Python機器學習之基於Pytorch實現貓狗分類
一、環境配置
安裝Anaconda
具體安裝過程,請點擊本文
配置Pytorch
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision
二、數據集的準備
1.數據集的下載
kaggle網站的數據集下載地址:
https://www.kaggle.com/lizhensheng/-2000
2.數據集的分類
將下載的數據集進行解壓操作,然後進行分類
分類如下(每個文件夾下包括cats和dogs文件夾)
三、貓狗分類的實例
導入相應的庫
# 導入庫 import torch.nn.functional as F import torch.optim as optim import torch import torch.nn as nn import torch.nn.parallel import torch.optim import torch.utils.data import torch.utils.data.distributed import torchvision.transforms as transforms import torchvision.datasets as datasets
設置超參數
# 設置超參數
#每次的個數
BATCH_SIZE = 20
#迭代次數
EPOCHS = 10
#采用cpu還是gpu進行計算
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
圖像處理與圖像增強
# 數據預處理
transform = transforms.Compose([
transforms.Resize(100),
transforms.RandomVerticalFlip(),
transforms.RandomCrop(50),
transforms.RandomResizedCrop(150),
transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
讀取數據集和導入數據
# 讀取數據
dataset_train = datasets.ImageFolder('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\train', transform)
print(dataset_train.imgs)
# 對應文件夾的label
print(dataset_train.class_to_idx)
dataset_test = datasets.ImageFolder('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\validation', transform)
# 對應文件夾的label
print(dataset_test.class_to_idx)
# 導入數據
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=True)
定義網絡模型
# 定義網絡
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.max_pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.max_pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(64, 64, 3)
self.conv4 = nn.Conv2d(64, 64, 3)
self.max_pool3 = nn.MaxPool2d(2)
self.conv5 = nn.Conv2d(64, 128, 3)
self.conv6 = nn.Conv2d(128, 128, 3)
self.max_pool4 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(4608, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.max_pool3(x)
x = self.conv5(x)
x = F.relu(x)
x = self.conv6(x)
x = F.relu(x)
x = self.max_pool4(x)
# 展開
x = x.view(in_size, -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
modellr = 1e-4
# 實例化模型並且移動到GPU
model = ConvNet().to(DEVICE)
# 選擇簡單暴力的Adam優化器,學習率調低
optimizer = optim.Adam(model.parameters(), lr=modellr)
調整學習率
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
modellrnew = modellr * (0.1 ** (epoch // 5))
print("lr:",modellrnew)
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew
定義訓練過程
# 定義訓練過程
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device).float().unsqueeze(1)
optimizer.zero_grad()
output = model(data)
# print(output)
loss = F.binary_cross_entropy(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
# 定義測試過程
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device).float().unsqueeze(1)
output = model(data)
# print(output)
test_loss += F.binary_cross_entropy(output, target, reduction='mean').item()
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).to(device)
correct += pred.eq(target.long()).sum().item()
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
定義保存模型和訓練
# 訓練
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train(model, DEVICE, train_loader, optimizer, epoch)
val(model, DEVICE, test_loader)
torch.save(model, 'E:\\Cat_And_Dog\\kaggle\\model.pth')
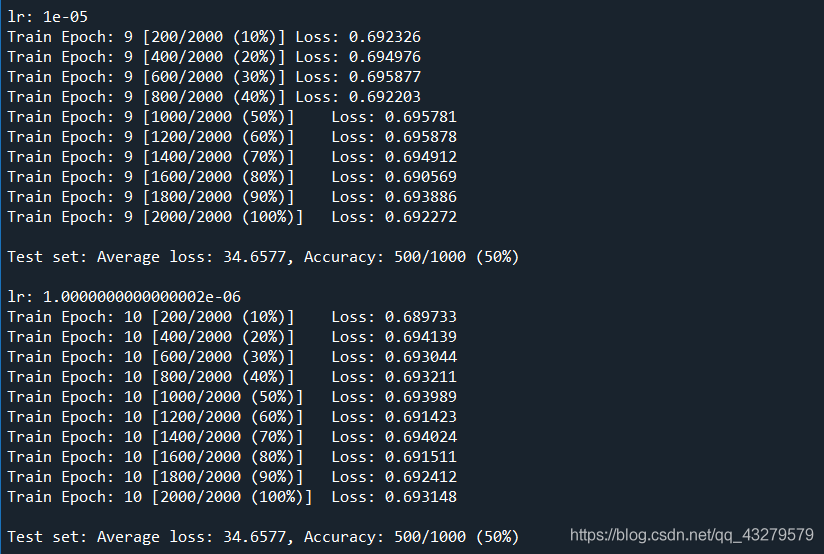
訓練結果
四、實現分類預測測試
準備預測的圖片進行測試
from __future__ import print_function, division
from PIL import Image
from torchvision import transforms
import torch.nn.functional as F
import torch
import torch.nn as nn
import torch.nn.parallel
# 定義網絡
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.max_pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.max_pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(64, 64, 3)
self.conv4 = nn.Conv2d(64, 64, 3)
self.max_pool3 = nn.MaxPool2d(2)
self.conv5 = nn.Conv2d(64, 128, 3)
self.conv6 = nn.Conv2d(128, 128, 3)
self.max_pool4 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(4608, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.max_pool3(x)
x = self.conv5(x)
x = F.relu(x)
x = self.conv6(x)
x = F.relu(x)
x = self.max_pool4(x)
# 展開
x = x.view(in_size, -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
# 模型存儲路徑
model_save_path = 'E:\\Cat_And_Dog\\kaggle\\model.pth'
# ------------------------ 加載數據 --------------------------- #
# Data augmentation and normalization for training
# Just normalization for validation
# 定義預訓練變換
# 數據預處理
transform_test = transforms.Compose([
transforms.Resize(100),
transforms.RandomVerticalFlip(),
transforms.RandomCrop(50),
transforms.RandomResizedCrop(150),
transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
class_names = ['cat', 'dog'] # 這個順序很重要,要和訓練時候的類名順序一致
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# ------------------------ 載入模型並且訓練 --------------------------- #
model = torch.load(model_save_path)
model.eval()
# print(model)
image_PIL = Image.open('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\test\\cats\\cat.1500.jpg')
#
image_tensor = transform_test(image_PIL)
# 以下語句等效於 image_tensor = torch.unsqueeze(image_tensor, 0)
image_tensor.unsqueeze_(0)
# 沒有這句話會報錯
image_tensor = image_tensor.to(device)
out = model(image_tensor)
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in out]).to(device)
print(class_names[pred])
預測結果


實際訓練的過程來看,整體看準確度不高。而經過測試發現,該模型隻能對於貓進行識別,對於狗則會誤判。
五、參考資料
實現貓狗分類
到此這篇關於Python機器學習之基於Pytorch實現貓狗分類的文章就介紹到這瞭,更多相關Pytorch實現貓狗分類內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Pytorch實現圖像識別之數字識別(附詳細註釋)
- pytorch實現加載保存查看checkpoint文件
- Pytorch深度學習之實現病蟲害圖像分類
- PyTorch實現MNIST數據集手寫數字識別詳情
- pytorch從csv加載自定義數據模板的操作