oracle索引的測試實例代碼
前言
在測試oracle索引性能時大意瞭,沒有仔細分析數據特點,將情況特此記錄下來。
需求: 對一張100w記錄的表的 stuname列進行查詢,測試在建立索引與不建立索引的區別. 以下是開始用的創建代碼及執行效果.
1. 隨機數據生成代碼分析
--為測試索引而準備的隨機數據生成代碼,先分析一下
select rownum as id,
'smith'||trunc(dbms_random.value(0, 100)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 100;
–先分析以下上面的代碼
— 偽列: rownum
— dual : 測試表
— || 字符串聯接
–1. 測試生成100條記錄 connect by level<=100 :
–a、利用Oracle特有的“connect by”樹形連接語法生成測試記錄,“level <= 100”表示要生成100記錄;
–b、利用rownum虛擬列生成遞增的整數數據;
–c、利用sysdate函數加一些簡單運算來生成日期數據,本例中是每條記錄的時間加1秒;
— add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) 用當前時間 減去 至少100個月,最多200個月,來生成生日
–d、利用dbms_random.value函數生成隨機的數值型數據,都是double型,所以都加瞭 trunc( )以截斷小數位,本例中是生成0到100之間的隨機整數;
–e、利用dbms_random.string函數生成隨機的字符型數據,本例中是生成長度為20的隨機字符串,字符串中可以包括字符或數字。
2. 生成測試表及數據
--2. 正式生成100W
drop table stu_test_100w; --如果原來有,則先刪除原來的表
--創建表及數據
create table stu_test_100w
as
select rownum as id,
'smith'||trunc(dbms_random.value(0, 99)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 1000000; -- 生成 100w測試數據
-- 查看當前用戶模式下所有的表 select * from tab where tname='STU_TEST_100W'; --先執行一次查詢, 註意查詢所用的時間,此時並沒有加入索引 select * from stu_test_100w where stu_name='smith13';
執行結果:
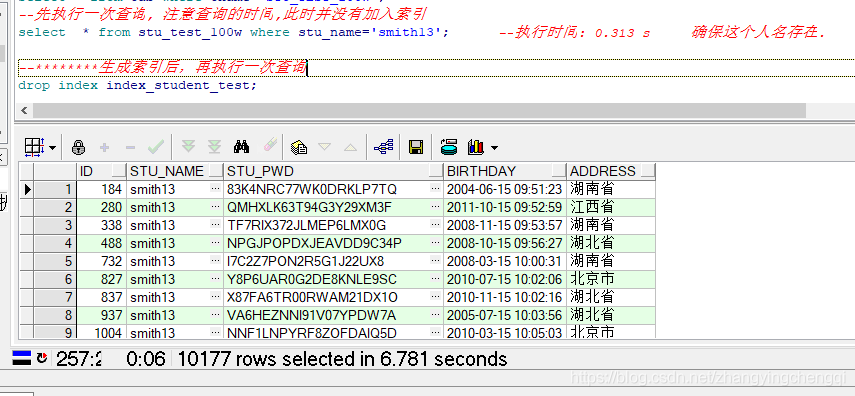
以上是沒有用到索引時的執行用時 6.781秒.
下面創建索引後,再用同一查詢來測試.
--********生成索引後,再執行一次查詢 drop index index_student_test; create index index_student_test on stu_test_100w(stu_name); --索引是針對某個表的某個列 --先執行一次查詢, 註意查詢的時間,此時加入瞭索引 select * from stu_test_100w where stu_name='smith13';
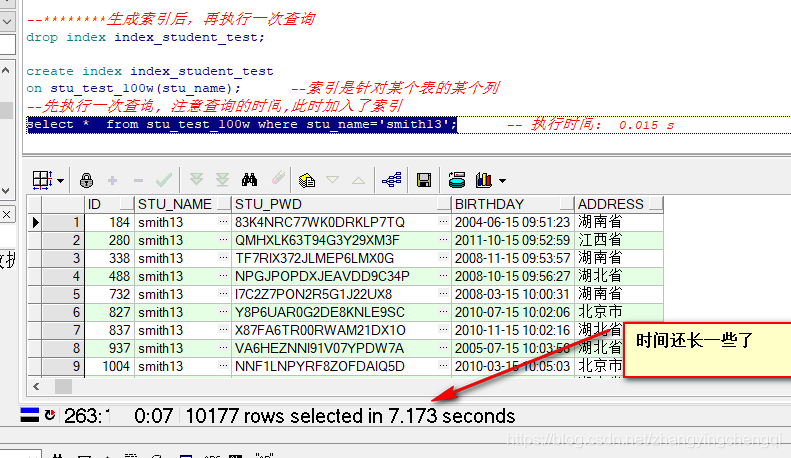
為什麼用瞭索引後時間查詢能還下降瞭呢????
分析如下:
1. 索引生成的字段的值分存得太密集瞭,查看上面的代碼會發現我們stu_name隻生成在瞭 smith0-99之間,即隻有100種可能性, 對於100w數據則言,即每個名字都有約1w個.
2。 因為數據太密集瞭,所以以上查詢的花的時間主要在1w條數據的顯示上, 所以我們可以觀察到不管是否用到瞭索引,都要共到6-7秒來顯示結果.
3. 那為什麼用瞭索引還慢一些呢? 這就與索引的存儲結構有關系瞭.oracle默認使用的是B樹索引, 當使用索引列查詢時,查詢必須先查看索引,通過索引去定位數據,而咱們的數據分佈又比較密集,所以使用索引所導致的時間損耗要大於直接磁盤搜索的時間.
那麼如何解決呢?
隨機生成的姓名分佈廣一些(這與真實的數據也一樣). 即將隨機生成代碼修改為 ‘smith’||trunc(dbms_random.value(0, 9999999)) as stu_name,
drop table stu_test_100w; --如果原來有,則先刪除原來的表
--重新生成表及隨機數據,註意 stu_name列的取值范圍加大
create table stu_test_100w
as
select rownum as id,
'smith'||trunc(dbms_random.value(0, 9999999)) as stu_name,
dbms_random.string('x', 20) stu_pwd,
to_char(add_months(sysdate,-DBMS_RANDOM.VALUE(100,200)) + rownum / 24 / 3600, 'yyyy-mm-dd hh24:mi:ss') as birthday ,
decode( TRUNC(DBMS_RANDOM.VALUE(1,5)),1,'湖南省',2,'湖北省',3,'江西省','北京市') as address
from dual
connect by level <= 1000000;
--先執行一次查詢, 註意查詢的時間,此時並沒有加入索引
select * from stu_test_100w where stu_name='smith8821228';
執行結果如下:

用時 0.312秒.
接著創建索引後,再測試同一個查詢
--********生成索引後,再執行一次查詢 drop index index_student_test; create index index_student_test on stu_test_100w(stu_name); --索引是針對某個表的某個列 --先執行一次查詢, 註意查詢的時間,此時加入瞭索引 select * from stu_test_100w where stu_name='smith8821228';

使用索引後,同一個查詢隻需0.015秒,在原來用時0.312的基礎下,下降瞭n倍.
總結
到此這篇關於oracle索引測試的文章就介紹到這瞭,更多相關oracle索引測試內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Oracle之TO_DATE用法詳解
- Oracle生成隨機數字、字符串、日期、驗證碼及 UUID的方法
- Oracle根據時間查詢的一些常見情況匯總
- Oracle 生成未來三天的整點時間(步驟詳解)
- orcale中的to_number方法使用