Python爬取你好李煥英豆瓣短評生成詞雲的示例代碼
爬取過程:
你好,李煥英 短評的URL:
https://movie.douban.com/subject/34841067/comments?start=20&limit=20&status=P&sort=new_score
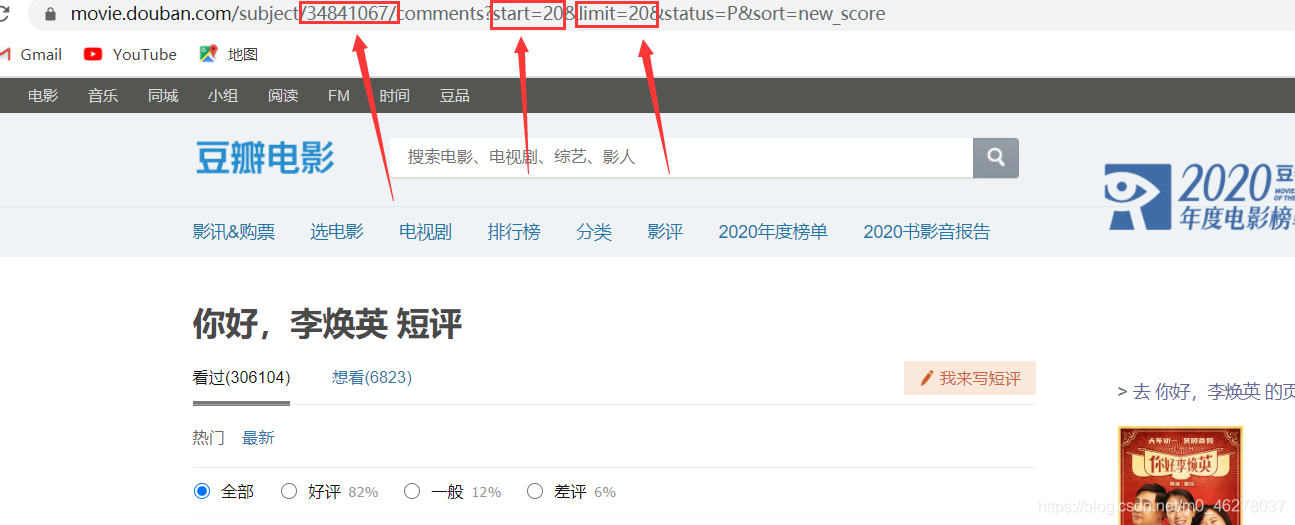
分析要爬取的URL;
34841067:電影ID
start=20:開始頁面
limit=20:每頁評論條數
代碼:
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P % (movie_id, (i - 1) * 20)
在谷歌瀏覽器中按F12進入開發者調試模式,查看源代碼,找到短評的代碼位置,查看位於哪個div,哪個標簽下:
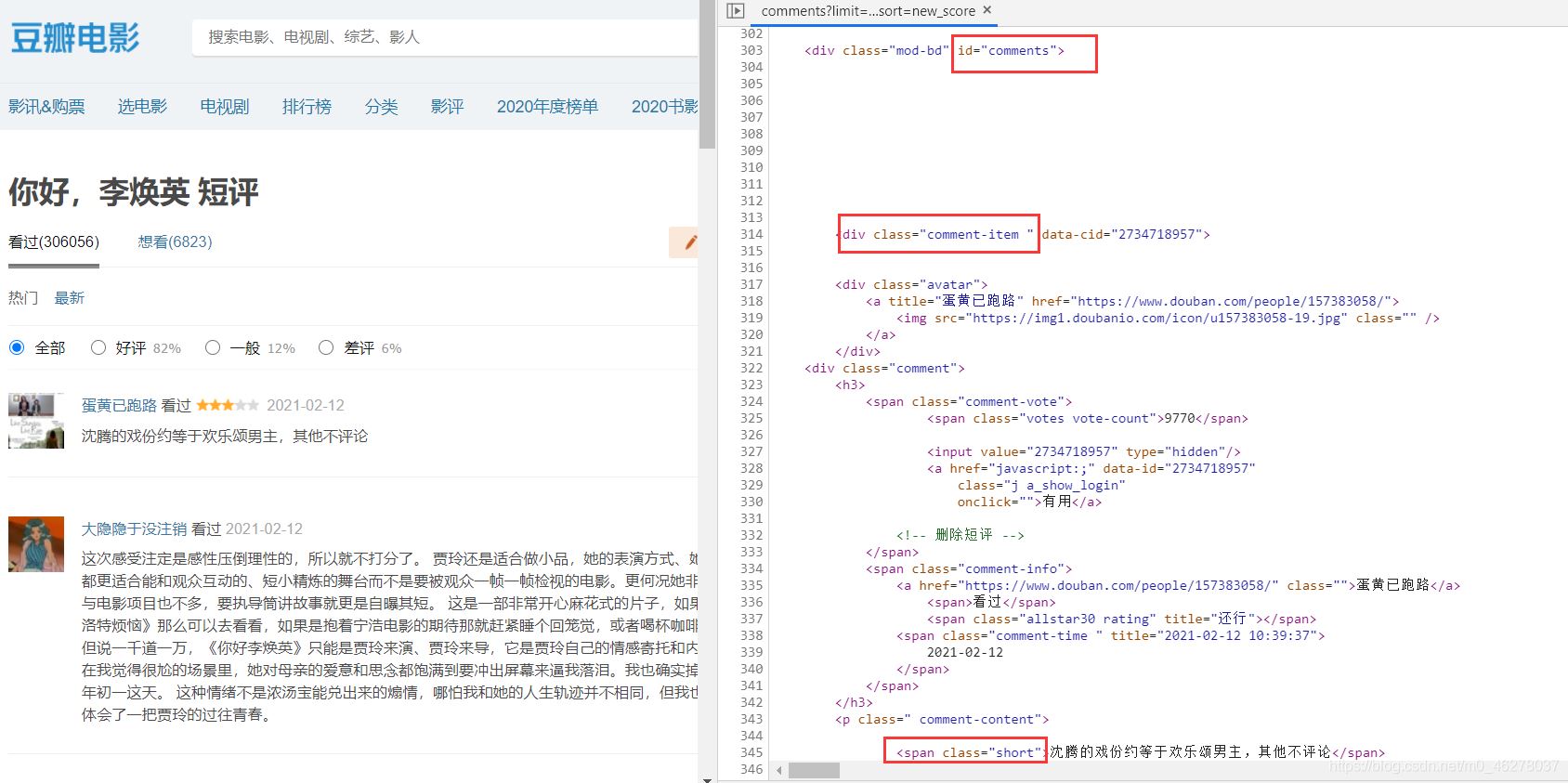
可以看到評論在div[id=‘comments’]下的div[class=‘comment-item’]中的第一個span[class=‘short’]中,使用正則表達式提取短評內容,即代碼為:
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \
% (movie_id, (i - 1) * 20)
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
comments = re.findall('<span class="short">(.*)</span>', req.text)
背景圖:

生成的詞雲:

完整代碼:
import re
from PIL import Image
import requests
import jieba
import matplotlib.pyplot as plt
import numpy as np
from os import path
from wordcloud import WordCloud, STOPWORDS
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0'
}
d = path.dirname(__file__)
def spider_comment(movie_id, page):
"""
爬取評論
:param movie_id: 電影ID
:param page: 爬取前N頁
:return: 評論內容
"""
comment_list = []
for i in range(page):
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P&percent_type=' \
% (movie_id, (i - 1) * 20)
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
comment_list = re.findall('<span class="short">(.*)</span>', req.text)
print("當前頁數:%s,總評論數:%s" % (i, len(comment_list)))
