配置python連接oracle讀取excel數據寫入數據庫的操作流程
前提條件:本地已經安裝好oracle單實例,能使用plsql developer連接,或者能使用TNS連接串遠程連接到oracle集群
讀取excel寫入數據庫的方式有多種,這裡介紹的是使用pandas寫入,相對來說比較簡便,不需要在讀取excel後再去整理數據
整個過程需要分兩步進行:
一、配置python連接oracle並測試成功
網上有不少教程,但大部分都沒那麼詳細,並且也沒有說明連接單實例和連接集群的區別,這裡先介紹連接oracle單實例的方式,後續再補充連接oracle集群方式。
版本:
window 10 64位
python 3.6.8
cx-Oracle 7.3.0
安裝流程:
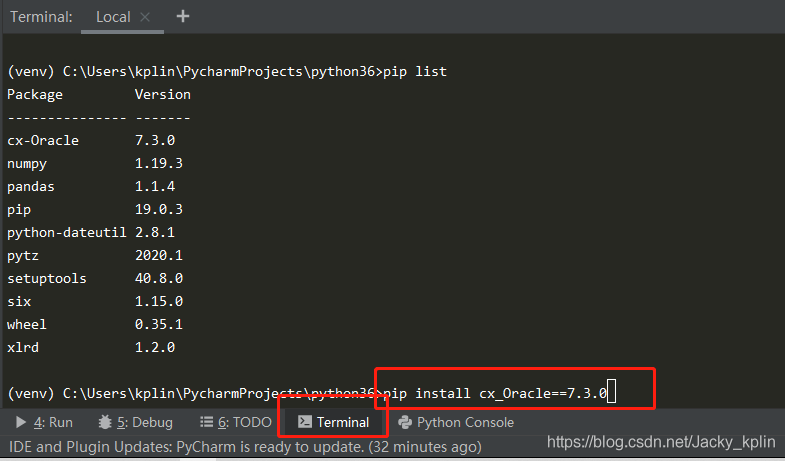
1、使用pip安裝操作oracle的包:
pip install cx_Oracle==7.3.0
2、手動配置cx_Oracle臨時客戶端:
註意這裡電腦是64位的,使用的即時客戶端也是64位的,32位的需要另外到下面的下載地址找一下
2.1、解壓下面的文件
鏈接: https://pan.baidu.com/s/12iMCBjKvl-Lao9iOHMT-yw
提取碼: pxmq
oracle即時客戶端使用說明:
https://docs.oracle.com/en/database/oracle/oracle-database/19/lnoci/instant-client.html#GUID-6895DB45-97AA-4738-9959-BD677D610186
oracle即時客戶端下載地址:
https://www.oracle.com/database/technologies/instant-client/downloads.html
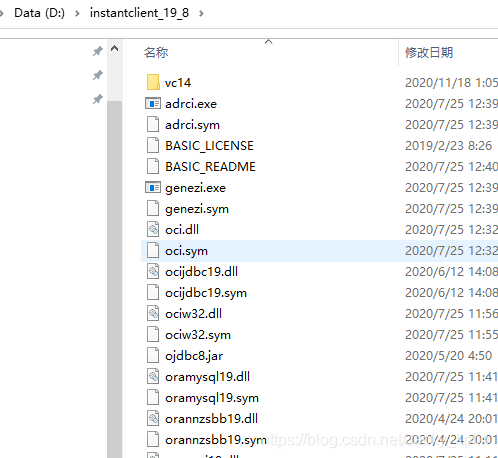
2.2、放置到D盤某個位置,例如:
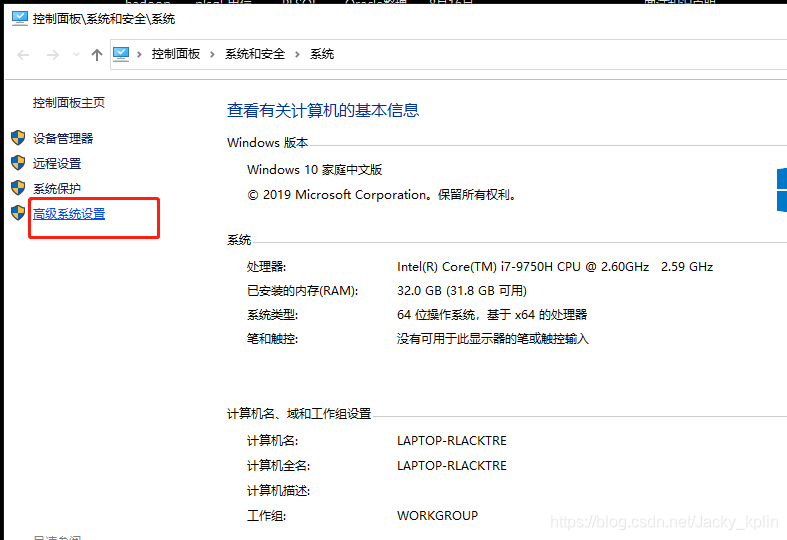
2.3、配置環境變量
控制面板——系統和安全——系統
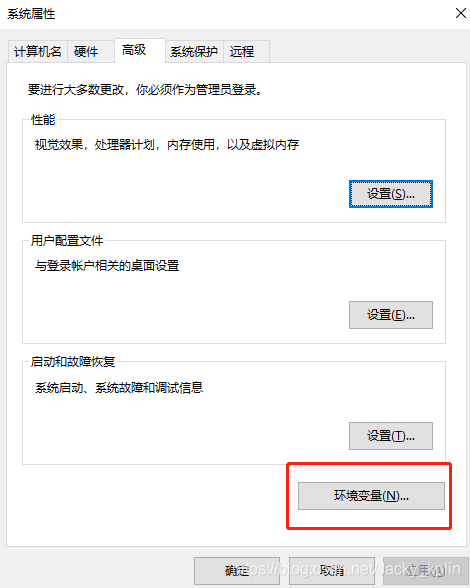
