Linux安裝Pytorch1.8GPU(CUDA11.1)的實現
先說下自己之前的環境(都是Linux系統,差別不大):
- Centos7.6
- NVIDIA Driver Version 440.33.01(等會需要更新驅動)
- CUDA10.1
- Pytorch1.6/1.7
提示,如果想要保留之前的PyTorch1.6或1.7的環境,請不要卸載CUDA環境,可以通過Anaconda管理不同的環境,互不影響。但是需要註意你的NVIDIA驅動版本是否匹配。
在這裡能夠看到官方給的對應CUDA版本所需使用驅動版本。
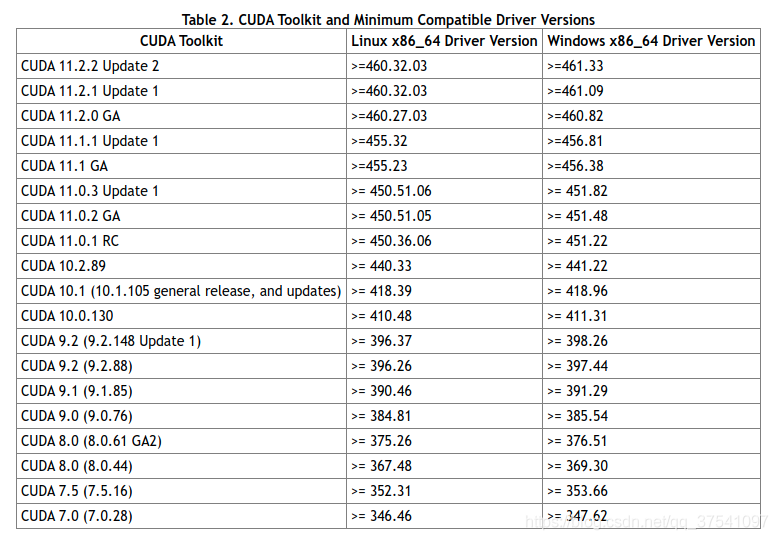
通過上表可以發現,如果要使用CUDA11.1,那麼需要將顯卡的驅動更新至455.23或以上(Linux x86_64環境)。由於我之前的驅動版本是440.33.01,那麼肯定不滿足,所以需要更新下顯卡的驅動。通過以下指令可以查看你電腦上的驅動版本:
nvidia-smi
如果你的驅動版本是滿足的,那麼可以直接跳到創建Pytorch1.8虛擬環境章節。
更新驅動
卸載舊驅動
我之前安裝的是NVIDIA-440的版本,找到之前下載的安裝程序,然後打開終端通過以下指令進行卸載:
sh ./NVIDIA-Linux-x86_64-440.33.01.run --uninstall
安裝新驅動
1)下載驅動,直接去NVIDIA官網下載:https://www.nvidia.cn/Download/index.aspx?lang=cn
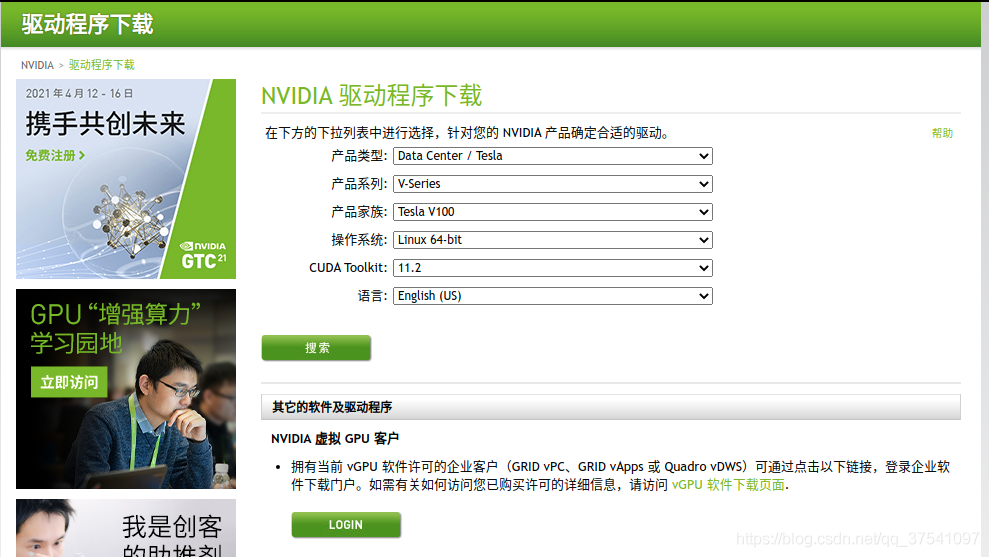
根據你的GPU型號以及操作信息選擇對應的驅動,註意CUDA Toolkit11版的當前可選的隻有11.0和11.2,而我們要裝的是11.1所以選擇11.2即可。
2)關閉Xserver服務 (如果沒有安裝桌面系統可以跳過)
我的桌面系統是gdm(GNOME Display Manager)類型的,通過systemctl可以看到:
systemctl status gdm.service
顯示結果:
● gdm.service – GNOME Display Manager
Loaded: loaded (/usr/lib/systemd/system/gdm.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2021-01-22 09:27:06 CST; 1 months 22 days ago
Process: 32347 ExecStartPost=/bin/bash -c TERM=linux /usr/bin/clear > /dev/tty1 (code=exited, status=0/SUCCESS)
Main PID: 32344 (gdm)
Tasks: 22
CGroup: /system.slice/gdm.service
├─32344 /usr/sbin/gdm
└─32357 /usr/bin/X :0 -background none -noreset -audit 4 -verbose -auth /run/gdm/auth-for-gdm-mBzawN/databa…Jan 22 09:27:06 localhost.localdomain systemd[1]: Starting GNOME Display Manager…
Jan 22 09:27:06 localhost.localdomain systemd[1]: Started GNOME Display Manager.
