OpenCV-Python 實現兩張圖片自動拼接成全景圖
背景介紹
圖片的全景拼接如今已不再稀奇,現在的智能攝像機和手機攝像頭基本都帶有圖片自動全景拼接的功能,但是一般都會要求拍攝者保持設備的平穩以及單方向的移動取景以實現較好的拼接結果。這是因為拼接的圖片之間必須要有相似的區域以保證拼接結果的準確性和完整性。本文主要簡單描述如何用 Python 和 OpenCV 庫實現兩張圖片的自動拼合,首先簡單介紹一下兩張圖片拼接的原理。
基本原理
要實現兩張圖片的簡單拼接,其實隻需找出兩張圖片中相似的點 (至少四個,因為 homography 矩陣的計算需要至少四個點), 計算一張圖片可以變換到另一張圖片的變換矩陣 (homography 單應性矩陣),用這個矩陣把那張圖片變換後放到另一張圖片相應的位置 ( 就是相當於把兩張圖片中定好的四個相似的點給重合在一起)。如此,就可以實現簡單的全景拼接。當然,因為拼合之後圖片會重疊在一起,所以需要重新計算圖片重疊部分的像素值,否則結果會很難看。所以總結起來其實就兩個步驟:
1. 找兩張圖片中相似的點,計算變換矩陣
2. 變換一張圖片放到另一張圖片合適的位置,並計算重疊區域新的像素值 (這裡就是圖片融合所需要采取的策略)
具體實現
尋找相似點
當然,我們可以手動的尋找相似的點,但是這樣比較麻煩。因為相似點越多或者相似點對應的位置越準確,所得的結果就越好,但是人的肉眼所找的位置總是有誤差的,而且找出很多的點也不是一件容易的事。所以就有聰明的人設計瞭自動尋找相似點的算法,這裡我們就用瞭 SIFT 算法,而 OpenCV 也給我們提供 SIFT 算法的接口,所以我們就不需要自己費力去實現瞭。如下是兩張測試圖片的原圖和找出相似點後的圖片。



其中紅色的點是 SIFT 算法找出的相似點,而綠色的線表示的是在所有找出的相似的點中所篩選出的可信度更高的相似的點。因為算法找出的相似點並不一定是百分百正確的。然後就可以根據這些篩選出的相似點計算變換矩陣,當然 OpenCV 也提供瞭相應的接口方便我們的計算,而具體的代碼實現也可以在 OpenCV 的 Python tutorial 中找到 [1]。
圖片拼接
計算出變換矩陣後,接下來就是第二步,用計算出的變換矩陣對其中一張圖做變換,然後把變換的圖片與另一張圖片重疊在一起,並重新計算重疊區域新的像素值。對於計算重疊區域的像素值,其實可以有多種方法去實現一個好的融合效果,這裡就用最簡單粗暴的但效果也不錯的方式。直白來說就是實現一個圖像的線性漸變,對於重疊的區域,靠近左邊的部分,讓左邊圖像內容顯示的多一些,靠近右邊的部分,讓右邊圖像的內容顯示的多一些。用公式表示就是,假設 alpha 表示像素點橫坐標到左右重疊區域邊界橫坐標的距離,新的像素值就為 newpixel = 左圖像素值 × (1 – alpha) + 右圖像素值 × alpha 。這樣就可以實現一個簡單的融合效果,如果想實現更復雜或更好的效果,可以去搜索和嘗試一下 multi-band 融合,這裡就不過多贅述瞭。最後附上實現的結果和代碼,可供參考。
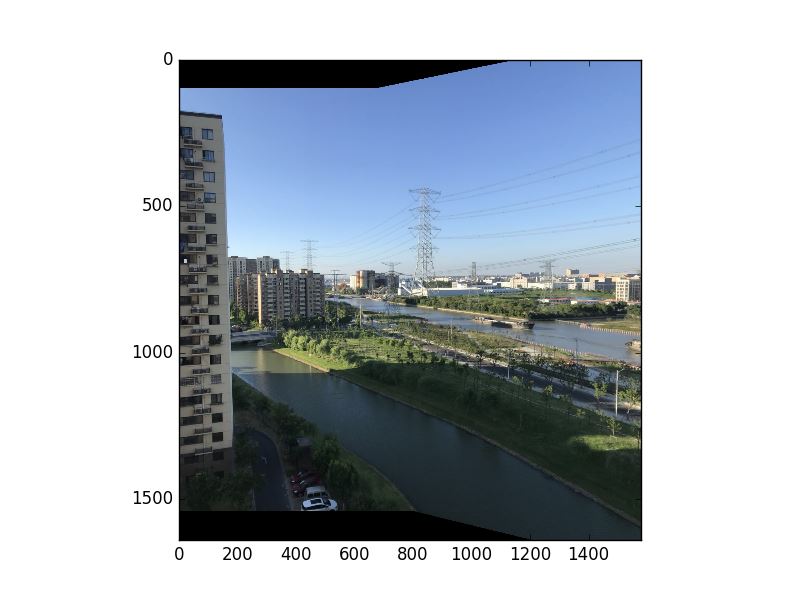
Python 代碼如下:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
if __name__ == '__main__':
top, bot, left, right = 100, 100, 0, 500
img1 = cv.imread('test1.jpg')
img2 = cv.imread('test2.jpg')
srcImg = cv.copyMakeBorder(img1, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0))
testImg = cv.copyMakeBorder(img2, top, bot, left, right, cv.BORDER_CONSTANT, value=(0, 0, 0))
img1gray = cv.cvtColor(srcImg, cv.COLOR_BGR2GRAY)
img2gray = cv.cvtColor(testImg, cv.COLOR_BGR2GRAY)
sift = cv.xfeatures2d_SIFT().create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1gray, None)
kp2, des2 = sift.detectAndCompute(img2gray, None)
# FLANN parameters
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# Need to draw only good matches, so create a mask
