Python數據分析之繪圖和可視化詳解
一、前言
matplotlib是一個用於創建出版質量圖表的桌面繪圖包(主要是2D方面)。該項目是由John Hunter於2002年啟動的,其目的是為Python構建一個MATLAB式的繪圖接口。matplotlib和IPython社區進行合作,簡化瞭從IPython shell(包括現在的Jupyter notebook)進行交互式繪圖。matplotlib支持各種操作系統上許多不同的GUI後端,而且還能將圖片導出為各種常見的矢量(vector)和光柵(raster)圖:PDF、SVG、JPG、PNG、BMP、GIF等。除瞭幾張,本書中的大部分圖都是用它生成的。
對於創建用於打印或網頁的靜態圖形,我建議默認使用matplotlib和附加的庫,比如pandas和seaborn。對於交互式圖形以便在Web上發佈,可以使用Plotly和Boken
學習本章代碼案例的最簡單方法是在Jupyter notebook進行交互式繪圖。在Jupyter notebook中執行下面的語句:%matplotlib notebook
二、matplotlib API 入門
1.引入matplotlib,並創建簡單的圖形
import matplotlib.pyplot as plt import numpy as np data = np.arange(10) plt.plot(data)
雖然seaborn這樣的庫和pandas的內置繪圖函數能夠處理許多普通的繪圖任務,但如果需要自定義一些高級功能的話就必須學習matplotlib API。matplotlib的示例庫和文檔是學習高級特性的最好資源。
2.matplotlib的圖像都位於Figure對象中。你可以用plt.figure創建一個新的Figure,但不能通過空Figure繪圖。必須用add_subplot創建一個或多個subplot才行:
fig = plt.figure() ax1 = fig.add_subplot(2, 2, 1) ax2 = fig.add_subplot(2, 2, 2) ax3 = fig.add_subplot(2, 2, 3) plt.plot(np.random.randn(50).cumsum(), 'k--') # 在最後一個用過的subplot上進行繪制,隱藏創建figure和subplot的過程
提示:使用Jupyter notebook有一點不同,即每個小窗重新執行後,圖形會被重置。因此,對於復雜的圖形,,你必須將所有的繪圖命令存在一個小窗裡。
由fig.add_subplot所返回的對象是AxesSubplot對象,直接調用它們的實例方法就可以在其它空著的格子裡面畫圖瞭
ax1.hist(np.random.randn(100), bins=20, color='k', alpha=0.3) ax2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30))
3.plt.subplots,它可以創建一個新的Figure,並返回一個含有已創建的subplot對象的NumPy數組:fig, axes = plt.subplots(2, 3)。可以輕松地對axes數組進行索引,就好像是一個二維數組一樣,例如axes[0,1]。還可以通過sharex和sharey指定subplot應該具有相同的X軸或Y軸。在比較相同范圍的數據時,這也是非常實用的,否則,matplotlib會自動縮放各圖表的界限。