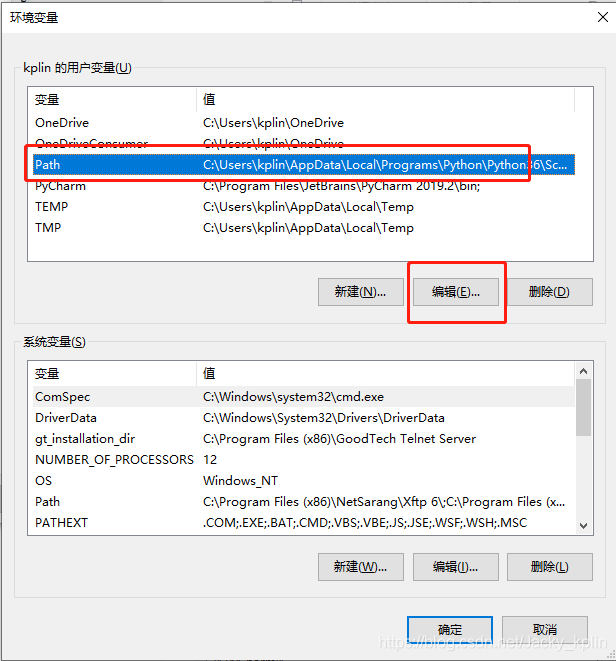
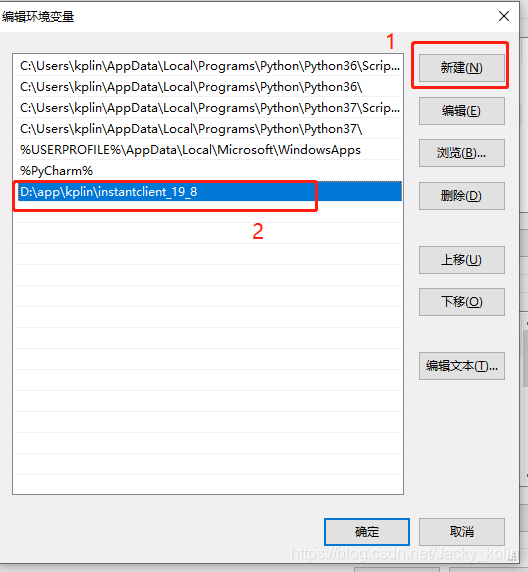
2.4、重啟電腦,讓新配置的環境變量生效
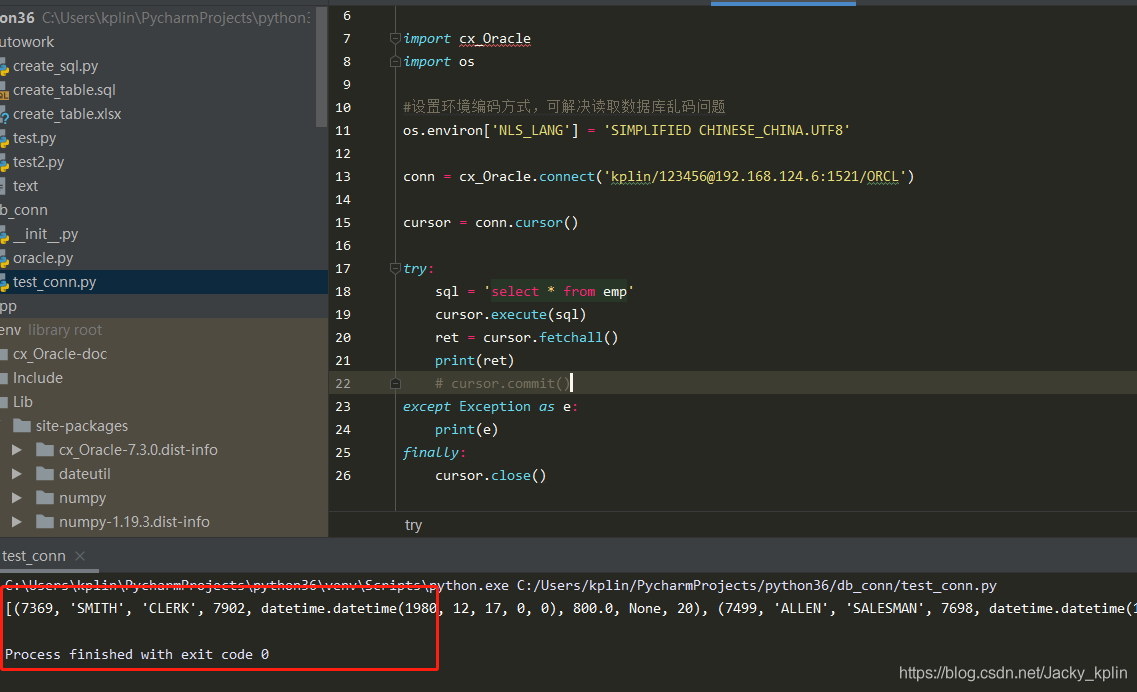
2.5、測試配置是否成功
雖然導入cx_Oracle有紅色波浪線,一般認為導入不成功,但這裡可以先不管它,直接運行測試代碼,沒有報錯說明沒問題。
如果沒有查到數據,也可能是該用戶下沒有emp表。
import cx_Oracle
import os
# 設置環境編碼方式,可解決讀取數據庫中文亂碼問題
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
# 用戶名/密碼@IP:端口/實例名
conn = cx_Oracle.connect('kplin/12sss3456@192.168.124.102:1521/ORCL')
cursor = conn.cursor()
try:
sql = 'select * from emp'
cursor.execute(sql)
ret = cursor.fetchall()
print(ret)
# cursor.commit()
except Exception as e:
print(e)
finally:
cursor.close()
二、使用pandas讀取excel數據,使用sqlalchemy協助寫入數據庫
1、安裝sqlalchemy,pandas
這裡指定pandas版本是因為最新版的pandas在讀寫excel的時候會有些奇怪的報錯,換成1.1.4版本即可。
pip install pandas==1.1.4 pip install sqlalchemy
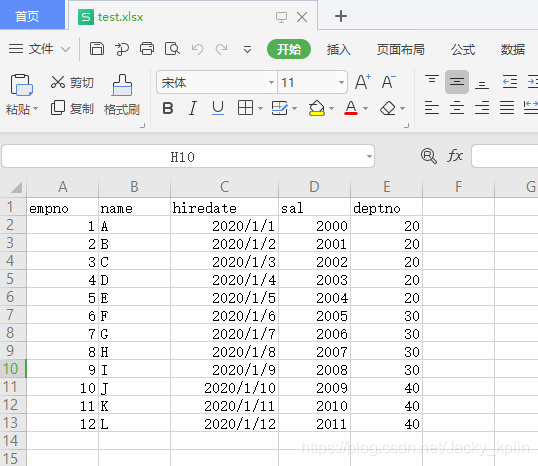
2、準備一個excel表,命名為test.xlsx,寫入以下測試數據
3、測試讀取並寫入數據庫
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# date: 2021/3/14
