單身狗福利?Python爬取某婚戀網征婚數據
目標網址https://www.csflhjw.com/zhenghun/34.html?page=1
一、打開界面

鼠標右鍵打開檢查,方框裡為你一個文小姐的征婚信息。。由此判斷出為同步加載

點擊elements,定位圖片地址,方框裡為該女士的url地址及圖片地址
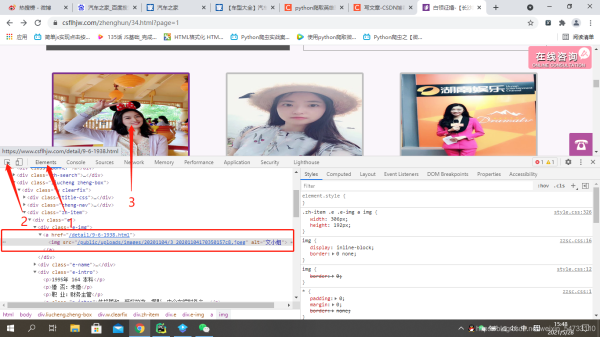
可以看出該女士的url地址不全,之後在代碼中要進行url的拼接,看一下翻頁的url地址有什麼變化
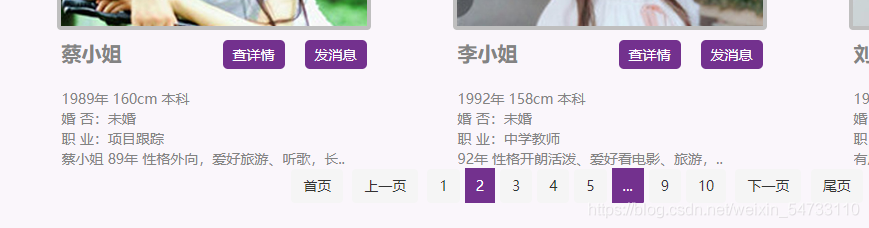
點擊第2頁
https://www.csflhjw.com/zhenghun/34.html?page=2
點擊第3頁
https://www.csflhjw.com/zhenghun/34.html?page=3
可以看出變化在最後
做一下fou循環格式化輸出一下。。一共10頁
二、代碼解析
1.獲取所有的女士的url,xpath的路徑就不詳細說瞭。。

2.構造每一位女士的url地址

3.然後點開一位女士的url地址,用同樣的方法,確定也為同步加載

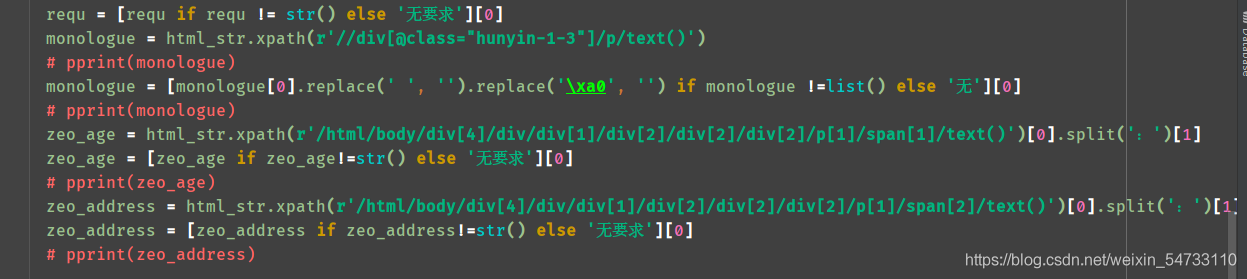
4.之後就是女士url地址html的xpath提取,每個都打印一下,把不要的過濾一下

