深入談談MySQL中的自增主鍵
MySQL的主鍵可以是自增的,那麼如果在斷電重啟後新增的值還會延續斷電前的自增值嗎?自增值默認為1,那麼可不可以改變呢?下面就說一下 MySQL的自增值。
特點
保存策略
1、如果存儲引擎是 MyISAM,那麼這個自增值是存儲在數據文件中的;
2、如果是 InnoDB引擎,1)在 5.6之前是存儲在內存中,沒有持久化,在重啟後會去找最大的鍵值,舉個例子,如果一個表當前數據行裡最大 id是10,AUTO_INCREMENT=11。這時候,我們刪除 id=10 的行,AUTO_INCREMENT 還是 11。但如果馬上重啟實例,重啟後這個表的 AUTO_INCREMENT 就會變成 10;
2)在 8.0開始,自增值就保存在 redo log中,重啟後會從 redo log中讀取之前保存的自增值。
自增值的確定
1、如果插入數據時 id字段指定為0、null或未指定,那麼就把這個表當前的 AUTO_INCREMENT值填到自增字段,並且會以auto_increment_offset作為初始值,auto_increment_increment為步長,找出第一個大於當前自增值的值作為新的自增值。
2、如果插入的數據的 id字段指定瞭具體的值,就直接使用語句裡的值。
在一些場景下,使用的就不全是默認值。比如,雙 M 的主備結構裡要求雙寫的時候,我們就可能會設置成 auto_increment_increment=2,讓一個庫的自增 id 都是奇數,另一個庫的自增 id 都是偶數,避免兩個庫生成的主鍵發生沖突。
自增值的修改
假設某次要輸入的值是 X,當前的自增值是 Y。那麼:
1、如果 X<Y,那麼這個表的自增值不變;
2、如果X≥Y,那麼就把當前自增值修改為新的自增值。
執行過程
假設有表t ,id是自增主鍵,在已有 (1,1,1)的情況下,插入一條 (null,1,1),那麼執行過程就如下:
1、執行器調用 InnoDB 引擎接口寫入一行,傳入的這一行的值是 (0,1,1);
2、InnoDB 發現用戶沒有指定自增 id 的值,獲取表 t 當前的自增值 2;
3、將傳入的行的值改成 (2,1,1);
4、將表的自增值改成 3;
5、繼續執行插入數據操作,由於已經存在 c=1 的記錄,所以報 Duplicate key error,語句返回。

