python中opencv實現文字分割的實踐
圖片文字分割的時候,常用的方法有兩種。一種是投影法,適用於排版工整,字間距行間距比較寬裕的圖像;還有一種是用OpenCV的輪廓檢測,適用於文字不規則排列的圖像。
投影法
對文字圖片作橫向和縱向投影,即通過統計出每一行像素個數,和每一列像素個數,來分割文字。
分別在水平和垂直方向對預處理(二值化)的圖像某一種像素進行統計,對於二值化圖像非黑即白,我們通過對其中的白點或者黑點進行統計,根據統計結果就可以判斷出每一行的上下邊界以及每一列的左右邊界,從而實現分割的目的。
算法步驟:
- 使用水平投影和垂直投影的方式進行圖像分割,根據投影的區域大小尺寸分割每行和每塊的區域,對原始圖像進行二值化處理。
- 投影之前進行圖像灰度學調整做膨脹操作
- 分別進行水平投影和垂直投影
- 根據投影的長度和高度求取完整行和塊信息
橫板文字-小票文字分割
#小票水平分割
import cv2
import numpy as np
img = cv2.imread(r"C:\Users\An\Pictures\1.jpg")
cv2.imshow("Orig Image", img)
# 輸出圖像尺寸和通道信息
sp = img.shape
print("圖像信息:", sp)
sz1 = sp[0] # height(rows) of image
sz2 = sp[1] # width(columns) of image
sz3 = sp[2] # the pixels value is made up of three primary colors
print('width: %d \n height: %d \n number: %d' % (sz2, sz1, sz3))
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
retval, threshold_img = cv2.threshold(gray_img, 120, 255, cv2.THRESH_BINARY_INV)
cv2.imshow("threshold_img", threshold_img)
# 水平投影分割圖像
gray_value_x = []
for i in range(sz1):
white_value = 0
for j in range(sz2):
if threshold_img[i, j] == 255:
white_value += 1
gray_value_x.append(white_value)
print("", gray_value_x)
# 創建圖像顯示水平投影分割圖像結果
hori_projection_img = np.zeros((sp[0], sp[1], 1), np.uint8)
for i in range(sz1):
for j in range(gray_value_x[i]):
hori_projection_img[i, j] = 255
cv2.imshow("hori_projection_img", hori_projection_img)
text_rect = []
# 根據水平投影分割識別行
inline_x = 0
start_x = 0
text_rect_x = []
for i in range(len(gray_value_x)):
if inline_x == 0 and gray_value_x[i] > 10:
inline_x = 1
start_x = i
elif inline_x == 1 and gray_value_x[i] < 10 and (i - start_x) > 5:
inline_x = 0
if i - start_x > 10:
rect = [start_x - 1, i + 1]
text_rect_x.append(rect)
print("分行區域,每行數據起始位置Y:", text_rect_x)
# 每行數據分段
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 3))
dilate_img = cv2.dilate(threshold_img, kernel)
cv2.imshow("dilate_img", dilate_img)
for rect in text_rect_x:
cropImg = dilate_img[rect[0]:rect[1],0:sp[1]] # 裁剪圖像y-start:y-end,x-start:x-end
