量,就是主觀評價瞭。
功能:將P.862原始結果分數轉換為MOS-LQO的映射,P862.1:用於將P.862原始結果分數轉換為MOS-LQO的映射函數.pdf
ITU-TP.862建議書提供的原始分數在-0.5到4.5之間。希望從PESQ (P.862)得分中轉換為MOS-LQO (P.862.1)分數,從而可以與MOS進行線性比較。該建議書介紹瞭從原始P.862得分到MOS-LQO(P.800.1)的映射函數及其性能。映射函數已在代表不同應用程序和語言的大量主觀數據上進行瞭優化,所呈現的性能優於原始的PESQ(P862),取值在[1, 4.5]之間,連續的。公式為:
$$公式1:y=0.999+\frac{4.999-0.999}{1+e^{-1.4945x+4.6607}}$$

python實現
def pesq2mos(pesq):
""" 將PESQ值[-0.5, 4.5]映射到MOS-LQO得分[1, 4.5]上,映射函數來源於:P.862.1 """
return 0.999 + (4.999 - 0.999) / (1 + np.exp(-1.4945 * pesq + 4.6607))
MATLAB官方實現請參見:
- v_pesq2mos.m
- pesq2mos.m
公式2給出瞭從MOS-LQO分數到PESQ分數的轉換的反映射函數

python實現
def mos2pesq(mos):
""" 將MOS-LQO得分[1, 4.5]映射到PESQ值[-0.5, 4.5]上,映射函數來源於:P.862.1"""
inlog = (4.999 - mos) / (mos - 0.999)
return (4.6607 - np.log(inlog)) / 1.4945
需要註意的是,所提供的函數有一些實際限制:
- 本文提供的映射函數對源自所有類型應用程序的數據庫進行瞭優化。僅針對特定應用程序或語言進行優化的其他映射函數可能在該特定應用程序或語言上比提供的函數執行得更好。
- 雖然訓練數據庫包含分數較低的MOS區域中的樣本比例很大,但是在原始P.862分數0.5到1的范圍內缺少樣本。在此范圍內,映射的P.862函數進行插值,因此確定瞭預測誤差Ep和平均殘差Em
PESQ-WB
2007年11.13國際電聯公佈瞭PESQ的寬帶版本(ITU-T P862.2,PESQ-WB),P.862建議書的寬帶擴展,用於評估寬帶電話網絡和語音編解碼器,主要用於寬帶音頻系統 (50-7000 Hz),盡管它也可以應用於帶寬較窄的系統。例如聽眾使用寬帶耳機的語音編解碼器。相比之下,ITU-T P.862建議書假設使用標準的IRS型窄帶電話手機,在300 Hz以下和3100 Hz以上會強烈衰減。
使用范圍
- 不建議將PESQ-WB用在信號插入點和信號捕獲點之間包含噪聲抑制算法的系統。 另外,應使用幹凈的語音樣本,因為嘈雜的語音樣本,即那些信噪比較差的語音樣本,可能會導致預測錯誤。 用戶還應註意,寬帶語音主觀實驗中不同失真類別的相對排名可能會隨語言種類而略有變化。 特別要註意的是,寬帶擴展可能會高估ITU-T Rec.3建議書的MOS分數。
- 當使用PESQ-WB來比較可能對音頻信號進行頻帶限制的系統的性能時,建議使用一個寬帶(50-7000 Hz音頻帶寬)版本的信號作為所有參考信號。被限制帶寬的測試系統會導致語音性能下降,降低輸出分數。這種限制可能會降低信號的預測精度。不建議存在信號退化的嚴重限制,即小於傳統電話帶寬(300- 3400hz) 。
- PESQ-WB是評估寬帶語音條件的主觀實驗的背景下預測主觀意見,即音頻帶寬從50赫茲擴展到7000赫茲的信號。這意味著,由於不同的實驗環境,無法直接比較寬帶擴展產生的分數和基線[ITU-T P862]或[ITU-T P862.1]產生的分數。
基本的P.862模型提供的原始分數在–0.5到4.5之間。 [ITU-T P.862]的PESQ-WB包括一個映射函數,輸出的也是映射值,該函數允許與主觀評價的MOS得分進行線性比較,這些主觀實驗包括音頻帶寬為50-7000 Hz的寬帶語音條件。 這意味著由於實驗環境的不同,無法直接比較PESQ-WB產生的分數和基線[ITU-T P.862]或[ITU-T P.862.1]產生的分數。PESQ-WB中使用的輸出映射函數定義如下:
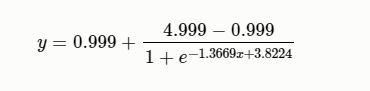
其中$x$是原模型輸出。
[ITU-T P.862]的附件A中給出瞭瞭PESQ-WB的寬帶擴展的ANSI-C參考實現。
感知客觀語音質量評估 (POLQA)
POLQA度量方法授權給瞭epticom公司,隻有該公司授權的機構才能使用,我總結在這就是讓大傢瞭解一下,反正我們都用不瞭,哈哈
ITU P.863建議書提供瞭一種客觀評價方法:感知客觀語音質量評估 (Perceptual objective listening quality prediction, P.OLQA),ITU-T P.863建議書支持兩種操作模式,一種用於窄帶 (NB, 300Hz-3.4kHz),一種用於全帶 (FB, 20Hz-20kHz)。
可以應用到全頻帶語音編解碼器(例如,OPUS,增強語音服務(EVS))。比較參考信號X(t)和退化信號Y(t),其中Y(t)是通過通信系統傳遞X(t)的結果,人類聽覺系統中音頻信號的心理物理表征,
ITU-T P.863算法消除瞭參考信號中的低水平噪聲,同時對退化輸出信號中的噪聲也進行瞭部分抑制。
一個好的客觀質量測量應該與多個不同的主觀實驗有很高的相關性。在實踐中,使用ITU-T P.863算法,回歸映射通常幾乎是線性的,在日常實踐中,不需要對客觀分數進行特殊映射,因為ITU-T P.863分數已經映射到MOS尺度,反映瞭大量單獨數據集的平均值。
POLQA結果主要是模型平均意見得分(MOS),涵蓋從1(差)到5(優秀)的范圍。在全頻帶模式下得分為MOS-LQO 4.80,在窄帶模式下得分為MOS-LQO 4.5。這反映瞭一個事實,即不是所有的主觀測試參與者都會給最高的評級,即使是不降級的參考。

