淺談分詞器Tokenizer
一、概述
分詞器的作用是將一串字符串改為“詞”的列表,下面以“大學生活”這個輸入為例進行講解:
對“大學生活”這句話做分詞,通常來說,一個分詞器會分三步來實現:
(1)找到“大學生活”這句話中的全部詞做為一個集合,即:[大、大學、大學生、學、學生、生、生活、活]
(2)在第一步中得到的集合中找到所有能組合成“大學生活”這句話的子集,即:
[大、學、生、活]
[大、學、生活]
[大、學生、活]
[大學、生、活]
[大學、生活]
[大學生、活]
(3)在第二步中產生的所有子集中挑選一個最有可能的作為最終的分詞結果。
為瞭得到第1步需要的集合,通常我們需要一個詞典。大部分的分詞器都是基於詞典去做分詞的(也就是說也可以不基於詞典來做分詞,在此暫時不做討論)。那麼現在假設我們有一個小詞典:[大學、大學生、學習、學習機、學生、生氣、生活、活著]。首先要在“大學生活”這句話裡面匹配到這個詞典裡面的全部詞,有些同學腦中可能會出現這種過程:
public class Demo1{
//加載詞典中的所有詞匯
static Set<String> dic = new HashSet(){{
add("大學");
add("大學生");
add("學習");
add("學習機");
add("學生");
add("生氣");
add("生活");
add("活著");
}};
//匹配句子中詞典中存在的所有詞匯
static List<String> getAllWordsMatched(String sentence){
List<String> wordList = new ArrayList<>();
for(int index = 0;index < sentence.length();index++){
for(int offset = index+1; offset <= sentence.length();offset++){
String sub = sentence.substring(index,offset);
if(dic.contains(sub)){
wordList.add(sub);
}
}
}
return wordList;
}
public static void main(String[] args){
String sentence = "大學生活";
getAllWordsMatched(sentence).forEach(System.out::println);
}
}
執行這段代碼會輸出:
大學
大學生
學生
生活
似乎到這裡,我們已經完美地完成瞭在詞典中找到詞的任務。然而真實的分詞器的詞典往往有幾十萬甚至幾百萬的詞匯量,使用上面這種算法性能太低瞭。高效地實現這種匹配的算法有很多,下面簡單介紹一種:
二、AC自動機(Aho-Corasick automaton)
AC自動機是一種常用的多模式匹配算法,基於字典樹(trie樹)的數據結構和KMP算法的失敗指針的思想來實現,有不錯的性能並且實現起來非常簡單。
2.1、字典樹(trie樹)