5.最後就是文件的保存
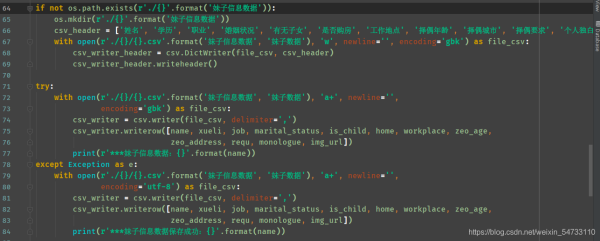
打印結果:
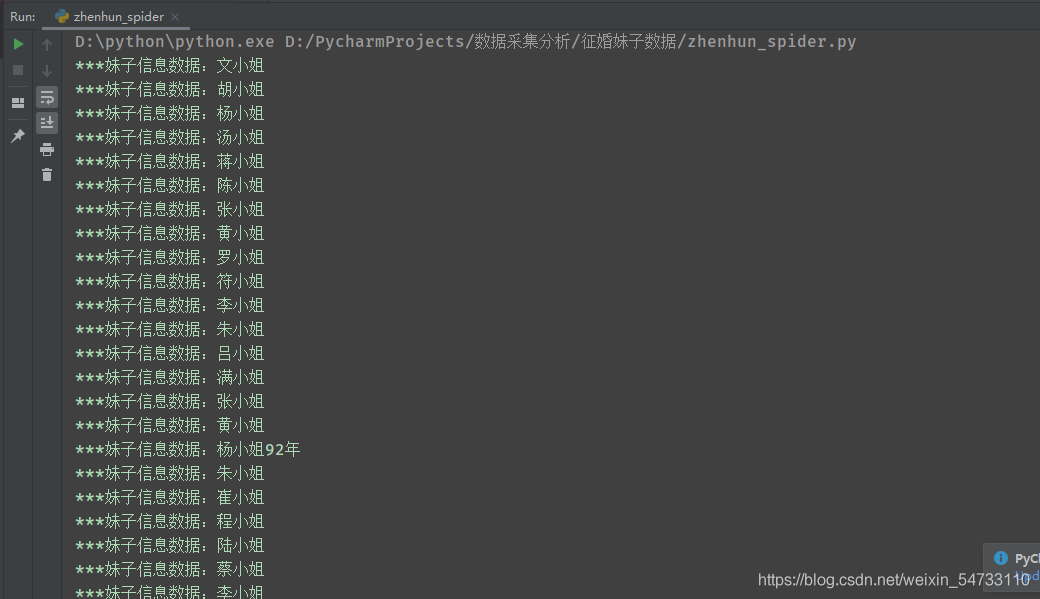
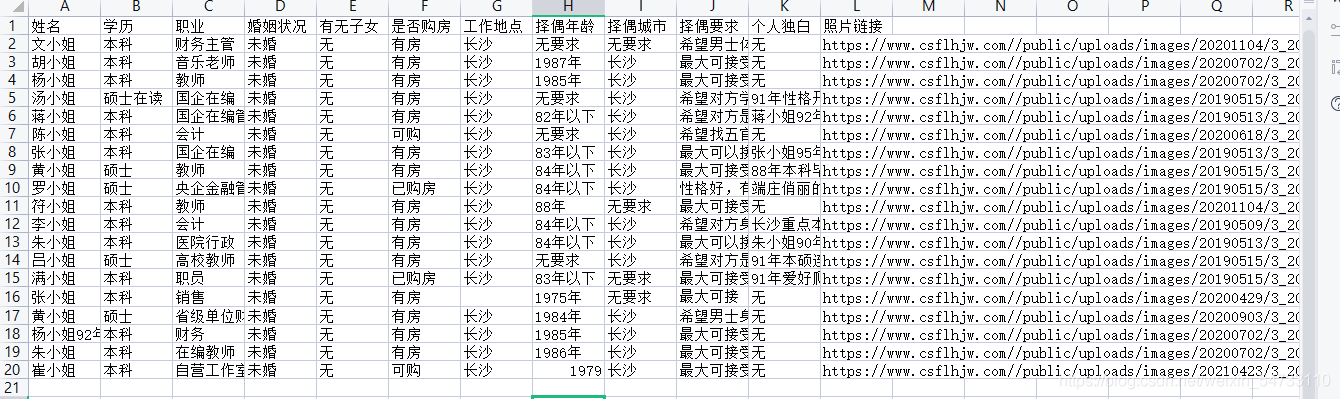
三、完整代碼
# !/usr/bin/nev python
# -*-coding:utf8-*-
import requests, os, csv
from pprint import pprint
from lxml import etree
def main():
for i in range(1, 11):
start_url = 'https://www.csflhjw.com/zhenghun/34.html?page={}'.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(start_url, headers=headers).content.decode()
# # pprint(response)
# 3 解析數據
html_str = etree.HTML(response)
info_urls = html_str.xpath(r'//div[@class="e"]/div[@class="e-img"]/a/@href')
# pprint(info_urls)
# 4、循環遍歷 構造img_info_url
for info_url in info_urls:
info_url = r'https://www.csflhjw.com' + info_url
# print(info_url)
# 5、對info_url發請求,解析得到img_urls
response = requests.get(info_url, headers=headers).content.decode()
html_str = etree.HTML(response)
# pprint(html_str)
img_url = 'https://www.csflhjw.com/' + html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[1]/div['
r'1]/img/@src')[0]
# pprint(img_url)
name = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/h2/text()')[0]
# pprint(name)
xueli = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[1]/text()')[0].split(':')[1]
# pprint(xueli)
job = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[2]/text()')[0].split(':')[1]
# pprint(job)
marital_status = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[3]/text()')[0].split(
':')[1]
# pprint(marital_status)
is_child = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[4]/text()')[0].split(':')[1]
# pprint(is_child)
home = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[5]/text()')[0].split(':')[1]
# pprint(home)
workplace = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[6]/text()')[0].split(':')[1]