4.利用Figure的subplots_adjust(也是個頂級函數)方法可以輕而易舉地修改間距:subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=None),其中wspace和hspace用於控制寬度和高度的百分比,可以用作subplot之間的間距。
5.在plot函數中可以通過字符串來指定顏色和線型:ax.plot(x, y,'g--')
這種更為明確的方式也能得到同樣的效果:ax.plot(x, y, linestyle='--', color='g')
常用的顏色可以使用顏色縮寫,也可以指定顏色碼(例如,#CECECE)
在
IPython和Jupyter中使用plot?可以查看文檔說明。
6.線圖可以使用標記強調數據點。因為matplotlib可以創建連續線圖,在點之間進行插值,因此有時可能不太容易看出真實數據點的位置。標記也可以放到格式字符串中,但標記類型和線型必須放在顏色後面:
from numpy.random import randn plt.plot(randn(30).cumsum(), 'ko--') plot(randn(30).cumsum(), color='k', linestyle='dashed', marker='o')
7.在線型圖中,非實際數據點默認是按線性方式插值的。可以通過drawstyle選項修改
data = np.random.randn(30).cumsum() plt.plot(data,'k--', label='Default') plt.plot(data,'k-', drawstyle='steps-post', label='steps-post') plt.legend(loc='best')

筆記:你必須調用plt.legend(或使用ax.legend,如果引用瞭軸的話)來創建圖例,無論你繪圖時是否傳遞label標簽選項。
8.pyplot接口的設計目的就是交互式使用,含有諸如xlim、xticks和xticklabels之類的方法。它們分別控制圖表的范圍、刻度位置、刻度標簽等。其使用方式有以下兩種:
- 調用時不帶參數,則返回當前的參數值(例如,
plt.xlim()返回當前的X軸繪圖范圍)。 - 調用時帶參數,則設置參數值(例如,
plt.xlim([0,10])會將X軸的范圍設置為0到10)。
所有這些方法都是對當前或最近創建的AxesSubplot起作用的。它們各自對應subplot對象上的兩個方法,以xlim為例,就是ax.get_xlim和ax.set_xlim。
9. 設置標題、軸標簽、刻度以及刻度標簽
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(np.random.randn(1000).cumsum()) # 創建隨機漫步數據
ticks = ax.set_xticks([0,250,500,750,1000]) # 改變x軸刻度
labels = ax.set_xticklabels(['one','two','three','four','five'], rotation=30, fontsize='small') # 設置軸標簽
ax.set_title('My first matplotlib plot') # 設置題目
ax.set_xlabel('Stages') # 設置軸名稱
props ={
'title':'My first matplotlib plot',
'xlabel':'Stages'
}
ax.set(**props) # 設置題目和軸名稱
10.圖例(legend)是另一種用於標識圖表元素的重要工具。最簡單的是在添加subplot的時候傳入label參數。要從圖例中去除一個或多個元素,不傳入label或傳入label='nolegend‘即可。