sp_y = cropImg.shape
# 垂直投影分割圖像
gray_value_y = []
for i in range(sp_y[1]):
white_value = 0
for j in range(sp_y[0]):
if cropImg[j, i] == 255:
white_value += 1
gray_value_y.append(white_value)
# 創建圖像顯示水平投影分割圖像結果
veri_projection_img = np.zeros((sp_y[0], sp_y[1], 1), np.uint8)
for i in range(sp_y[1]):
for j in range(gray_value_y[i]):
veri_projection_img[j, i] = 255
cv2.imshow("veri_projection_img", veri_projection_img)
# 根據垂直投影分割識別行
inline_y = 0
start_y = 0
text_rect_y = []
for i in range(len(gray_value_y)):
if inline_y == 0 and gray_value_y[i] > 2:
inline_y = 1
start_y = i
elif inline_y == 1 and gray_value_y[i] < 2 and (i - start_y) > 5:
inline_y = 0
if i - start_y > 10:
rect_y = [start_y - 1, i + 1]
text_rect_y.append(rect_y)
text_rect.append([rect[0], rect[1], start_y - 1, i + 1])
cropImg_rect = threshold_img[rect[0]:rect[1], start_y - 1:i + 1] # 裁剪圖像
cv2.imshow("cropImg_rect", cropImg_rect)
# cv2.imwrite("C:/Users/ThinkPad/Desktop/cropImg_rect.jpg",cropImg_rect)
# break
# break
# 在原圖上繪制截圖矩形區域
print("截取矩形區域(y-start:y-end,x-start:x-end):", text_rect)
rectangle_img = cv2.rectangle(img, (text_rect[0][2], text_rect[0][0]), (text_rect[0][3], text_rect[0][1]),
(255, 0, 0), thickness=1)
for rect_roi in text_rect:
rectangle_img = cv2.rectangle(img, (rect_roi[2], rect_roi[0]), (rect_roi[3], rect_roi[1]), (255, 0, 0), thickness=1)
cv2.imshow("Rectangle Image", rectangle_img)
key = cv2.waitKey(0)
if key == 27:
print(key)
cv2.destroyAllWindows()
小票圖像二值化結果如下:

小票圖像結果分割如下:
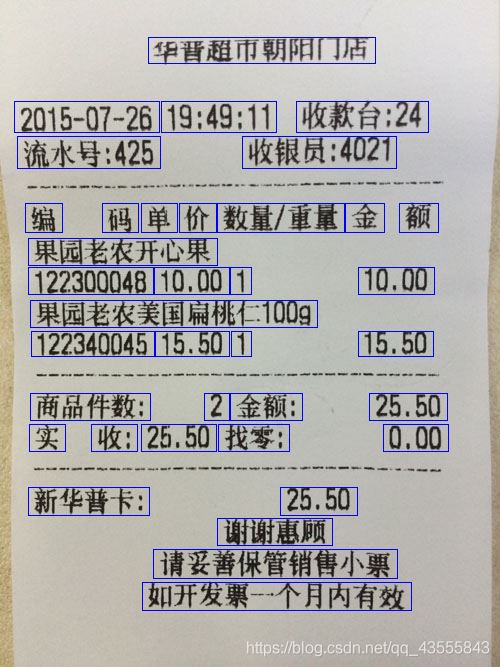
豎版-古文文字分割
對於古籍來說,古籍文字書寫在習慣是從上到下的,所以說在掃描的時候應該掃描列投影,在掃描行投影。
1.原始圖像進行二值化
使用水平投影和垂直投影的方式進行圖像分割,根據投影的區域大小尺寸分割每行和每塊的區域,對原始圖像進行二值化處理。
原始圖像:

二值化後的圖像:

2.圖像膨脹
投影之前進行圖像灰度學調整做膨脹操作,選取適當的核,對圖像進行膨脹處理。

3.垂直投影
定位該行文字區域:
數值不為0的區域就是文字存在的地方(即二值化後白色部分的區域),為0的區域就是每行之間相隔的距離。
1、如果前一個數為0,則記錄第一個不為0的坐標。
2、如果前一個數不為0,則記錄第一個為0的坐標。形象的說就是從出現第一個非空白列到出現第一個空白列這段區域就是文字存在的區域。
通過以上規則就可以找出每一列文字的起始點和終止點,從而確定每一列的位置信息。
垂直投影結果:

通過上面的垂直投影,根據其白色小山峰的起始位置就可以界定出每一列的起始位置,從而把每一列分割出來。
4.水平投影
根據投影的長度和高度求取完整行和塊信息