帶來的問題
由於上面說得這種特性,在一些場景中會出現主鍵不連續的現象。
場景1:添加數據時唯一索引重復
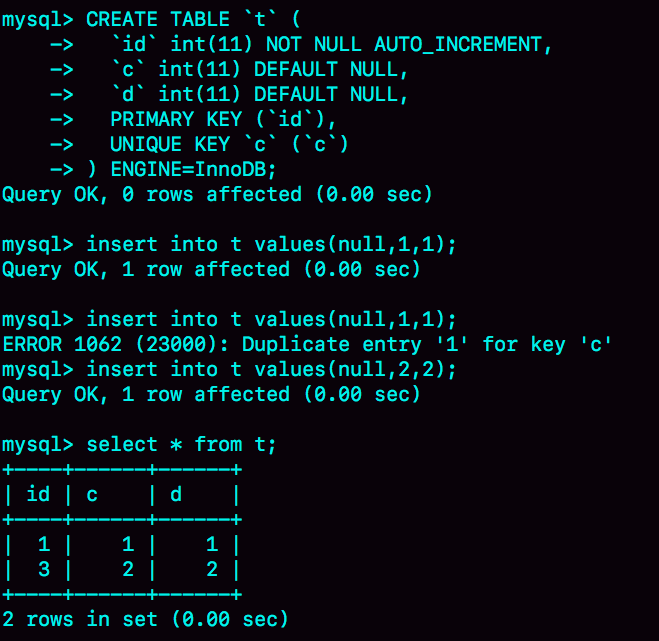
在 c列索引重復後,原本要分配的主鍵值 2就會被丟棄,而下次再次插入就從 2 開始計算,也就變成瞭 3。
場景2:事務回滾
insert into t values(null,1,1); begin; insert into t values(null,2,2); rollback; insert into t values(null,2,2); //插入的行是(3,2,2)
在第二條語句回滾後分配給其的主鍵 2也會被丟棄。
場景3:特殊批插入優化導致
這裡說得特殊的批插入指的是insert … select、replace … select 和 load data 語句。為什麼說這些語句可能會導致?這就要說到自增鎖瞭。首先自增鎖是為瞭避免多線程沖突,因為在多線程下,如果同時有多個線程來獲取自增值,那麼就可能會導致同一個自增值被分配給多條記錄,導致逐漸沖突。所以需要自增鎖,而為什麼前面說得這些批插入語句會導致主鍵不連續,在下面自增鎖部分會說到。
問題:在說自增鎖之前,先思考一個問題,為什麼對於前兩個場景,不把自增主鍵值設為可以回滾的?這樣不就可以避免不連續瞭麼?
答:因為設計成可回滾的會導致性能下降,看下面這個場景。
1、假設事務 A 申請到瞭 id=2, 事務 B 申請到 id=3,那麼這時候表 t 的自增值是 4,之後繼續執行。
2、事務 B 正確提交瞭,但事務 A 出現瞭唯一鍵沖突。
3、如果允許事務 A 把自增 id 回退,也就是把表 t 的當前自增值改回 2,那麼就會出現這樣的情況:表裡面已經有 id=3 的行,而當前的自增 id 值是 2。
4、接下來,繼續執行的其他事務就會申請到 id=2,然後再申請到 id=3。這時,就會出現插入語句報錯“主鍵沖突”。
而為瞭解決上面這個問題,就需要從下面兩個方法中選一個。
方法一、每次申請 id 之前,先判斷表裡面是否已經存在這個 id。如果存在,就跳過這個 id。但是,這個方法的成本很高。因為,本來申請 id 是一個很快的操作,現在還要再去主鍵索引樹上判斷 id 是否存在。
方法二:把自增 id 的鎖范圍擴大,必須等到一個事務執行完成並提交,下一個事務才能再申請自增 id。這個方法的問題,就是鎖的粒度太大,系統並發能力大大下降。
所以,綜合來看,比如取消自增值回滾的功能。
自增鎖
自增鎖是為瞭避免在多線程中多個線程獲取到同一個主鍵值,導致主鍵沖突。
加鎖策略
5.0版本:范圍是語句,隻有等到語句執行完後才會釋放。
5.1.22開始:引入瞭一個innodb_autoinc_lock_mode參數,根據參數值的不同執行不同的策略。默認是1。
1、參數等於0,表示采用之前的策略,即語句執行結束就會釋放。
2、參數等於1,對於普通 insert語句,自增鎖在申請之後立馬釋放;
對於 insert…select這樣的批量插入數據的語句,會等到語句執行完才會釋放。加鎖范圍是 select所涉及到的范圍和間隙。
3、參數等於3,所有的申請自增主鍵的動作都是申請後就釋放鎖。
問題:為什麼默認情況下, insert…select這樣的批操作要使用語句級的鎖?為什麼參數默認不是2?
答:因為對於 insert…select這樣的批量插入數據的語句,可能會導致主從不一致的情況發生。

