Hadoop運行時遇到java.io.FileNotFoundException錯誤的解決方法
報錯信息:
java.lang.Exception: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:529)
Caused by: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376)
at org.apache.hadoop.mapred.LocalJobRunner$Job$ReduceTaskRunnable.run(LocalJobRunner.java:319)
at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)
at java.util.concurrent.FutureTask.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
Caused by: java.io.FileNotFoundException: G:/tmp/hadoop-Ferdinand%20Wang/mapred/local/localRunner/Ferdinand%20Wang/jobcache/job_local938878567_0001/attempt_local938878567_0001_m_000000_0/output/file.out.index
at org.apache.hadoop.fs.RawLocalFileSystem.open(RawLocalFileSystem.java:198)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:766)
at org.apache.hadoop.io.SecureIOUtils.openFSDataInputStream(SecureIOUtils.java:156)
at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:70)
at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:62)
at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:57)
at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.copyMapOutput(LocalFetcher.java:124)
at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.doCopy(LocalFetcher.java:102)
at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.run(LocalFetcher.java:85)
大概是說,reduce的過程失敗瞭,錯誤發生在error in shuffle in localfetcher#1,是因為找不到在tmp/hadoop-username目錄下的一個文件導致。
原因:
電腦用戶名含有空格
G:/tmp/hadoop-Ferdinand%20Wang/mapred/local/localRunner/Ferdinand%20Wang/jobcache/job_local938878567_0001/attempt_local938878567_0001_m_000000_0/output/file.out.index
到具體目錄看果然找不到這個文件,問題就出在這個%20其實是空格,但是這裡不允許出現空格。所以我們要修改用戶名稱才能解決這個問題。
雖然之前在hadoop-env.cmd這個文件中修改瞭,用雙引號的方式可以不出現空格可以讓hadoop正常啟動,但是治標不治本啊。還是修改一下用戶名,改瞭以後這個就還是用username就可以。
@rem A string representing this instance of hadoop. %USERNAME% by default. set HADOOP_IDENT_STRING=%USERNAME%
修改username的方法:
1、【win】+【R】快捷鍵調出運行;
2、輸入netplwiz,再點擊確定;
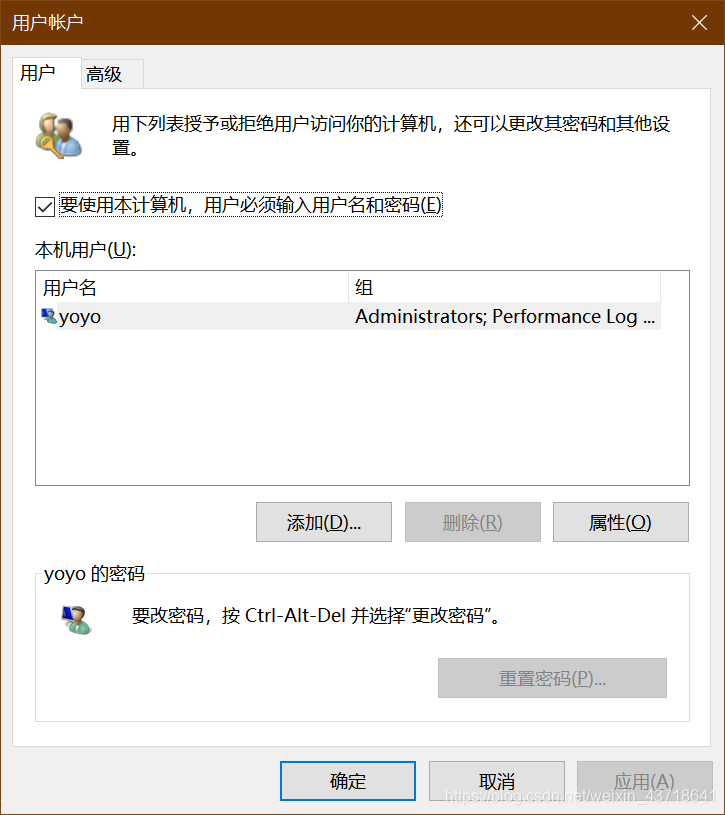
3、打開用戶賬戶,雙擊;
4、輸入您想要改的名字;
5、點擊右下角的【確定】按鈕之後,彈出警告,點擊【是】即可。
6、重啟電腦。(一定要重啟)
重新啟動,發現新上傳的這裡也改瞭。
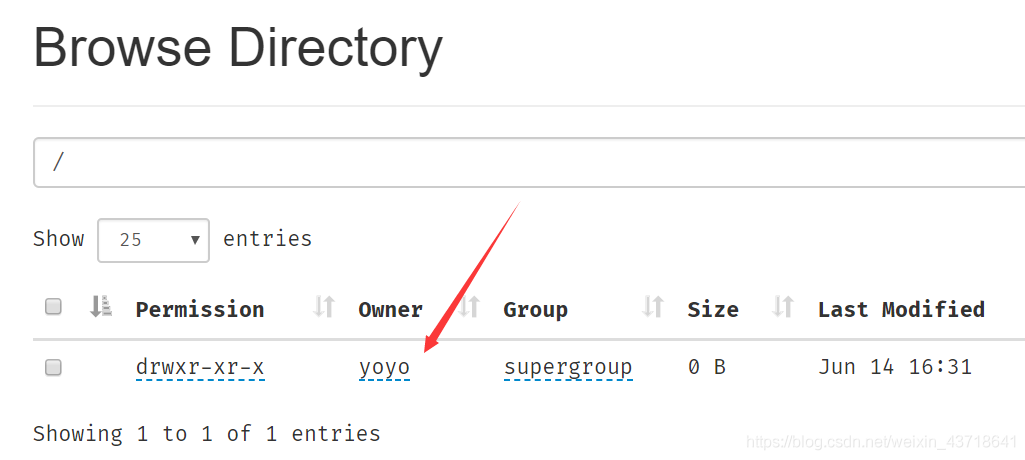
到此這篇關於Hadoop運行時遇到java.io.FileNotFoundException錯誤的解決方法的文章就介紹到這瞭,更多相關Hadoop運行錯誤內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Linux下安裝Hadoop集群詳細步驟
- Hadoop中的壓縮與解壓縮案例詳解
- sqoop export導出 map100% reduce0% 卡住的多種原因及解決
- Java基礎之MapReduce框架總結與擴展知識點
- Windows下使用IDEA搭建Hadoop開發環境的詳細方法