# pprint(workplace)
requ = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[2]/span/text()')[0].split(':')[1]
# pprint(requ)
requ = [requ if requ != str() else '無要求'][0]
monologue = html_str.xpath(r'//div[@class="hunyin-1-3"]/p/text()')
# pprint(monologue)
monologue = [monologue[0].replace(' ', '').replace('\xa0', '') if monologue !=list() else '無'][0]
# pprint(monologue)
zeo_age = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[1]/text()')[0].split(':')[1]
zeo_age = [zeo_age if zeo_age!=str() else '無要求'][0]
# pprint(zeo_age)
zeo_address = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[2]/text()')[0].split(':')[1]
zeo_address = [zeo_address if zeo_address!=str() else '無要求'][0]
# pprint(zeo_address)
if not os.path.exists(r'./{}'.format('妹子信息數據')):
os.mkdir(r'./{}'.format('妹子信息數據'))
csv_header = ['姓名', '學歷', '職業', '婚姻狀況', '有無子女', '是否購房', '工作地點', '擇偶年齡', '擇偶城市', '擇偶要求', '個人獨白', '照片鏈接']
with open(r'./{}/{}.csv'.format('妹子信息數據', '妹子數據'), 'w', newline='', encoding='gbk') as file_csv:
csv_writer_header = csv.DictWriter(file_csv, csv_header)
csv_writer_header.writeheader()
try:
with open(r'./{}/{}.csv'.format('妹子信息數據', '妹子數據'), 'a+', newline='',
encoding='gbk') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***妹子信息數據:{}'.format(name))
except Exception as e:
with open(r'./{}/{}.csv'.format('妹子信息數據', '妹子數據'), 'a+', newline='',
encoding='utf-8') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***妹子信息數據保存成功:{}'.format(name))
if __name__ == '__main__':
main()
到此這篇關於單身狗福利?Python爬取某婚戀網征婚數據的文章就介紹到這瞭,更多相關Python爬取征婚數據內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python實現csdn全部博文下載並轉PDF
- Python爬蟲入門教程01之爬取豆瓣Top電影
- Python爬蟲實戰演練之采集糗事百科段子數據
- Python爬蟲實現熱門電影信息采集
- 教你如何利用python3爬蟲爬取漫畫島-非人哉漫畫