在 sessionB執行完 “create table t2 like t”後,sessionA和 sessionB同時操作 t2。如果沒有鎖,那麼執行過程就可能會出現下面的情況。
session B 先插入瞭兩個記錄,(1,1,1)、(2,2,2);然後,session A 來申請自增 id 得到 id=3,插入瞭(3,5,5);之後,session B 繼續執行,插入兩條記錄 (4,3,3)、 (5,4,4)。
雖然這樣看起來確實沒有什麼問題,但是如果是在集群中,主機這樣執行,提示 binlog是 statement格式的,那麼從機執行的順序就有可能和主機不一致,最終導致主從不一致。所以需要在批量插入時加鎖。而如果設置為2,那麼如果 binlog不是 row,就會導致主從數據不一致。
所以,要想保證數據一致,也保證系統的並發性,可以有兩種方案:
方案一:將 binlog格式設為 statement,innodb_autoinc_lock_mode設為1。
方案二:將 binlog格式設為 row,innodb_autoinc_lock_mode設為2。一般我們為瞭保證 MySQL的高可用,都將 binlog設為 row,所以一般選擇第二種方案。
批插入的優化
在批插入時,由於不知道一次性插入的語句有多少,如果記錄多達幾千萬甚至上億條,那麼每次插入都需要分配一次自增值,這樣效率會很慢,所以 MySQL 對批操作進行瞭優化:
1、語句執行過程中,第一次申請自增 id,會分配 1 個;
2、1 個用完以後,這個語句第二次申請自增 id,會分配 2 個;
3、2 個用完以後,還是這個語句,第三次申請自增 id,會分配 4 個;
4、依此類推,同一個語句去申請自增 id,每次申請到的自增 id 個數都是上一次的兩倍。
舉個例子,執行下面的代碼
insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t; insert into t2(c,d) select c,d from t; insert into t2 values(null, 5,5);
insert…select,實際上往表 t2 中插入瞭 4 行數據。但是,這四行數據是分三次申請的自增 id,第一次申請到瞭 id=1,第二次被分配瞭 id=2 和 id=3, 第三次被分配到 id=4 到 id=7。由於這條語句實際隻用上瞭 4 個 id,所以 id=5 到 id=7 就被浪費掉瞭。之後,再執行 insert into t2 values(null, 5,5),實際上插入的數據就是(8,5,5)。這就是前面說到主鍵不連續的第三種情況。
insert…select前後操作同一個表會用到臨時表
假設有表結構
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t
如果執行的語句是:
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
如果我們查詢慢日志,會發現

掃描行數是1,也就是直接在 t上通過索引找到那一條記錄,然後插入 t2表。
如果將這條語句改成
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
那麼此時查看慢日志就會發現變成瞭 5,這是為什麼?就算全查出來也隻會是4條,這時我們查看掃描行數的變化

發現前後變化是4行,所以確定瞭是使用瞭臨時表,那麼就可以確定過程是:
1、創建臨時表,表裡有兩個字段 c 和 d。
2、按照索引 c 掃描表 t,依次取 c=4、3、2、1,然後回表,讀到 c 和 d 的值寫入臨時表。這時,Rows_examined=4。
3、由於語義裡面有 limit 1,所以隻取瞭臨時表的第一行,再插入到表 t 中。這時,Rows_examined 的值加 1,變成瞭 5。
至於為什麼需要臨時表,這是為瞭防止在讀取時,讀到瞭剛剛插入的值。
優化
因為select返回的記錄數較少,所以可以使用內存臨時表來優化,
create temporary table temp_t(c int,d int) engine=memory; insert into temp_t (select c+1, d from t force index(c) order by c desc limit 1); insert into t select * from temp_t; drop table temp_t;
這樣掃描的總行數隻有 select的 1加上臨時表上的 1。
最後
對於唯一索引的沖突,可以使用insert into … on duplicate key update來進行沖突後的更新處理,假設表 t中有(1,1,1)、(2,2,2)兩條記錄,那麼執行:

在插入時發現沖突就對沖突的記錄進行修改操作。
總結
到此這篇關於MySQL中的自增主鍵的文章就介紹到這瞭,更多相關MySQL自增主鍵內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 詳解MySQL自增主鍵的實現
- MySQL之select、distinct、limit的使用
- MySQL中order by的使用詳情
- MySQL 8.0新特性之隱藏字段的深入講解
- MySQL數據庫簡介與基本操作