通過水平投影可以獲得每一個字符左右的起始位置,這樣也就可以獲得到每一個字符的具體坐標位置,即一個矩形框的位置。
import cv2
import numpy as np
import os
img = cv2.imread(r"C:\Users\An\Pictures\3.jpg")
save_path=r"E:\crop_img\result" #圖像分解的每一步保存的地址
crop_path=r"E:\crop_img\img" #圖像切割保存的地址
cv2.imshow("Orig Image", img)
# 輸出圖像尺寸和通道信息
sp = img.shape
print("圖像信息:", sp)
sz1 = sp[0] # height(rows) of image
sz2 = sp[1] # width(columns) of image
sz3 = sp[2] # the pixels value is made up of three primary colors
print('width: %d \n height: %d \n number: %d' % (sz2, sz1, sz3))
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
retval, threshold_img = cv2.threshold(gray_img, 120, 255, cv2.THRESH_BINARY_INV)
cv2.imshow("threshold_img", threshold_img)
cv2.imwrite(os.path.join(save_path,"threshold_img.jpg"),threshold_img)
# 垂直投影分割圖像
gray_value_y = []
for i in range(sz2):
white_value = 0
for j in range(sz1):
if threshold_img[j, i] == 255:
white_value += 1
gray_value_y.append(white_value)
print("", gray_value_y)
#創建圖像顯示垂直投影分割圖像結果
veri_projection_img = np.zeros((sp[0], sp[1], 1), np.uint8)
for i in range(sz2):
for j in range(gray_value_y[i]):
veri_projection_img[j, i] = 255
cv2.imshow("veri_projection_img", veri_projection_img)
cv2.imwrite(os.path.join(save_path,"veri_projection_img.jpg"),veri_projection_img)
text_rect = []
# 根據垂直投影分割識別列
inline_y = 0
start_y = 0
text_rect_y = []
for i in range(len(gray_value_y)):
if inline_y == 0 and gray_value_y[i]> 30:
inline_y = 1
start_y = i
elif inline_y == 1 and gray_value_y[i] < 30 and (i - start_y) > 5:
inline_y = 0
if i - start_y > 10:
rect = [start_y - 1, i + 1]
text_rect_y.append(rect)
print("分列區域,每列數據起始位置Y:", text_rect_y)
# 每列數據分段
# kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 3))
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dilate_img = cv2.dilate(threshold_img, kernel)
cv2.imshow("dilate_img", dilate_img)
cv2.imwrite(os.path.join(save_path,"dilate_img.jpg"),dilate_img)
for rect in text_rect_y:
cropImg = dilate_img[0:sp[0],rect[0]:rect[1]] # 裁剪圖像y-start:y-end,x-start:x-end
