快速一鍵生成Python爬蟲請求頭
今天介紹個神奇的網站!堪稱爬蟲偷懶的神器!
我們在寫爬蟲,構建網絡請求的時候,不可避免地要添加請求頭( headers ),以 mdn 學習區為例,我們的請求頭是這樣的:
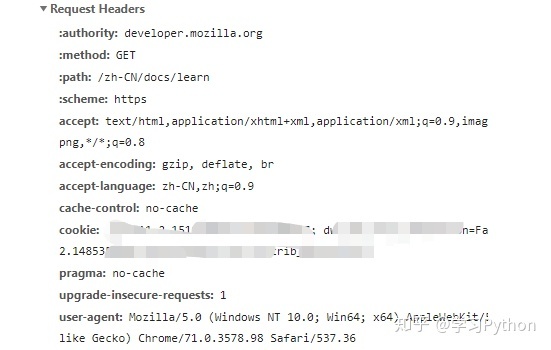
一般來說,我們隻要添加 user-agent 就能滿足絕大部分需求瞭,Python 代碼如下:
import requests
headers = {
#'authority': 'developer.mozilla.org',
#'pragma': 'no-cache',
#'cache-control': 'no-cache',
#'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 YaBrowser/19.7.0.1635 Yowser/2.5 Safari/537.36',
#'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
#'accept-encoding': 'gzip, deflate, br',
#'accept-language': 'zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6',
#'cookie': 你的cookie,
}
response = requests.get('https://developer.mozilla.org/zh-CN/docs/learn', headers=headers)
但是有些請求,我們要把特定的 headers 參數添加上才能獲得正確的網絡響應,不知道哪個參數是必要的情況下,就要先把所有參數都添加上,再逐個排除。
但是手動復制粘貼 headers 字典裡的每一個鍵值對太費事瞭
一個不那麼方便的解決方案:
用正則表達式或者直接字符串替換,把 headers 字符串直接轉化為字典,封裝成函數方便以後反復調用。
有的人喜歡用這種方法,每次復制headers信息,然後調用自己封裝好的函數,但我覺得還是挺麻煩的。
那麼還有沒有快速一鍵生成 Python 爬蟲請求頭的方法呢?
這裡給大傢介紹兩個:
- 網站在線轉換
- Postman
實戰演練
抓取網站:https://developer.mozilla.org…
網站在線轉換
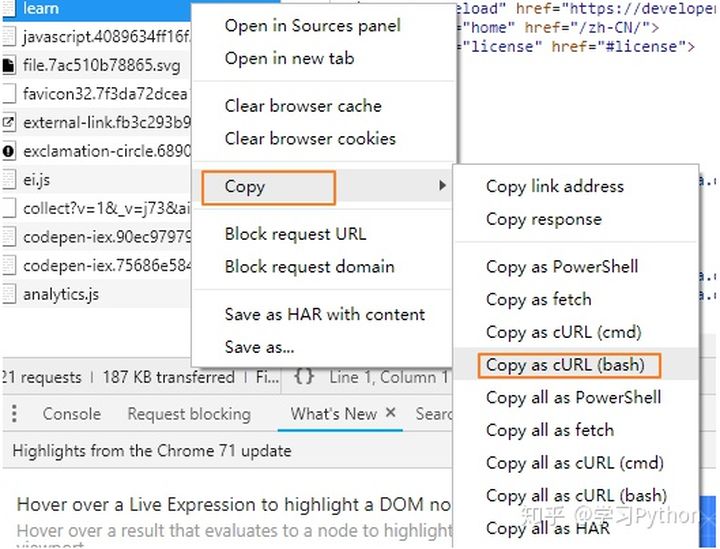
1,Chrome 打開開發者選項( f12 )—> network 選項卡 —> 刷新頁面,獲取請求 —> 找到頁面信息對應的請求 (通過請求的名稱、後綴和 response 內容來判斷)

2,右鍵,copy —> copy as cURL (bash),註意不是【copy as cURL (cmd)】
3,打開網站,https://curl.trillworks.com/,粘貼 cURL (bash) 到左邊 curl command,右邊會自動出 Python 代碼

