pytorch 實現多個Dataloader同時訓練
看代碼吧~
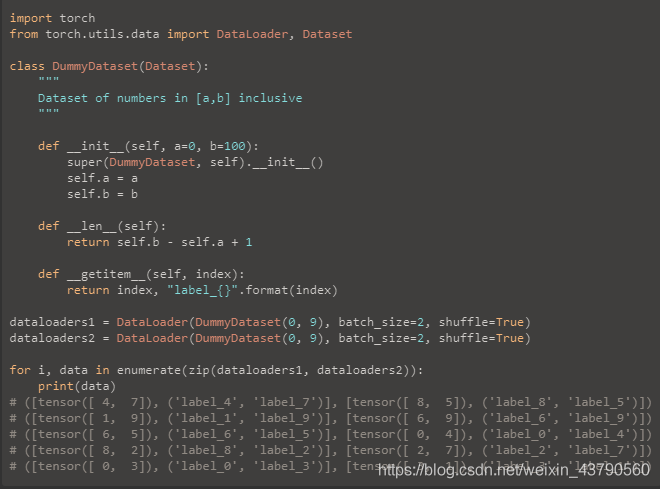
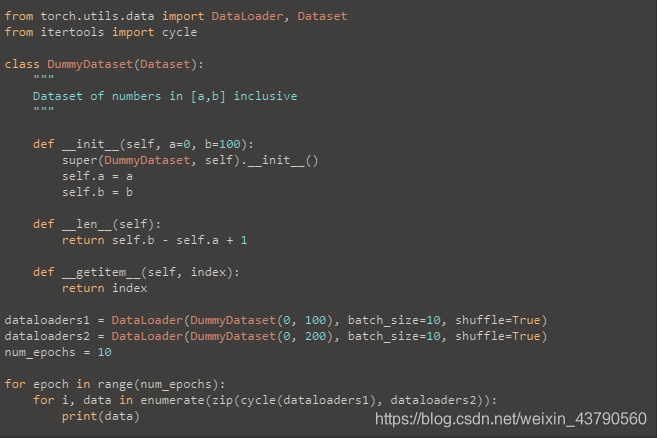
如果兩個dataloader的長度不一樣,那就加個:
from itertools import cycle
僅使用zip,迭代器將在長度等於最小數據集的長度時耗盡。 但是,使用cycle時,我們將再次重復最小的數據集,除非迭代器查看最大數據集中的所有樣本。
補充:pytorch技巧:自定義數據集 torch.utils.data.DataLoader 及Dataset的使用
本博客中有可直接運行的例子,便於直觀的理解,在torch環境中運行即可。
1. 數據傳遞機制
在 pytorch 中數據傳遞按一下順序:
1、創建 datasets ,也就是所需要讀取的數據集。
2、把 datasets 傳入DataLoader。
3、DataLoader迭代產生訓練數據提供給模型。
2. torch.utils.data.Dataset
Pytorch提供兩種數據集:
Map式數據集 Iterable式數據集。其中Map式數據集繼承torch.utils.data.Dataset,Iterable式數據集繼承torch.utils.data.IterableDataset。
本文隻介紹 Map式數據集。
一個Map式的數據集必須要重寫 __getitem__(self, index)、 __len__(self) 兩個方法,用來表示從索引到樣本的映射(Map)。 __getitem__(self, index)按索引映射到對應的數據, __len__(self)則會返回這個數據集的長度。
基本格式如下:
import torch.utils.data as data
class VOCDetection(data.Dataset):
'''
必須繼承data.Dataset類
'''
def __init__(self):
'''
在這裡進行初始化,一般是初始化文件路徑或文件列表
'''
pass
def __getitem__(self, index):
'''
1. 按照index,讀取文件中對應的數據 (讀取一個數據!!!!我們常讀取的數據是圖片,一般我們送入模型的數據成批的,但在這裡隻是讀取一張圖片,成批後面會說到)
2. 對讀取到的數據進行數據增強 (數據增強是深度學習中經常用到的,可以提高模型的泛化能力)
3. 返回數據對 (一般我們要返回 圖片,對應的標簽) 在這裡因為我沒有寫完整的代碼,返回值用 0 代替
'''
return 0
def __len__(self):
'''
返回數據集的長度
'''
return 0
可直接運行的例子:
import torch.utils.data as data
import numpy as np
x = np.array(range(80)).reshape(8, 10) # 模擬輸入, 8個樣本,每個樣本長度為10
y = np.array(range(8)) # 模擬對應樣本的標簽, 8個標簽
class Mydataset(data.Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
self.idx = list()
for item in x:
self.idx.append(item)
pass
def __getitem__(self, index):
input_data = self.idx[index] #可繼續進行數據增強,這裡沒有進行數據增強操作
target = self.y[index]
return input_data, target
def __len__(self):
return len(self.idx)
datasets = Mydataset(x, y) # 初始化
print(datasets.__len__()) # 調用__len__() 返回數據的長度
for i in range(len(y)):
input_data, target = datasets.__getitem__(i) # 調用__getitem__(index) 返回讀取的數據對
print('input_data%d =' % i, input_data)
print('target%d = ' % i, target)
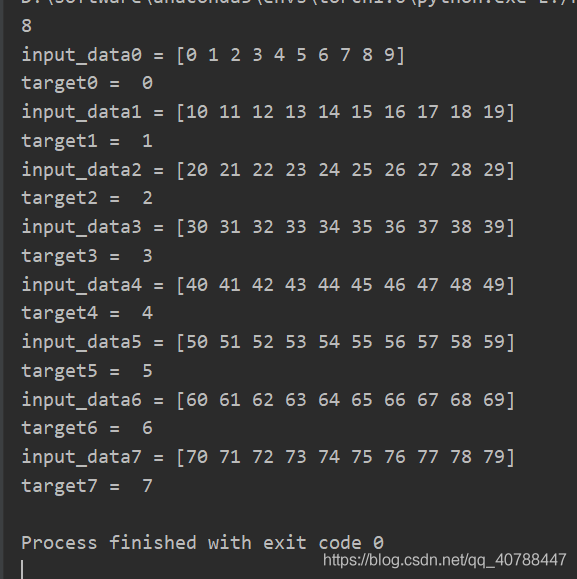
結果如下:
3. torch.utils.data.DataLoader