fig = plt.figure(); ax = fig.add_subplot(1,1,1) ax.plot(randn(1000).cumsum(),'k', label='one') ax.plot(randn(1000).cumsum(),'k--', label='two') ax.plot(randn(1000).cumsum(),'k.', label='three') ax.legend(loc='best') # 必須調用legend方法才能顯示圖例
11.註解以及在Subplot上繪圖
- 註解和文字可以通過text、arrow和annotate函數進行添加。text可以將文本繪制在圖表的指定坐標(x,y),還可以加上一些自定義格式:
ax.text(x, y,'Hello world!', family='monospace', fontsize=10) - 註解中可以既含有文本也含有箭頭。
- 要在圖表中添加一個圖形,你需要創建一個塊對象shp,然後通過
ax.add_patch(shp)將其添加到subplot中:
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
rect = plt.Rectangle((0.2,0.75),0.4,0.15, color='k', alpha=0.3)
circ = plt.Circle((0.7,0.2),0.15, color='b', alpha=0.3)
pgon = plt.Polygon([[0.15,0.15],[0.35,0.4],[0.2,0.6]],
color='g', alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)
12.將圖表保存到文件
plt.savefig可以將當前圖表保存到文件。該方法相當於Figure對象的實例方法savefig。
參數:
dpi:控制“每英寸點數”分辨率;
bbox_inches:可以剪除當前圖表周圍的空白部分
plt.savefig('figpath.png', dpi=400, bbox_inches='tight')
savefig並非一定要寫入磁盤,也可以寫入任何文件型的對象,比如BytesIO:
from io importBytesIO buffer =BytesIO() plt.savefig(buffer) plot_data = buffer.getvalue()

13.matplotlib自帶一些配色方案,以及為生成出版質量的圖片而設定的默認配置信息。幾乎所有默認行為都能通過一組全局參數進行自定義,它們可以管理圖像大小、subplot邊距、配色方案、字體大小、網格類型等。一種Python編程方式配置系統的方法是使用rc方法。
- 要將全局的圖像默認大小設置為10×10,可以執行:
plt.rc('figure', figsize=(10,10)) rc的第一個參數是希望自定義的對象,如’figure’、’axes’、’xtick’、’ytick’、’grid’、’legend’等。其後可以跟上一系列的關鍵字參數。一個簡單的辦法是將這些選項寫成一個字典:
font_options ={
'family':'monospace',
'weight':'bold',
'size':'small'
}
plt.rc('font',**font_options)
三、使用pandas和seaborn繪圖