4,生成代碼如下圖

5,print ( response.text ) 就可以直接打印網頁源代碼啦!
Postman
1,下載 postman ( Chrome 也有個 postman 的插件,操作應該差不多)
2,打開 postman,彈出的界面可以直接關掉
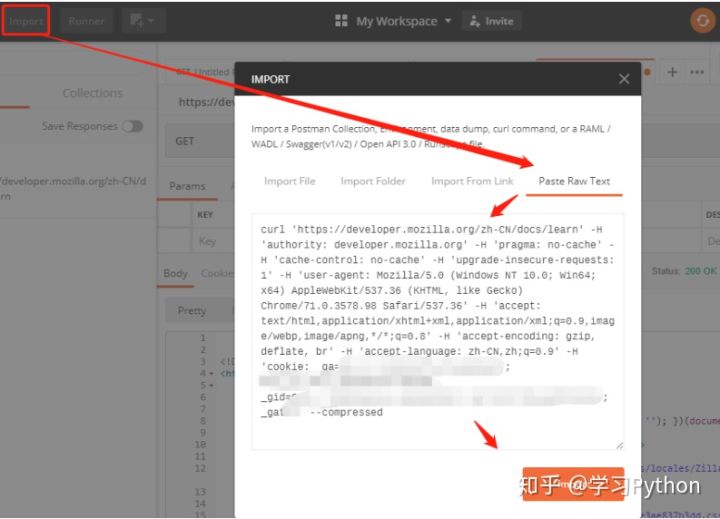
3,import –> paste raw text,在 Chrome 裡復制 curl (bash),粘貼到下面的對話框裡,點擊 import 按鈕
4,點擊 send,模擬網絡請求,下方可查看源代碼
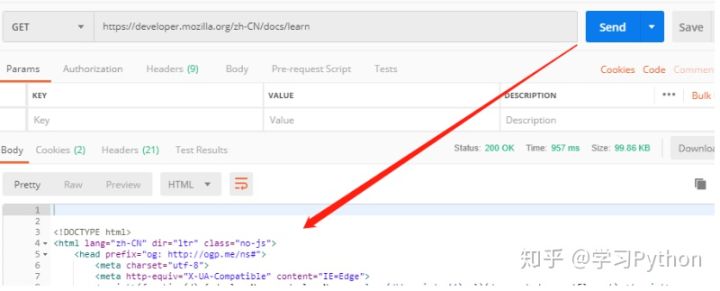
5,確保源代碼正常後,點擊 code
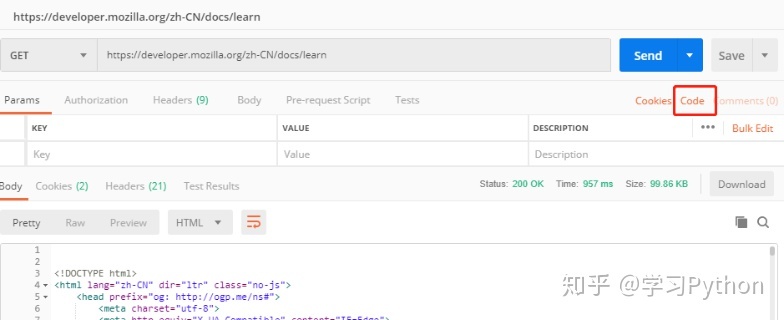
6,左上角可以選擇編程語言,右上角復制到剪貼板

大功告成!
其實我本人平時都是用第一種,網站比較穩定,基本沒出現過異常;有瞭這個神器就不用自己再構造請求頭瞭,先一鍵生成,然後再根據需求調一調就好瞭,幾秒鐘就搞定瞭。
以上就是快速一鍵生成Python爬蟲請求頭的詳細內容,更多關於快速一鍵生成Python爬蟲請求頭的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- 還在手動蓋樓抽獎?教你用Python實現自動評論蓋樓抽獎(一)
- python爬蟲用request庫處理cookie的實例講解
- python3 requests 各種發送方式詳解
- Python音樂爬蟲完美繞過反爬
- requests在python中發送請求的實例講解