return comment_list
def wordcloud(comment_list):
wordlist = jieba.lcut(' '.join(comment_list))
text = ' '.join(wordlist)
print(text)
# 調用包PIL中的open方法,讀取圖片文件,通過numpy中的array方法生成數組
backgroud_Image = np.array(Image.open(path.join(d, "wordcloud.png")))
wordcloud = WordCloud(
font_path="simsun.ttc",
background_color="white",
mask=backgroud_Image, # 設置背景圖片
stopwords=STOPWORDS,
width=2852,
height=2031,
margin=2,
max_words=6000, # 設置最大顯示的字數
#stopwords={'企業'}, # 設置停用詞,停用詞則不再詞雲圖中表示
max_font_size=250, # 設置字體最大值
random_state=1, # 設置有多少種隨機生成狀態,即有多少種配色方案
scale=1) # 設置生成的詞雲圖的大小
# 傳入需畫詞雲圖的文本
wordcloud.generate(text)
wordcloud.to_image()
wordcloud.to_file("cloud.png")
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 主函數
if __name__ == '__main__':
movie_id = '34841067'
page = 11
comment_list = spider_comment(movie_id, page)
wordcloud(comment_list)
WordCloud各含義參數如下:
font_path : string #字體路徑,需要展現什麼字體就把該字體路徑+後綴名寫上,如:font_path = '黑體.ttf'
width : int (default=400) #輸出的畫佈寬度,默認為400像素
height : int (default=200) #輸出的畫佈高度,默認為200像素
prefer_horizontal : float (default=0.90) #詞語水平方向排版出現的頻率,默認 0.9 (所以詞語垂直方向排版出現頻率為 0.1 )
mask : nd-array or None (default=None) #如果參數為空,則使用二維遮罩繪制詞雲。如果 mask 非空,設置的寬高值將被忽略,遮罩形狀被 mask 取代。除全白(#FFFFFF)的部分將不會繪制,其餘部分會用於繪制詞雲。如:bg_pic = imread('讀取一張圖片.png'),背景圖片的畫佈一定要設置為白色(#FFFFFF),然後顯示的形狀為不是白色的其他顏色。可以用ps工具將自己要顯示的形狀復制到一個純白色的畫佈上再保存,就ok瞭。
scale : float (default=1) #按照比例進行放大畫佈,如設置為1.5,則長和寬都是原來畫佈的1.5倍
