Zabbix 動態執行監控采集腳本的實現原理
在使用Zabbix自定義腳本采集監控數據的時候,通常會遇到以下一些問題:
- 服務器擴容之後,監控腳本如何部署到新的服務器上?
- 監控腳本需要修改時,如何自動修改所有相同的監控腳本?
- 如何備份監控采集腳本避免因服務器異常後丟失?
- 新部署自定義監控,如何避免系統管理員過多操作?
- 如何避免大量研發就能解決上述的問題?
實現原理:使用文件服務器統一存放和管理監控腳本,在zabbix agent預埋通用腳本,根據zabbix server傳輸的Key和參數,從文件服務器拉取腳本執行後返回數據。
架構設計:
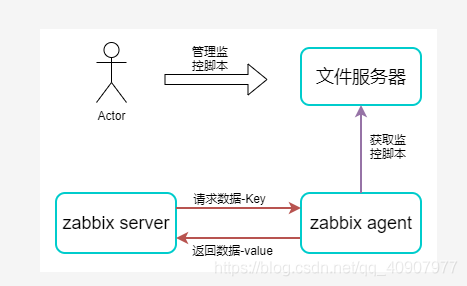
具體實現:
1.搭建文件服務器,以nginx作為文件服務器為例
修改nginx的配置並重啟
erver {
listen 8080;
server_name zabbix;
root /usr/local/static/;
location / {
autoindex on;
autoindex_exact_size on;
autoindex_localtime on;
charset utf-8;
}
}
2.編寫文件拉取和執行的腳本
url="http://192.168.24.108:8080/" #定義文件服務器的URL parentDir="/usr/local/zabbix/bin/zabbix_script" file_directory=$parentDir/$1 #定義本地存放執行腳本的目錄 file_name=$2 #腳本名稱 file_path=$1/$2 #拼接文件服務器的腳本路徑 if [ ! -d $file_directory ];then #判斷文件目錄是否存在 mkdir -p $file_directory fi if [ ! -f $parentDir/$file_path ];then #判斷腳本是否已經存在 wget -P $file_directory $url$file_path 2>>log fi timestamp=$(date +%s) filetimestamp=$(stat -c %Y $parentDir/$file_path) if [ $[$timestamp - $filetimestamp] -gt 3600 ];then #判斷當前時間與腳本修改時間的大小,3600秒更新一次 wget $url$file_path -O $parentDir/$file_path 2>>log #覆蓋腳本 touch -c $parentDir/$file_path #修改腳本的修改時間 fi python $parentDir/$file_path $3 #執行腳本
3.增加zabbix的配置文件
UserParameter=requests_file[*],sh /usr/local/zabbix/bin/zabbix_script/requests_file.sh $1 $2 $3
4.重啟zabbix agent
5.編寫測試腳本,並上傳到文件服務器指定目錄
#監控服務器連接數 #!/usr/bin/python import pwd import os,sys import re import glob state = sys.argv[1] cmd = "netstat -an | grep " + state + " | wc -l" os.system(cmd)
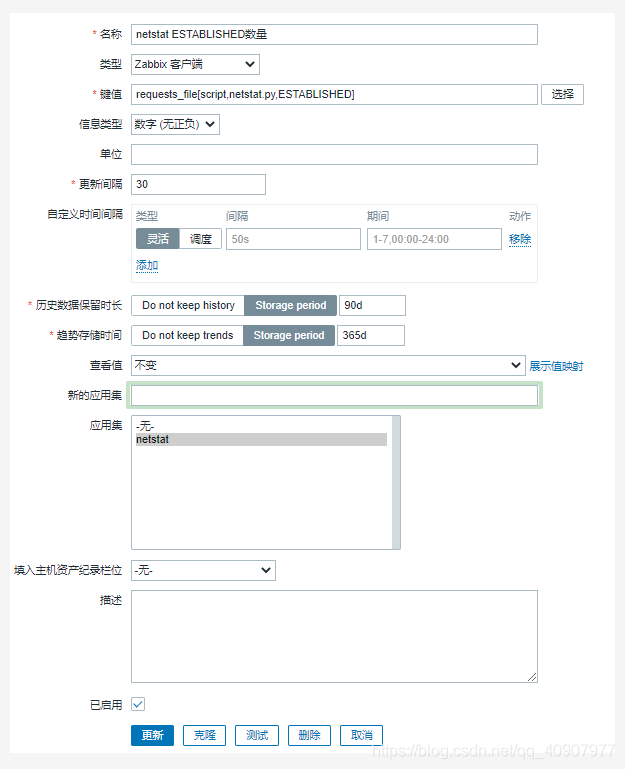
6.配置zabbix頁面的監控項:
7.觀察數據是否正常 :

8.新的監控腳本放在文件服務器之後,可直接配置頁面的監控項進行數據采集

本文著重提供瞭一個zabbix自定義監控腳本集中管理的解決思路,可根據這個思路自由拓展更簡潔、高效的zabbix使用方法,進一步讓運維變得簡單。
參考鏈接 :
Zabbix 如何動態執行監控采集腳本 : https://mp.weixin.qq.com/s/ikuCSYhlFdtiAmt7epskWw
到此這篇關於Zabbix 動態執行監控采集腳本的實現原理的文章就介紹到這瞭,更多相關Zabbix 動態執行監控采集腳本內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- zabbix-agent在麒麟V10上的安裝過程
- Nginx 禁止直接訪問目錄或文件的操作方法
- 使用zabbix監控oracle數據庫的方法詳解
- 構建雙vip的高可用MySQL集群
- zabbix 代理服務器的部署與 zabbix-snmp 監控問題