在pandas中,我們有多列數據,還有行和列標簽。pandas自身就有內置的方法,用於簡化從DataFrame和Series繪制圖形。另一個庫seaborn簡化瞭許多常見可視類型的創建。
提示:引入seaborn會修改matplotlib默認的顏色方案和繪圖類型,以提高可讀性和美觀度。即使你不使用seaborn API,你可能也會引入seaborn,作為提高美觀度和繪制常見matplotlib圖形的簡化方法。
1.Series和DataFrame都有一個用於生成各類圖表的plot方法。默認情況下,它們所生成的是線型圖:
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10)) s.plot()
該Series對象的索引會被傳給matplotlib,並用以繪制X軸。可以通過use_index=False禁用該功能。X軸的刻度和界限可以通過xticks和xlim選項進行調節,Y軸就用yticks和ylim。


2.pandas的大部分繪圖方法都有一個可選的ax參數,它可以是一個matplotlib的subplot對象。這使你能夠在網格佈局中更為靈活地處理subplot的位置。DataFrame的plot方法會在一個subplot中為各列繪制一條線,並自動創建圖例
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0), columns=['A', 'B', 'C', 'D'], index=np.arange(0, 100, 10)) df.plot()
plot屬性包含一批不同繪圖類型的方法。例如,df.plot()等價於df.plot.line()

筆記:plot的其他關鍵字參數會被傳給相應的matplotlib繪圖函數,所以要更深入地自定義圖表,就必須學習更多有關matplotlib API的知識。
3.plot.bar()和plot.barh()分別繪制水平和垂直的柱狀圖。這時,Series和DataFrame的索引將會被用作X(bar)或Y(barh)刻度
fig, axes = plt.subplots(2, 1)
data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
data.plot.bar(ax=axes[0], color='k', alpha=0.7) # alpha設置透明度
data.plot.barh(ax=axes[1], color='k', alpha=0.7)
4.對於DataFrame,柱狀圖會將每一行的值分為一組,並排顯示
df = pd.DataFrame(np.random.rand(6, 4), index=['one', 'two', 'three', 'four', 'five', 'six'], columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus')) df.plot.bar()
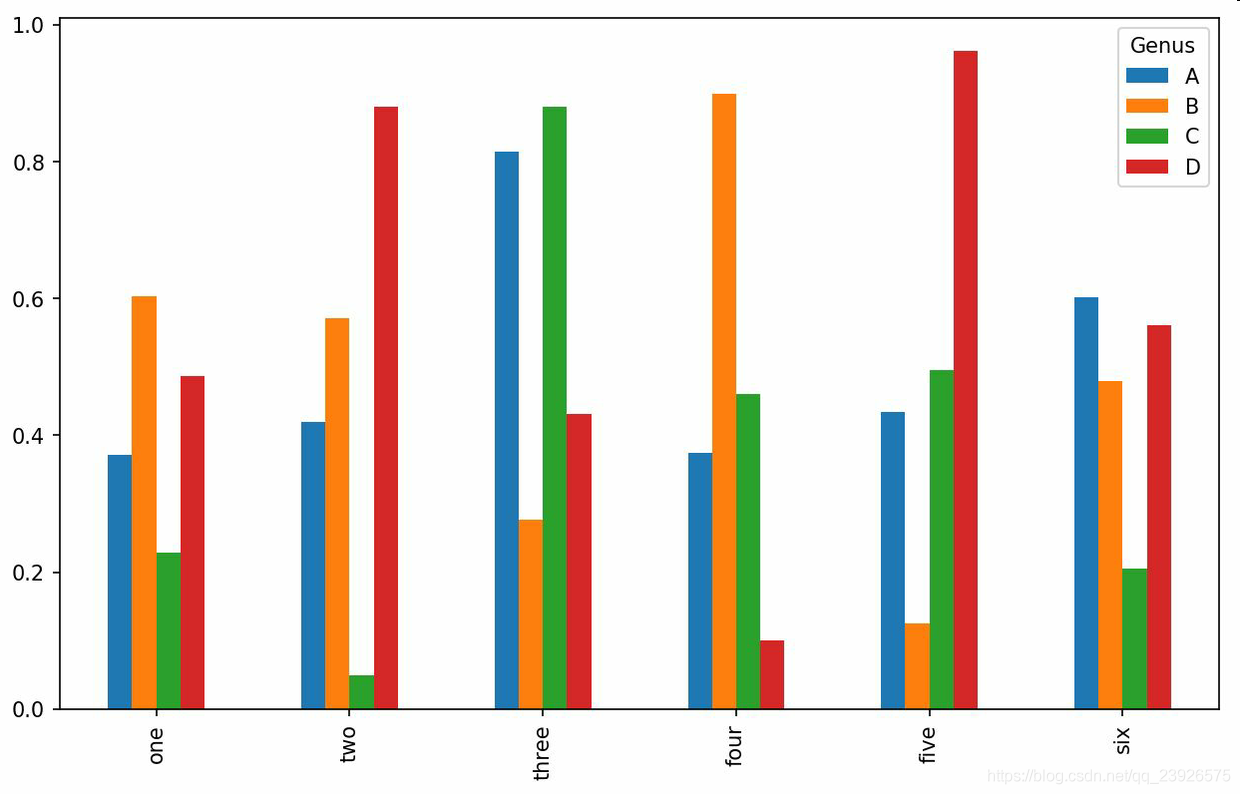
5.設置stacked=True即可為DataFrame生成堆積柱狀圖,這樣每行的值就會被堆積在一起:df.plot.barh(stacked=True, alpha=0.5)
筆記:柱狀圖有一個非常不錯的用法:利用
value_counts圖形化顯示Series中各值的出現頻率,比如s.value_counts().plot.bar()。
6.做一張堆積柱狀圖以展示每天各種聚會規模的數據點的百分比。
In [75]: tips = pd.read_csv('pydata-book-2nd-edition/')