matchesMask = [[0, 0] for i in range(len(matches))]
good = []
pts1 = []
pts2 = []
# ratio test as per Lowe's paper
for i, (m, n) in enumerate(matches):
if m.distance < 0.7*n.distance:
good.append(m)
pts2.append(kp2[m.trainIdx].pt)
pts1.append(kp1[m.queryIdx].pt)
matchesMask[i] = [1, 0]
draw_params = dict(matchColor=(0, 255, 0),
singlePointColor=(255, 0, 0),
matchesMask=matchesMask,
flags=0)
img3 = cv.drawMatchesKnn(img1gray, kp1, img2gray, kp2, matches, None, **draw_params)
plt.imshow(img3, ), plt.show()
rows, cols = srcImg.shape[:2]
MIN_MATCH_COUNT = 10
if len(good) > MIN_MATCH_COUNT:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC, 5.0)
warpImg = cv.warpPerspective(testImg, np.array(M), (testImg.shape[1], testImg.shape[0]), flags=cv.WARP_INVERSE_MAP)
for col in range(0, cols):
if srcImg[:, col].any() and warpImg[:, col].any():
left = col
break
for col in range(cols-1, 0, -1):
if srcImg[:, col].any() and warpImg[:, col].any():
right = col
break
res = np.zeros([rows, cols, 3], np.uint8)
for row in range(0, rows):
for col in range(0, cols):
if not srcImg[row, col].any():
res[row, col] = warpImg[row, col]
elif not warpImg[row, col].any():
res[row, col] = srcImg[row, col]
else:
srcImgLen = float(abs(col - left))
testImgLen = float(abs(col - right))
alpha = srcImgLen / (srcImgLen + testImgLen)
res[row, col] = np.clip(srcImg[row, col] * (1-alpha) + warpImg[row, col] * alpha, 0, 255)
# opencv is bgr, matplotlib is rgb
res = cv.cvtColor(res, cv.COLOR_BGR2RGB)
# show the result
plt.figure()
plt.imshow(res)
plt.show()
else:
print("Not enough matches are found - {}/{}".format(len(good), MIN_MATCH_COUNT))
matchesMask = None
Reference
[1] OpenCV tutorial: https://docs.opencv.org/3.4.1/d1/de0/tutorial_py_feature_homography.html
到此這篇關於OpenCV-Python 實現兩張圖片自動拼接成全景圖的文章就介紹到這瞭,更多相關OpenCV 圖片自動拼接成全景圖內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python OpenCV學習之特征點檢測與匹配詳解
- Opencv Python實現兩幅圖像匹配
- 基於Python和openCV實現圖像的全景拼接詳細步驟
- OpenCV全景圖像拼接的實現示例
- PyQt5實現將Matplotlib圖像嵌入到Scoll Area中顯示滾動條效果