pg中replace和translate的用法說明(數據少的中文排序)
1.首先創建students表
CREATE TABLE students ( id integer NOT NULL, name character varying(255), sex character varying(255), class character varying(255), "like" character varying(255), school character varying(255), phone character varying(255) )
2.插入數據
INSERT INTO "public"."students" ("id", "name", "sex", "class", "like", "school", "phone")
VALUES ('1', '大貓', '女', '一年級', '繪畫', '第三小學', '2345');
INSERT INTO "public"."students" ("id", "name", "sex", "class", "like", "school", "phone")
VALUES ('2', '小厭', '男', '三年級', '書法', '第四小學', '2346');
INSERT INTO "public"."students" ("id", "name", "sex", "class", "like", "school", "phone")
VALUES ('3', '庫庫', '女', '二年級', '繪畫', '第三小學', '2342');
INSERT INTO "public"."students" ("id", "name", "sex", "class", "like", "school", "phone")
VALUES ('4', '艾琳', '女', '四年級', '書法,鋼琴', '第四小學', '2349');
結果:
select * from students
如下圖:

3.replace 的用法
replace(string text, from text, to text)
返回類型:text
解釋:把字串string裡出現地所有子字串from替換成子字串to
示例1:
select replace('一條黑色的狗','黑','黑白相間')
結果:一條黑色的狗 變成瞭 一條黑白相間色的狗
如下圖:

示例2:
update students set name=replace(name,'大貓','小貓咪的姐姐')
結果:name為 ‘大貓’的這條數據name=’小貓咪的姐姐’
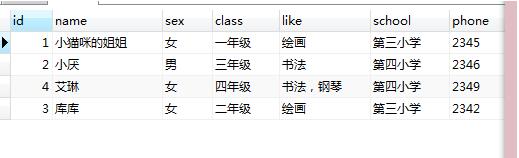
示例3:
select * from students where school='第四小學' ORDER BY replace(name,'艾琳','1')
結果:

4.translate的用法
translate(string text, from text, to text)
返回類型:text
解釋:把在string中包含的任何匹配from中的字符的字符轉化為對應的在to中的字符。
示例1:
select translate('她真是好看', '好看','漂亮')
結果:

示例2:
select * from students where phone like '2%' ORDER BY translate(class, '一二三四','1234')
結果:

示例3:
select * from students where phone like '2%' ORDER BY translate(name, '庫小厭貓咪艾','1234')
結果

結論:
有瞭translate再也不擔心中文排序問題瞭(數據比較少的情況)
補充:pg中position、split_part、translate、strpos、length函數
我就廢話不多說瞭,大傢還是直接看代碼吧~
select position('.' in '1.1.2.10');
select split_part('1.1.2.10','.',length('1.1.2.10') - length(translate('1.1.2.10','.',''))+1);
select split_part('1.1.2','.',length('1.1.2') - length(translate('1.1.2','.',''))+1);
select length(translate('1.1.2.10','.','a'))+1 as num
select translate('1.1.2.10','.','')
select strpos('1.1.2.10','.')
select instr('1.1.2.10','.',1,3)
select length('1.1.2.10') - length(translate('1.1.2.10','.',''))
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。如有錯誤或未考慮完全的地方,望不吝賜教。
推薦閱讀:
- Postgresql數據庫character varying和character的區別說明
- PostgreSQL去掉表中所有不可見字符的操作
- sql查詢語句之平均分、最高最低分及排序語句
- postgresql 實現字符串分割字段轉列表查詢
- PostgreSQL function返回多行的操作