python中pandas對多列進行分組統計的實現
使用groupby([ ]).size()統計的結果,值相同的字段值會不顯示
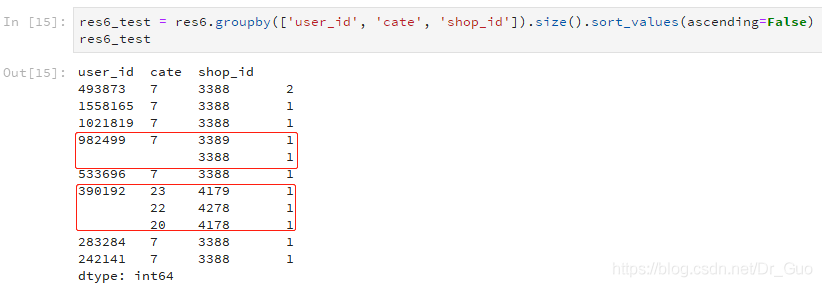
如上圖所示,第一個空著的行是982499 7 3388 1,因為此行與前面一行的這兩個字段值是一樣的,所以不顯示。第二個空著的行是390192 22 4278 1,因為此行與前面一行的第一個字段值是一樣的,所以不顯示。這樣的展示方式更直觀,但對於剛用的人,可能會讓其以為是缺失值。
如果還不明白可以看下面的全部數據及操作。
import pandas as pd
res6 = pd.read_csv('test.csv')
res6.shape
(12, 3)
res6.columns
Index(['user_id', 'cate', 'shop_id'], dtype='object')
res6.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 12 entries, 0 to 11 Data columns (total 3 columns): user_id 12 non-null int64 cate 12 non-null int64 shop_id 12 non-null int64 dtypes: int64(3) memory usage: 368.0 bytes
res6.describe()
| user_id | cate | shop_id | |
|---|---|---|---|
| count | 1.200000e+01 | 12.000000 | 12.000000 |
| mean | 6.468688e+05 | 10.666667 | 3594.000000 |
| std | 3.988181e+05 | 6.665151 | 373.271775 |
| min | 2.421410e+05 | 7.000000 | 3388.000000 |
| 25% | 3.901920e+05 | 7.000000 | 3388.000000 |
| 50% | 4.938730e+05 | 7.000000 | 3388.000000 |
| 75% | 9.824990e+05 | 10.250000 | 3586.250000 |
| max | 1.558165e+06 | 23.000000 | 4278.000000 |
res6
| user_id | cate | shop_id | |
|---|---|---|---|
| 0 | 390192 | 20 | 4178 |
| 1 | 390192 | 23 | 4179 |
| 2 | 390192 | 22 | 4278 |
| 3 | 1021819 | 7 | 3388 |
| 4 | 242141 | 7 | 3388 |
| 5 | 283284 | 7 | 3388 |
| 6 | 1558165 | 7 | 3388 |
| 7 | 533696 | 7 | 3388 |
| 8 | 982499 | 7 | 3388 |
| 9 | 493873 | 7 | 3388 |
| 10 | 493873 | 7 | 3388 |
| 11 | 982499 | 7 | 3389 |
res6['user_id'].value_counts()
390192 3 982499 2 493873 2 242141 1 1021819 1 533696 1 1558165 1 283284 1 Name: user_id, dtype: int64
res6.groupby(['user_id']).size().sort_values(ascending=False)
user_id 390192 3 982499 2 493873 2 1558165 1 1021819 1 533696 1 283284 1 242141 1 dtype: int64
res6.groupby(['user_id', 'cate']).size().sort_values(ascending=False)
user_id cate
982499 7 2
493873 7 2
1558165 7 1
1021819 7 1
533696 7 1
390192 23 1
22 1
20 1
283284 7 1
242141 7 1
dtype: int64
res6_test = res6.groupby(['user_id', 'cate', 'shop_id']).size().sort_values(ascending=False) res6_test
user_id cate shop_id
493873 7 3388 2
1558165 7 3388 1
1021819 7 3388 1
982499 7 3389 1
3388 1
533696 7 3388 1
390192 23 4179 1
22 4278 1
20 4178 1
283284 7 3388 1
242141 7 3388 1
dtype: int64
到此這篇關於python中pandas對多列進行分組統計的實現的文章就介紹到這瞭,更多相關pandas多列分組統計內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python 用pandas實現數據透視表功能
- Pandas數據分析-pandas數據框的多層索引
- pandas groupby分組對象的組內排序解決方案
- python數據處理67個pandas函數總結看完就用
- pandas數據分組groupby()和統計函數agg()的使用