對數譜距離(LSD)
對數譜距離Log Spectral Distance,LSD是兩個頻譜之間的距離度量。也稱為“對數譜失真”

式中,$l$和$m$分別為頻率索引和幀索引,$M$為語音幀數,$L$為頻點數,$\hat{S}(l, m)$和$S(l, m)$分別為估計音頻和寬帶音頻經過短時短時傅裡葉變換後的頻譜。
numpy版本
# 方法一
def numpy_LSD(labels, logits):
""" labels 和 logits 是一維數據 (seq_len,)"""
labels_spectrogram = librosa.stft(labels, n_fft=2048) # (1 + n_fft/2, n_frames)
logits_spectrogram = librosa.stft(logits, n_fft=2048) # (1 + n_fft/2, n_frames)
labels_log = np.log10(np.abs(labels_spectrogram) ** 2)
logits_log = np.log10(np.abs(logits_spectrogram) ** 2)
# 先處理頻率維度
lsd = np.mean(np.sqrt(np.mean((labels_log - logits_log) ** 2, axis=0)))
return lsd
# 方法二
def get_power(x):
S = librosa.stft(x, n_fft=2048) # (1 + n_fft/2, n_frames)
S = np.log10(np.abs(S) ** 2)
return S
def compute_log_distortion(labels, logits):
"""labels和logits數據維度為 (batch_size, seq_len, 1)"""
avg_lsd = 0
batch_size = labels.shape[0]
for i in range(batch_size):
S1 = get_power(labels[i].flatten())
S2 = get_power(logits[i].flatten())
# 先處理頻率軸,後處理時間軸
lsd = np.mean(np.sqrt(np.mean((S1 - S2) ** 2, axis=0)), axis=0)
avg_lsd += lsd
return avg_lsd / batch_size
tensorflow版本
def get_power(x):
x = tf.squeeze(x, axis=2) # 去掉位置索引為2維數為1的維度 (batch_size, input_size)
S = tf.signal.stft(x, frame_length=2048, frame_step=512, fft_length=2048,
window_fn=tf.signal.hann_window)
# [..., frames, fft_unique_bins]
S = tf.log(tf.abs(S) ** 2) / tf.log(10.)
# S = tf.log(tf.abs(S) ** 2 + 9.677e-9) / tf.log(10.)
return S
def tf_compute_log_distortion(labels, logits):
"""labels和logits都是三維數組 (batch_size, input_size, 1)"""
S1 = get_power(labels) # [..., frames, fft_unique_bins]
S2 = get_power(logits) # [..., frames, fft_unique_bins]
# 先處理頻率維度,後處理時間維度
lsd = tf.reduce_mean(tf.sqrt(tf.reduce_mean((S1 - S2) ** 2, axis=2)), axis=1)
lsd = tf.reduce_mean(lsd, axis=0)
return lsd
但如果想要numpy版本的值和tensorflow版本的值一樣,可以使用下面的代碼
# numpy版本一:處理一個batch,(batch, seq_len, 1)
def numpy_LSD(labels, logits):
""" labels 和 logits 是一維數據"""
labels_spectrogram = librosa.stft(labels, n_fft=2048, hop_length=512, win_length=2048,
window="hann", center=False) # (1 + n_fft/2, n_frames)
logits_spectrogram = librosa.stft(logits, n_fft=2048, hop_length=512, win_length=2048,
window="hann", center=False) # (1 + n_fft/2, n_frames)