引用一下百度百科對於trie樹的描述:Trie樹,是一種樹形結構,是一種哈希樹的變種。典型應用是用於統計,排序和保存大量的字符串(但不僅限於字符串),所以經常被搜索引擎系統用於文本詞頻統計。它的優點是:利用字符串的公共前綴來減少查詢時間,最大限度地減少無謂的字符串比較,查詢效率比哈希樹高。
下面一個存放瞭[大學、大學生、學習、學習機、學生、生氣、生活、活著]這個詞典的trie樹:
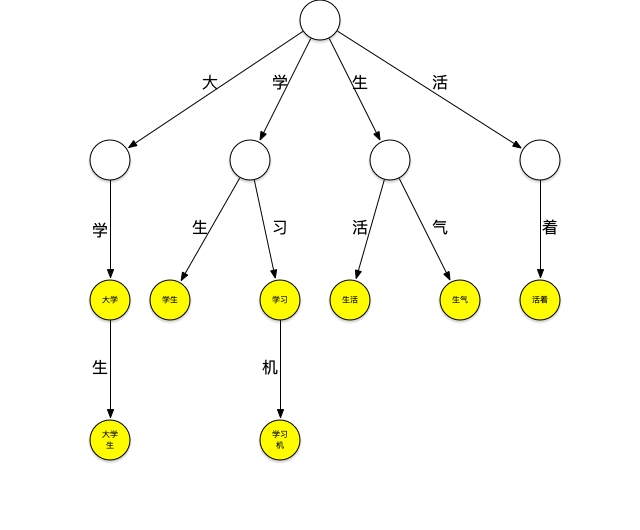
它可以看作是用每個詞第n個字做第n到第n+1層節點間路徑哈希值的哈希樹,每個節點是實際要存放的詞。
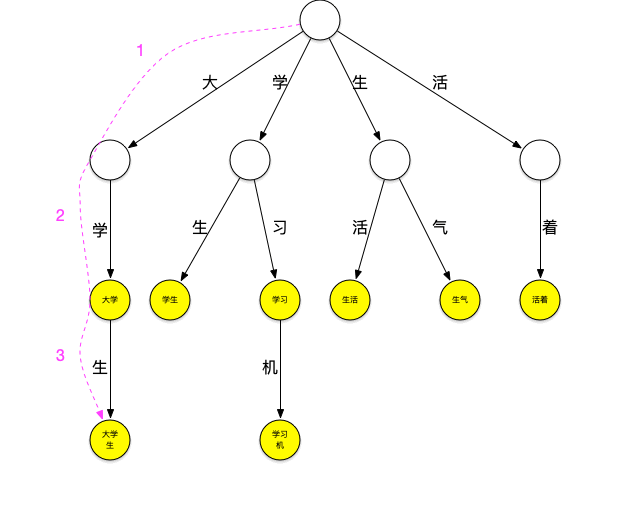
現在用這個樹來進行“大學生活”的匹配。依然從“大”字開始匹配,如下圖所示:從根節點開始,沿最左邊的路徑匹配到瞭大字,沿著“大”節點可以匹配到“大學”,繼續匹配則可以匹配到“大學生”,之後字典中再沒有以“大”字開頭的詞,至此已經匹配到瞭[大學、大學生]第一輪匹配結束。
繼續匹配“學”字開頭的詞,方法同上步,可匹配出[學生]

繼續匹配“生”和“活”字開頭的詞,這樣“大學生活”在詞典中的詞全部被查出來。
可以看到,以匹配“大”字開頭的詞為例,第一種匹配方式需要在詞典中查詢是否包含“大”、“大學”、“大學”、“大學生活”,共4次查詢,而使用trie樹查詢時當找到“大學生”這個詞之後就停止瞭該輪匹配,減少瞭匹配的次數,當要匹配的句子越長,這種性能優勢就越明顯。
2.2、失敗指針
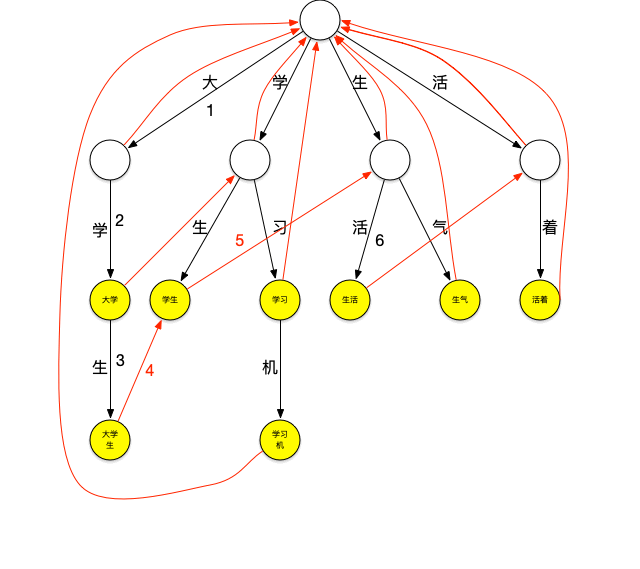
再來看一下上面的匹配過程,在匹配“大學生”這個詞之後,由於詞典中不存在其它以“大”字開頭的詞,本輪結束,將繼續匹配以“學”字開頭的詞,這時,需要再回到根節點繼續匹配,如果這個時候“大學生”節點有個指針可以直指向“學生”節點,就可以減少一次查詢,類似地,當匹配完“學生”之後如果“學生”節點有個指針可以指向“生活”節點,就又可以減少一次查詢。這種當下一層節點無法匹配需要進行跳轉的指針就是失敗指針,創建好失敗指針的樹看起來如下圖:

圖上紅色的線就是失敗指針,指向的是當下層節點無法匹配時應該跳轉到哪個節點繼續進行匹配。
失敗指針的創建過程通常為:
1.創建好trie樹。
2.BFS每一個節點(不能使用DFS,因為每一層節點的失敗指針在創建時要確保上一層節點的失敗指針全部創建完成)。
3.根節點的子節點的失敗指針指向根節點。
4.其它節點查找其父節點的失敗指針指向的節點的子節點是否有和該節點字相同的節點,如果有則失敗指針指向該節點,如果沒有則重復剛才的過程直至找到字相同的節點或根節點。
查詢過程如下:
執行這段代碼會輸出:
大學
大學生
學生
生活
在匹配到瞭詞典中所有出現在句子中的詞之後,繼續第二步:在得到的集合中找到所有能組合成“大學生活”這個句子的子集。但是在這個地方遇到瞭一個小問題,上面查到的4個詞中僅有“大學”和“生活”這兩個詞可以組成“大學生活”這個句子,而“大學生”和“生活”則無法在匹配到的詞中找到能夠與其連接的詞匯。現實情況中,詞典很難囊括所有詞匯,所以這種情況時有發生。在這裡,可以額外將單個字放到匹配到的詞的集合中,這得到瞭一個新集合:
[大學、大學生、學生、生活]U[大、學、生、活] = [大學、大學生、學生、生活、大、學、生、活]
可以用一個有向圖來表示這個集合的分詞組合,從開始節點到結束節點的全部路徑就是所有分詞方式。

三、最終的分詞結果
那麼在這些可能的分詞組合中,應該選取哪一種作為最終的分詞結果呢?大部分分詞器的主要差異也體現在這裡,有些分詞器可能有很多不同的分詞策略供使用者選擇。例如最少詞策略,就是在有向圖中選擇能夠達到結束節點的全部路徑中最短(經過最少節點)的一條。對於上面這張有向圖,最短路徑有兩條,分別是“大學,生活”與“大學生,活”最終的分詞結束就在這兩條路徑中選擇一條。這種選擇方法最為簡單,性能也很高,但是準確性較差。其實仔細考慮一下不難發現,無論使用哪種分詞策略,其目的都是想要挑選出一條最可能正確的,也就是概率最大的一種。“大學生活”分詞為[大、學、活]的概率為P(大)P(學|大)P(生|大,學)P(活|大,學,生),這就是說,想要計算其的概率,需要知道“大”的出現概率,“大”出現時“學”出現的概率,“大”、“學”同時出現時“生”的概率,“大”,“學”,“生”同時出現時出現“活”的概率。這些出現概率可以在一份由大量文章組成的文本庫中統計得出,但是問題是,如果詞典要記錄任意N個詞出現時出現詞W的概率,一個存放M個詞匯的詞典需要存放M^N量級的關系數據,這個詞典會太大,所以通常會限制N的大小,一般來說,N為2或者為3,計算條件概率時隻考慮到它前面2到3個詞,這是基於馬爾可夫鏈做的簡化。當N為2時稱為二元模型,N為3時稱為三元模型。一個有50萬詞的詞典的二元模型需要50萬*50萬條關系,這也是相當大的一個量級,可以對其進行壓縮或轉化為其它近似形式,這部分相對比較復雜,在此不作講解,這裡使用更簡單一些的形式,假設每個詞的出現都是獨立事件,令P(大,學,生,活)=P(大)P(學)P(生)P(活)。要計算這個概率,隻需要知道每個詞的出現概率,一個詞的出現概率=詞出現的次數/文本庫中詞總量。那麼將之前使用的詞典更新為[大學5、大學生4、學習6、學習機3、學生5、生氣8、生活7、活著2] 後面的數字是這些詞在文本庫中出現的次數,文本庫中詞的問題就是這些詞出現次數之和=5+4+6+3+5+8+7+2=40
那麼P(大學,生活)=P(大學)P(生活)=5/40*7/40
P(大學生、活)=P(大學生)P(活)=4/40*0/40 在這個地方出現瞭問題,對於詞典裡不存在的詞,它的概率是0,這將會導致整個乘積是0,這是不合理的,對於這種情況可以做平滑處理,簡單地來說,可以設詞典中不存在的詞的出現次數為1,於是P(大學生、活)=P(大學生)P(活)=4/40*1/40
最終可以挑選出一條最有可能的分詞組合。至此第三步結束。
以上就是淺談分詞器Tokenizer的詳細內容,更多關於分詞器Tokenizer的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- java與scala數組及集合的基本操作對比
- java中List去除重復數據的5種方式總結
- Java中關於泛型、包裝類及ArrayList的詳細教程
- Java關於List集合去重方案詳細介紹
- 一篇文章帶你入門java集合