PyTorch中數據讀取的一個重要接口是 torch.utils.data.DataLoader。
該接口主要用來將自定義的數據讀取接口的輸出或者PyTorch已有的數據讀取接口的輸入按照batch_size封裝成Tensor,後續隻需要再包裝成Variable即可作為模型的輸入。
torch.utils.data.DataLoader(onject)的可用參數如下:
1.dataset(Dataset): 數據讀取接口,該輸出是torch.utils.data.Dataset類的對象(或者繼承自該類的自定義類的對象)。
2.batch_size (int, optional): 批訓練數據量的大小,根據具體情況設置即可。一般為2的N次方(默認:1)
3.shuffle (bool, optional):是否打亂數據,一般在訓練數據中會采用。(默認:False)
4.sampler (Sampler, optional):從數據集中提取樣本的策略。如果指定,“shuffle”必須為false。我沒有用過,不太瞭解。
5.batch_sampler (Sampler, optional):和batch_size、shuffle等參數互斥,一般用默認。
6.num_workers:這個參數必須大於等於0,為0時默認使用主線程讀取數據,其他大於0的數表示通過多個進程來讀取數據,可以加快數據讀取速度,一般設置為2的N次方,且小於batch_size(默認:0)
7.collate_fn (callable, optional): 合並樣本清單以形成小批量。用來處理不同情況下的輸入dataset的封裝。
8.pin_memory (bool, optional):如果設置為True,那麼data loader將會在返回它們之前,將tensors拷貝到CUDA中的固定內存中.
9.drop_last (bool, optional): 如果數據集大小不能被批大小整除,則設置為“true”以除去最後一個未完成的批。如果“false”那麼最後一批將更小。(默認:false)
10.timeout(numeric, optional):設置數據讀取時間限制,超過這個時間還沒讀取到數據的話就會報錯。(默認:0)
11.worker_init_fn (callable, optional): 每個worker初始化函數(默認:None)
可直接運行的例子:
import torch.utils.data as data
import numpy as np
x = np.array(range(80)).reshape(8, 10) # 模擬輸入, 8個樣本,每個樣本長度為10
y = np.array(range(8)) # 模擬對應樣本的標簽, 8個標簽
class Mydataset(data.Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
self.idx = list()
for item in x:
self.idx.append(item)
pass
def __getitem__(self, index):
input_data = self.idx[index]
target = self.y[index]
return input_data, target
def __len__(self):
return len(self.idx)
if __name__ ==('__main__'):
datasets = Mydataset(x, y) # 初始化
dataloader = data.DataLoader(datasets, batch_size=4, num_workers=2)
for i, (input_data, target) in enumerate(dataloader):
print('input_data%d' % i, input_data)
print('target%d' % i, target)
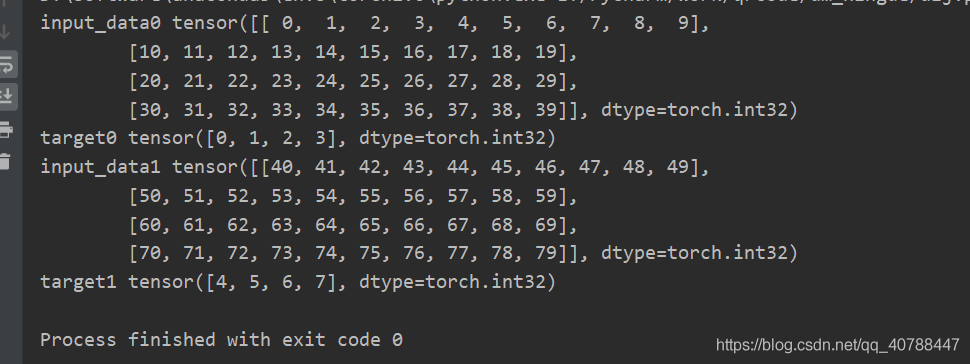
結果如下:(註意看類別,DataLoader把數據封裝為Tensor)
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。
推薦閱讀:
- Pytorch數據讀取之Dataset和DataLoader知識總結
- Pytorch數據讀取與預處理該如何實現
- 解決Pytorch dataloader時報錯每個tensor維度不一樣的問題
- Pytorch如何加載自己的數據集(使用DataLoader讀取Dataset)
- 我對PyTorch dataloader裡的shuffle=True的理解