sp_x = cropImg.shape
# 垂直投影分割圖像
gray_value_x = []
for i in range(sp_x[0]):
white_value = 0
for j in range(sp_x[1]):
if cropImg[i, j] == 255:
white_value += 1
gray_value_x.append(white_value)
# 創建圖像顯示水平投影分割圖像結果
hori_projection_img = np.zeros((sp_x[0], sp_x[1], 1), np.uint8)
for i in range(sp_x[0]):
for j in range(gray_value_x[i]):
veri_projection_img[i, j] = 255
# cv2.imshow("hori_projection_img", hori_projection_img)
# 根據水平投影分割識別行
inline_x = 0
start_x = 0
text_rect_x = []
ind=0
for i in range(len(gray_value_x)):
ind+=1
if inline_x == 0 and gray_value_x[i] > 2:
inline_x = 1
start_x = i
elif inline_x == 1 and gray_value_x[i] < 2 and (i - start_x) > 5:
inline_x = 0
if i - start_x > 10:
rect_x = [start_x - 1, i + 1]
text_rect_x.append(rect_x)
text_rect.append([start_x - 1, i + 1,rect[0], rect[1]])
cropImg_rect = threshold_img[start_x - 1:i + 1,rect[0]:rect[1]] # 裁剪二值化圖像
crop_img=img[start_x - 1:i + 1,rect[0]:rect[1]] #裁剪原圖像
# cv2.imshow("cropImg_rect", cropImg_rect)
# cv2.imwrite(os.path.join(crop_path,str(ind)+".jpg"),crop_img)
# break
# break
# 在原圖上繪制截圖矩形區域
print("截取矩形區域(y-start:y-end,x-start:x-end):", text_rect)
rectangle_img = cv2.rectangle(img, (text_rect[0][2], text_rect[0][0]), (text_rect[0][3], text_rect[0][1]),
(255, 0, 0), thickness=1)
for rect_roi in text_rect:
rectangle_img = cv2.rectangle(img, (rect_roi[2], rect_roi[0]), (rect_roi[3], rect_roi[1]), (255, 0, 0), thickness=1)
cv2.imshow("Rectangle Image", rectangle_img)
cv2.imwrite(os.path.join(save_path,"rectangle_img.jpg"),rectangle_img)
key = cv2.waitKey(0)
if key == 27:
print(key)
cv2.destroyAllWindows()
分割結果如下:
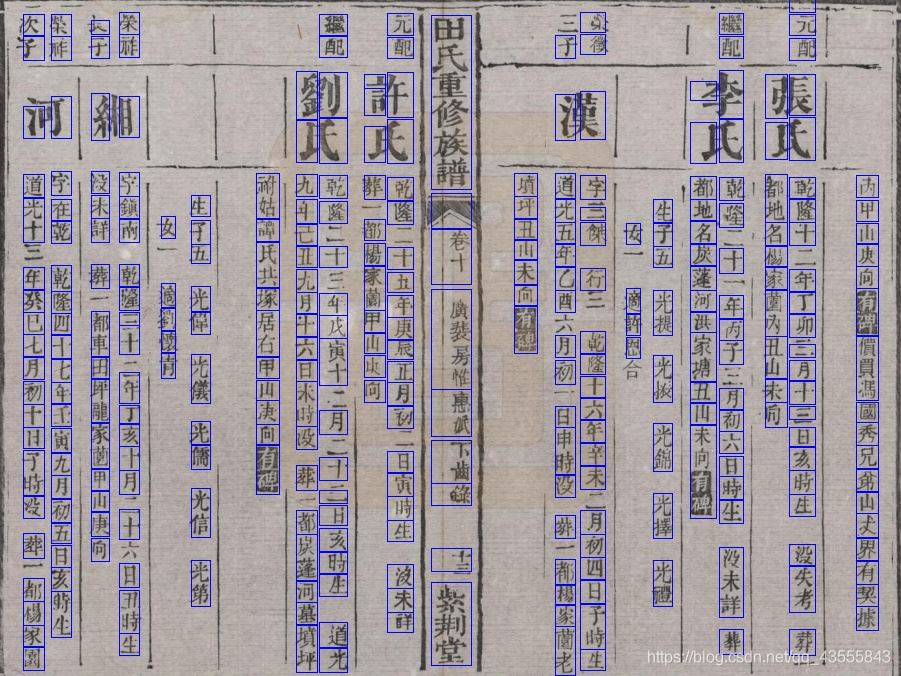
從分割的結果上看,基本上實現瞭圖片中文字的分割。但由於中文結構復雜性,對於一些文字的分割並不理想,字會出現過度分割、有粘連的兩個字會出現分割不夠的現象。可以從圖像預處理(圖像腐蝕膨脹),邊界判斷閾值的調整等方面進行優化。
到此這篇關於python中opencv實現文字分割的實踐的文章就介紹到這瞭,更多相關opencv 文字分割內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python中OpenCV實現簡單車牌字符切割
- OpenCV+python實現膨脹和腐蝕的示例
- python opencv通過4坐標剪裁圖片
- opencv實現礦石圖片檢測礦石數量
- opencv實現車牌識別