labels_log = np.log10(np.abs(labels_spectrogram) ** 2 + 1e-8)
logits_log = np.log10(np.abs(logits_spectrogram) ** 2 + 1e-8)
original_target_squared = (labels_log - logits_log) ** 2
lsd = np.mean(np.sqrt(np.mean(original_target_squared, axis=0)))
return lsd
# numpy版本二:處理一個batch,(batch, seq_len, 1)
def get_power1(x):
S = librosa.stft(x, n_fft=2048, hop_length=512, win_length=2048,
window="hann", center=False) # (1 + n_fft/2, n_frames)
S = np.log10(np.abs(S) ** 2 + 1e-8)
return S
def compute_log_distortion(labels, logits):
avg_lsd = 0
batch_size = labels.shape[0]
for i in range(batch_size):
S1 = get_power1(labels[i].flatten())
S2 = get_power1(logits[i].flatten())
# 先處理頻率軸,後處理時間軸
lsd = np.mean(np.sqrt(np.mean((S1 - S2) ** 2, axis=0)), axis=0)
avg_lsd += lsd
return avg_lsd / batch_size
# tensorflow版本
def get_power(x):
x = tf.squeeze(x, axis=2) # 去掉位置索引為2維數為1的維度 (batch_size, input_size)
S = tf.signal.stft(x, frame_length=2048, frame_step=512, fft_length=2048,
window_fn=tf.signal.hann_window)
# [..., frames, fft_unique_bins]
S = tf.log(tf.abs(S) ** 2 + 9.677e-9) / tf.log(10.)
return S
def tf_compute_log_distortion(labels, logits):
# labels和logits都是三維數組 (batch_size, input_size, 1)
S1 = get_power(labels) # [..., frames, fft_unique_bins]
S2 = get_power(logits) # [..., frames, fft_unique_bins]
# 先處理頻率維度,後處理時間維度
lsd = tf.reduce_mean(tf.sqrt(tf.reduce_mean((S1 - S2) ** 2, axis=2)), axis=1)
lsd = tf.reduce_mean(lsd, axis=0)
return lsd
批註:librosa.stft中center設為False,和np.log10中加1e-8,目的是為瞭最終的值和tensorflow版本的lsd值相近,如果沒有這個需求可以去除。這裡tf.log中加9.677e-9是為瞭和numpy中的值相近,如果沒有這個需求可以去除
短時客觀可懂度(STOI)
下載一個 pystoi 庫:pip install pystoi
STOI 反映人類的聽覺感知系統對語音可懂度的客觀評價,STOI 值介於0~1 之間,值越大代表語音可懂度越高,越清晰。
from pystoi import stoi stoi_score = stoi(label, logits, fs_sig=16000)
加權譜傾斜測度(WSS)
WSS值越小說明扭曲越少,越小越好,范圍

參考
【CSDN文章】PESQ語音質量測試
視頻質量度量指標
度量方法倉庫
【github代碼,內涵多種度量方法】pysepm
【python庫】python-pesq
【python庫】pystoi
speechmetrics
Voice quality metrics
以上就是python實現語音常用度量方法的詳細內容,更多關於python語音度量方法的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- 分析語音數據增強及python實現
- Python實現希爾伯特變換(Hilbert transform)的示例代碼
- python PaddleSpeech實現嬰兒啼哭識別
- Python產生batch數據的操作
- 我對PyTorch dataloader裡的shuffle=True的理解