In [76]: party_counts = pd.crosstab(tips['day'], tips['size'])
In [77]: party_counts
Out[77]:
size 1 2 3 4 5 6
day
Fri 1 16 1 1 0 0
Sat 2 53 18 13 1 0
Sun 0 39 15 18 3 1
Thur 1 48 4 5 1 3
# Not many 1- and 6-person parties
In [78]: party_counts = party_counts.loc[:, 2:5]
In [79]: party_pcts = party_counts.div(party_counts.sum(1), axis=0) # 進行規格化,使得各行的和為1
In [81]: party_pcts.plot.bar()
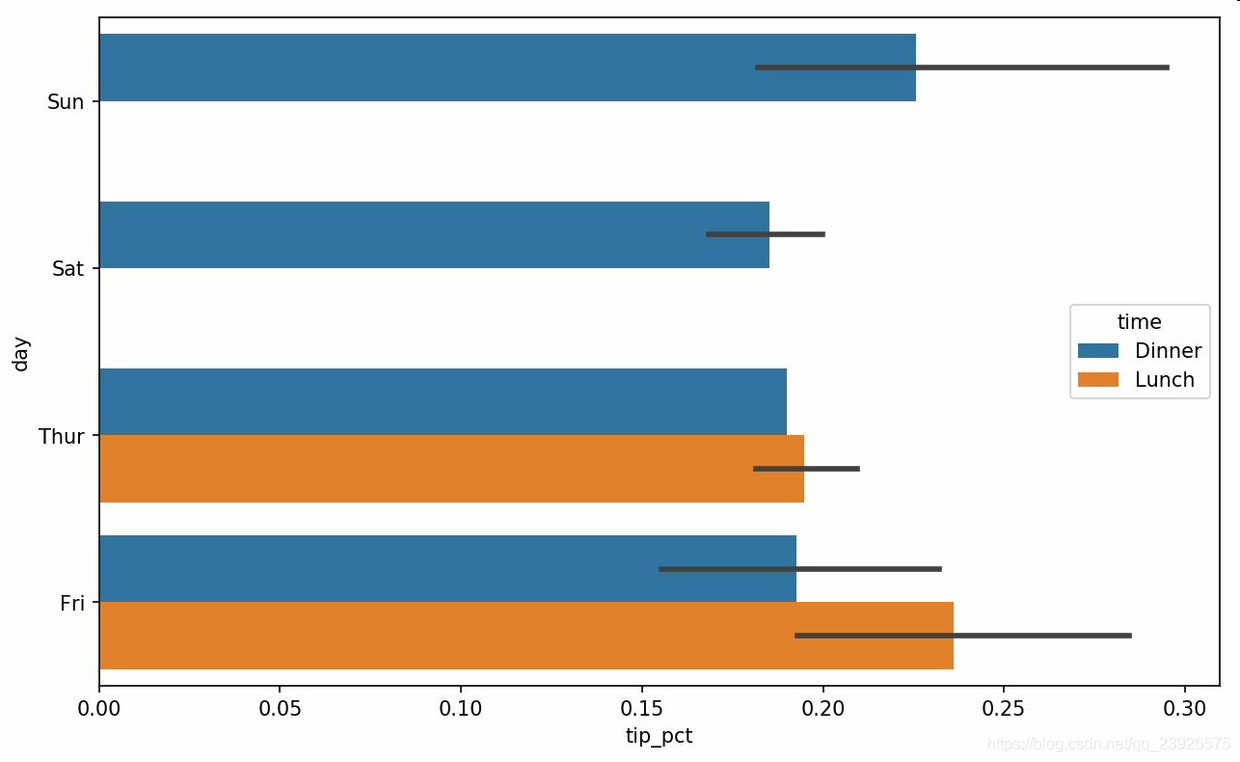
7.對於在繪制一個圖形之前,需要進行合計的數據,使用seaborn可以減少工作量。seaborn的繪制函數使用data參數,它可能是pandas的DataFrame。其它的參數是關於列的名字。因為一天的每個值有多次觀察,柱狀圖的值是tip_pct的平均值。繪制在柱狀圖上的黑線代表95%置信區間(可以通過可選參數配置)。
In [83]: import seaborn as sns In [84]: %matplotlib inline # 在jupyter中輸入,避免無法顯示圖的問題 In [85]: tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip']) In [86]: tips.head() Out[86]: total_bill tip smoker day time size tip_pct 0 16.99 1.01 No Sun Dinner 2 0.063204 1 10.34 1.66 No Sun Dinner 3 0.191244 2 21.01 3.50 No Sun Dinner 3 0.199886 3 23.68 3.31 No Sun Dinner 2 0.162494 4 24.59 3.61 No Sun Dinner 4 0.172069 In [86]: sns.barplot(x='tip_pct', y='day', data=tips, orient='h') In [87]: sns.barplot(x='tip_pct', y='day', hue='time', data=tips, orient='h') # 根據time列進行顏色區分 In [90]: sns.set(style="whitegrid") # 設置圖形外觀
8.直方圖(histogram)是一種可以對值頻率進行離散化顯示的柱狀圖。數據點被拆分到離散的、間隔均勻的面元中,繪制的是各面元中數據點的數量。
tips['tip_pct'].plot.hist(bins=50) # bins表示柱的數量
9.密度圖是通過計算“可能會產生觀測數據的連續概率分佈的估計”而產生的。一般的過程是將該分佈近似為一組核(即諸如正態分佈之類的較為簡單的分佈)。因此,密度圖也被稱作KDE(Kernel Density Estimate,核密度估計)圖。使用plot.kde和標準混合正態分佈估計即可生成一張密度圖:tips['tip_pct'].plot.density()
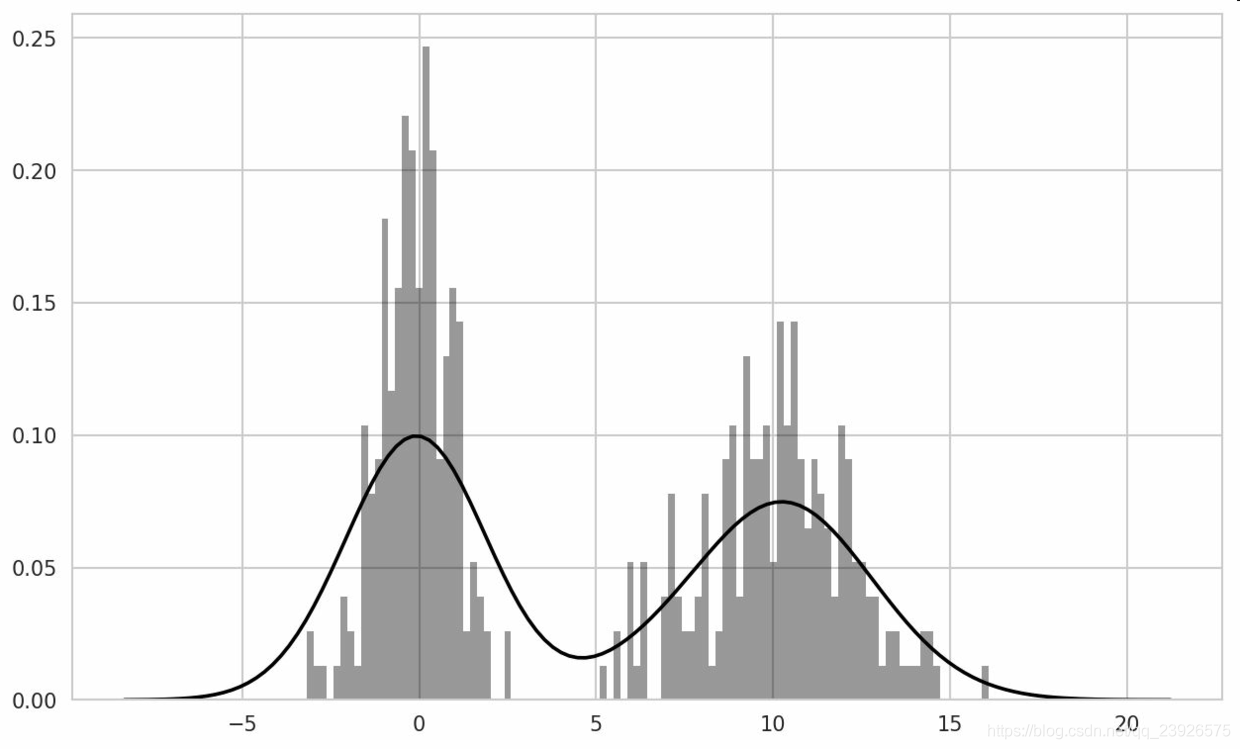