min_font_size : int (default=4) #顯示的最小的字體大小
font_step : int (default=1) #字體步長,如果步長大於1,會加快運算但是可能導致結果出現較大的誤差
max_words : number (default=200) #要顯示的詞的最大個數
stopwords : set of strings or None #設置需要屏蔽的詞,如果為空,則使用內置的STOPWORDS
background_color : color value (default=”black”) #背景顏色,如background_color='white',背景顏色為白色
max_font_size : int or None (default=None) #顯示的最大的字體大小
mode : string (default=”RGB”) #當參數為“RGBA”並且background_color不為空時,背景為透明
relative_scaling : float (default=.5) #詞頻和字體大小的關聯性
color_func : callable, default=None #生成新顏色的函數,如果為空,則使用 self.color_func
regexp : string or None (optional) #使用正則表達式分隔輸入的文本
collocations : bool, default=True #是否包括兩個詞的搭配
colormap : string or matplotlib colormap, default=”viridis” #給每個單詞隨機分配顏色,若指定color_func,則忽略該方法
random_state : int or None #為每個單詞返回一個PIL顏色
fit_words(frequencies) #根據詞頻生成詞雲
generate(text) #根據文本生成詞雲
generate_from_frequencies(frequencies[, ...]) #根據詞頻生成詞雲
generate_from_text(text) #根據文本生成詞雲
process_text(text) #將長文本分詞並去除屏蔽詞(此處指英語,中文分詞還是需要自己用別的庫先行實現,使用上面的 fit_words(frequencies) )
recolor([random_state, color_func, colormap]) #對現有輸出重新著色。重新上色會比重新生成整個詞雲快很多
to_array() #轉化為 numpy array
to_file(filename) #輸出到文件
到此這篇關於Python爬取你好李煥英豆瓣短評生成詞雲的文章就介紹到這瞭,更多相關Python爬取豆瓣短評內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python 爬取豆瓣電影短評並利用wordcloud生成詞雲圖
- Python將QQ聊天記錄生成詞雲的示例代碼
- Python詞雲的正確實現方法實例
- Python7個爬蟲小案例詳解(附源碼)中篇
- 用Python采集《雪中悍刀行》彈幕做成詞雲實例