# filename: excel_to_db
# author: kplin
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy import types
# conn_string='oracle+cx_oracle://user:pass@host:port/dbname'
conn_string='oracle+cx_oracle://KPLIN:654321@192.168.124.6:1521/ORCL'
engine = create_engine(conn_string, echo=False)
df = pd.read_excel('test.xlsx')
# if_exists有三個可選值,'fail':如果存在該表則報錯,'append':如果存在該表則將數據追加到列尾,'replace':如果存在該表則替換
# df.to_sql('test', con=engine, if_exists='replace')
# 按上面這種寫入方式name字段將被寫成clob字段類型,
# 如果我們希望把name改為varchar2類型,怎麼做?
# 我們可以利用sqlalchemy的types把name指定為varchar2()類型
len = df.name.str.len().max()
df.to_sql('test', engine, if_exists='replace', dtype={'name': types.VARCHAR(len)})
rows = engine.execute("SELECT * FROM TEST").fetchall()
print(rows)
到此這篇關於配置python連接oracle讀取excel數據寫入數據庫的操作流程的文章就介紹到這瞭,更多相關python讀取excel數據寫入oracle數據庫內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python 讀取千萬級數據自動寫入 MySQL 數據庫
- Python寫入MySQL數據庫的三種方式詳解
- Python模擬簡易版淘寶客服機器人的示例代碼
- Python ORM框架之SQLAlchemy 的基礎用法
- 利用Python連接Oracle數據庫的基本操作指南