Go語言實現Snowflake雪花算法
每次放長假的在傢裡的時候,總想找點簡單的例子來看看實現原理,這次我們來看看 Go 語言雪花算法。
介紹
有時候在業務中,需要使用一些唯一的ID,來記錄我們某個數據的標識。最常用的無非以下幾種:UUID、數據庫自增主鍵、Redis的Incr命令等方法來獲取一個唯一的值。下面我們分別說一下它們的優劣,以便引出我們的分佈式雪花算法。
雪花算法
雪花算法的原始版本是scala版,用於生成分佈式ID(純數字,時間順序),訂單編號等。
自增ID:對於數據敏感場景不宜使用,且不適合於分佈式場景。 GUID:采用無意義字符串,數據量增大時造成訪問過慢,且不宜排序。
UUID
首先是 UUID ,它是由128位二進制組成,一般轉換成十六進制,然後用String表示。為瞭保證 UUID 的唯一性,規范定義瞭包括網卡MAC地址、時間戳、名字空(Namespace)、隨機或偽隨機數、時序等元素,以及從這些元素生成 UUID 的算法。
UUID 有五個版本:
- 版本1:基於時間戳和mac地址
- 版本2:基於時間戳,mac地址和POSIX UID/GID
- 版本3:基於MD5哈希算法
- 版本4:基於隨機數
- 版本5:基於SHA-1哈希算法
UUID 的優缺點:
優點是代碼簡單,性能比較好。缺點是沒有排序,無法保證按序遞增;其次是太長瞭,存儲數據庫占用空間比較大,不利於檢索和排序。
數據庫自增主鍵
如果是使用 mysql 數據庫,那麼通過設置主鍵為 auto_increment 是最容易實現單調遞增的唯一ID 的方法,並且它也方便排序和索引。
但是缺點也很明顯,由於過度依賴數據庫,那麼受限於數據庫的性能會導致並發性並不高;再來就是如果數據量太大那麼會給分庫分表會帶來問題;並且如果數據庫宕機瞭,那麼這個功能是無法使用的。
Redis
Redis 目前已在很多項目中是一個不可或缺的存在,在 Redis 中有兩個命令 Incr、IncrBy ,因為Redis是單線程的所以通過這兩個指令可以能保證原子性從而達到生成唯一值的目標,並且性能也很好。
但是在 Redis 中,即使有 AOF 和 RDB ,但是依然會存在數據丟失,有可能會造成ID重復;再來就是需要依賴 Redis ,如果它不穩定,那麼會影響 ID 生成。
Snowflake
通過上面的一個個分析,終於引出瞭我們的分佈式雪花算法 Snowflake ,它最早是twitter內部使用的分佈式環境下的唯一ID生成算法。在2014年開源。開源的版本由scala編寫,大傢可以再找個地址找到這版本。
https://github.com/twitter-archive/snowflake/tags
它有以下幾個特點:
- 能滿足高並發分佈式系統環境下ID不重復;
- 基於時間戳,可以保證基本有序遞增;
- 不依賴於第三方的庫或者中間件;
實現原理
Snowflake 結構是一個 64bit 的 int64 類型的數據。如下:
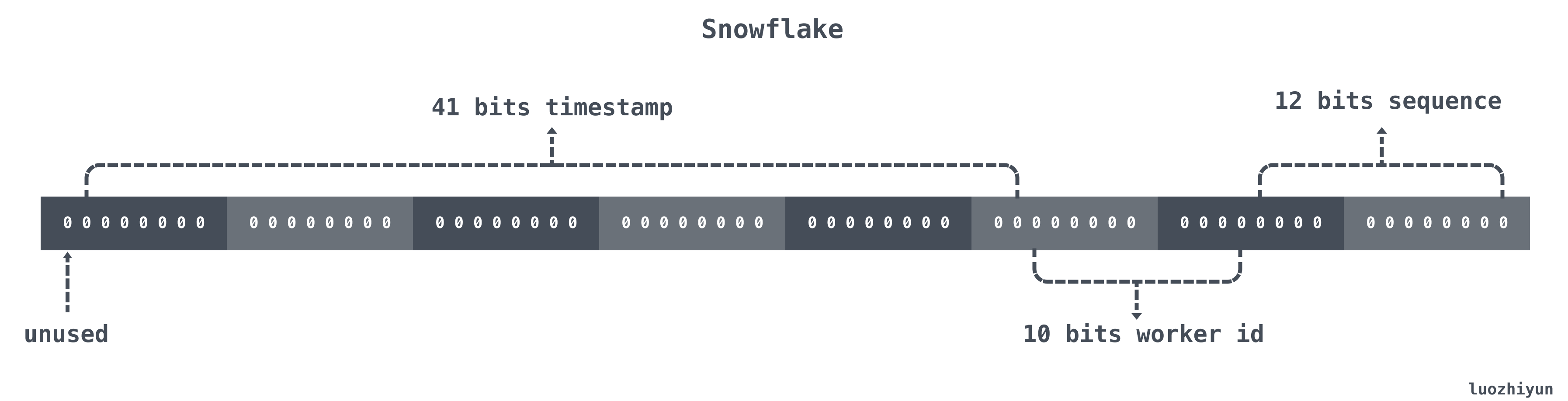
| 位置 | 大小 | 作用 |
|---|---|---|
| 0~11bit | 12bits | 序列號,用來對同一個毫秒之內產生不同的ID,可記錄4095個 |
| 12~21bit | 10bits | 10bit用來記錄機器ID,總共可以記錄1024臺機器 |
| 22~62bit | 41bits | 用來記錄時間戳,這裡可以記錄69年 |
| 63bit | 1bit | 符號位,不做處理 |
上面隻是一個將 64bit 劃分的通用標準,一般的情況可以根據自己的業務情況進行調整。例如目前業務隻有機器10臺左右預計未來會增加到三位數,並且需要進行多機房部署,QPS 幾年之內會發展到百萬。
那麼對於百萬 QPS 平分到 10 臺機器上就是每臺機器承擔十萬級的請求即可,12 bit 的序列號完全夠用。對於未來會增加到三位數機器,並且需要多機房部署的需求我們僅需要將 10 bits 的 work id 進行拆分,分割 3 bits 來代表機房數共代表可以部署8個機房,其他 7bits 代表機器數代表每個機房可以部署128臺機器。那麼數據格式就會如下所示:

代碼實現
實現步驟
其實看懂瞭上面的數據結構之後,需要自己實現一個雪花算法是非常簡單,步驟大致如下:
- 獲取當前的毫秒時間戳;
- 用當前的毫秒時間戳和上次保存的時間戳進行比較;
- 如果和上次保存的時間戳相等,那麼對序列號 sequence 加一;
- 如果不相等,那麼直接設置 sequence 為 0 即可;
- 然後通過或運算拼接雪花算法需要返回的 int64 返回值。
代碼實現
首先我們需要定義一個 Snowflake 結構體:
type Snowflake struct {
sync.Mutex // 鎖
timestamp int64 // 時間戳 ,毫秒
workerid int64 // 工作節點
datacenterid int64 // 數據中心機房id
sequence int64 // 序列號
}
然後我們需要定義一些常量,方便我們在使用雪花算法的時候進行位運算取值:
const ( epoch = int64(1577808000000) // 設置起始時間(時間戳/毫秒):2020-01-01 00:00:00,有效期69年 timestampBits = uint(41) // 時間戳占用位數 datacenteridBits = uint(2) // 數據中心id所占位數 workeridBits = uint(7) // 機器id所占位數 sequenceBits = uint(12) // 序列所占的位數 timestampMax = int64(-1 ^ (-1 << timestampBits)) // 時間戳最大值 datacenteridMax = int64(-1 ^ (-1 << datacenteridBits)) // 支持的最大數據中心id數量 workeridMax = int64(-1 ^ (-1 << workeridBits)) // 支持的最大機器id數量 sequenceMask = int64(-1 ^ (-1 << sequenceBits)) // 支持的最大序列id數量 workeridShift = sequenceBits // 機器id左移位數 datacenteridShift = sequenceBits + workeridBits // 數據中心id左移位數 timestampShift = sequenceBits + workeridBits + datacenteridBits // 時間戳左移位數 )
需要註意的是由於 -1 在二進制上表示是:
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111
所以想要求得 41bits 的 timestamp 最大值可以將 -1 向左位移 41 位,得到:
11111111 11111111 11111110 00000000 00000000 00000000 00000000 00000000
那麼再和 -1 進行 ^異或運算:
00000000 00000000 00000001 11111111 11111111 11111111 11111111 11111111
這就可以表示 41bits 的 timestamp 最大值。datacenteridMax、workeridMax也同理。
接著我們就可以設置一個 NextVal 函數來獲取 Snowflake 返回的 ID 瞭:
func (s *Snowflake) NextVal() int64 {
s.Lock()
now := time.Now().UnixNano() / 1000000 // 轉毫秒
if s.timestamp == now {
// 當同一時間戳(精度:毫秒)下多次生成id會增加序列號
s.sequence = (s.sequence + 1) & sequenceMask
if s.sequence == 0 {
// 如果當前序列超出12bit長度,則需要等待下一毫秒
// 下一毫秒將使用sequence:0
for now <= s.timestamp {
now = time.Now().UnixNano() / 1000000
}
}
} else {
// 不同時間戳(精度:毫秒)下直接使用序列號:0
s.sequence = 0
}
t := now - epoch
if t > timestampMax {
s.Unlock()
glog.Errorf("epoch must be between 0 and %d", timestampMax-1)
return 0
}
s.timestamp = now
r := int64((t)<<timestampShift | (s.datacenterid << datacenteridShift) | (s.workerid << workeridShift) | (s.sequence))
s.Unlock()
return r
}
上面的代碼也是非常的簡單,看看註釋應該也能懂,我這裡說說最後返回的 r 系列的位運算表示什麼意思。
首先 t 表示的是現在距離 epoch 的時間差,我們 epoch 在初始化的時候設置的是2020-01-01 00:00:00,那麼對於 41bit 的 timestamp 來說會在 69 年之後才溢出。對 t 進行向左位移之後,低於 timestampShift 位置上全是0 ,由 datacenterid、workerid、sequence 進行取或填充。
在當前的例子中,如果當前時間是2021/01/01 00:00:00,那麼位運算結果如下圖所示:

到此這篇關於Go語言實現Snowflake雪花算法的文章就介紹到這瞭,更多相關Go語言雪花算法內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Java實現雪花算法的原理
- Java收集的雪花算法代碼詳解
- 詳解Java中雪花算法的實現
- PHP利用雪花(SnowFlake)算法生成唯一ID
- mybatis-plus雪花算法自動生成機器id原理及源碼