10.seaborn的distplot方法繪制直方圖和密度圖更加簡單,還可以同時畫出直方圖和連續密度估計圖。作為例子,考慮一個雙峰分佈,由兩個不同的標準正態分佈組成:
In [96]: comp1 = np.random.normal(0, 1, size=200) In [97]: comp2 = np.random.normal(10, 2, size=200) In [98]: values = pd.Series(np.concatenate([comp1, comp2])) In [99]: sns.distplot(values, bins=100, color='k')
11.點圖或散佈圖是觀察兩個一維數據序列之間的關系的有效手段。在下面這個例子中,我加載瞭來自statsmodels項目的macrodata數據集,選擇瞭幾個變量,然後計算對數差:
In [100]: macro = pd.read_csv('examples/macrodata.csv')
In [101]: data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
In [102]: trans_data = np.log(data).diff().dropna()
In [103]: trans_data[-5:]
Out[103]:
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560
In [104]: sns.regplot('m1', 'unemp', data=trans_data) # 做一個散佈圖,並加上一條線性回歸的線
In [107]: sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2}) # 生成散佈圖矩陣,pairplot支持在對角線上放置每個變量的直方圖或密度估計
plot_kws參數可以傳遞配置選項到非對角線元素上的圖形使用。

12.有多個分類變量的數據可視化的一種方法是使用小面網格。seaborn有一個有用的內置函數factorplot,可以簡化制作多種分面圖
sns.factorplot(x='day', y='tip_pct', hue='time', col='smoker', kind='bar', data=tips[tips.tip_pct < 1]) sns.factorplot(x='day', y='tip_pct', row='time', col='smoker', kind='bar', data=tips[tips.tip_pct < 1]) # 通過給每個時間值添加一行來擴展分面網格
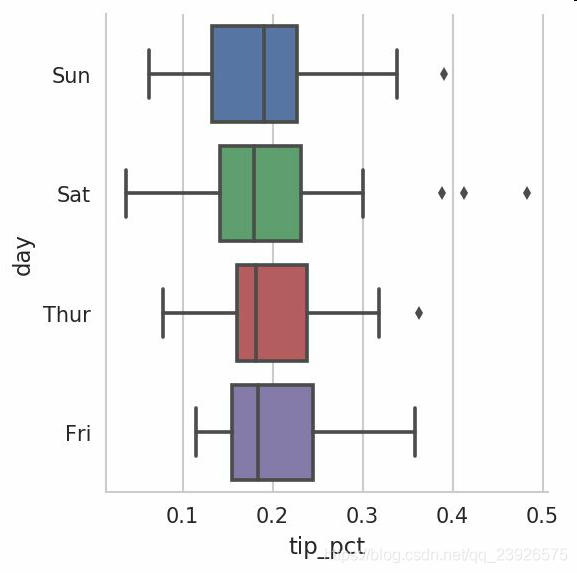
factorplot支持其它的繪圖類型,如盒圖(它可以顯示中位數,四分位數,和異常值):
sns.factorplot(x='tip_pct', y='day', kind='box', data=tips[tips.tip_pct < 0.5])
到此這篇關於Python數據分析之繪圖和可視化詳解的文章就介紹到這瞭,更多相關Python繪圖和可視化內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 一篇文章讓你快速掌握Pandas可視化圖表
- python使用Matplotlib繪制多種常見圖形
- Python中的數據可視化matplotlib與繪圖庫模塊
- Python機器學習三大件之二pandas
- Python Pandas工具繪制數據圖使用教程