關閉gdm服務:
systemctl stop gdm.service
註意,如果還開啟瞭類似VNC遠程桌面的服務也要記得關閉。
3)安裝新版本驅動
sh ./NVIDIA-Linux-x86_64-460.32.03.run
4)檢查nvidia服務
通過以下指令能夠看到當前主機上的nvidia驅動版本以及所有可用GPU設備信息。
nvidia-smi
5)再次開啟桌面服務、VNC等
如果不是gdm或者不使用桌面環境可以跳過此步驟
systemctl start gdm.service
創建PyTorch1.8虛擬環境
為瞭不同版本之間的環境互相隔離,強烈建議使用Anaconda的虛擬環境。其實使用起來也非常簡單:
創建虛擬環境,這裡我創建瞭一個名為torch18的虛擬環境,並且創建python3.8的編譯環境。
conda create -n torch18 python=3.8
安裝完成後,激活虛擬環境
conda activate torch18
接著安裝點常用的包,這裡直接通過requirements.txt批量安裝(不需要可以跳過)
pip install -r requirements.txt
requirements.txt文件裡可以是你常用的一些包,例如:
numpy==1.17.0 matplotlib==3.2.1 lxml==4.6.2 tqdm==4.42.1
如果需要退出虛擬環境,執行以下指令即可:
conda deactivate
安裝PyTorch1.8
在線安裝
進入PyTorch官網:https://pytorch.org/
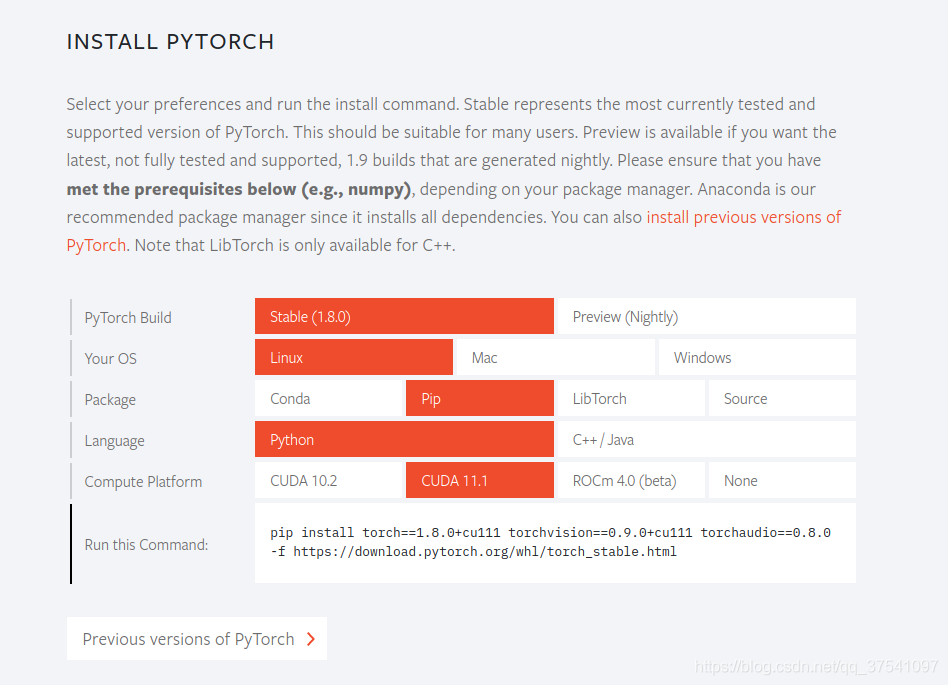
我們通過選擇自己的系統類型、安裝方式以及CUDA的版本可以得到對應的安裝指令。官方默認會順帶安裝torchvision和torchaudio但我隻需要torchvision所以通過以下指令安裝 (註意,要進入對應的虛擬環境安裝,例如上面的torch18環境):
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
安裝完成後就可以使用瞭,不需要在單獨安裝CUDA,並且不會影響之前安裝的CUDA版本。
下面進行簡單的測試:
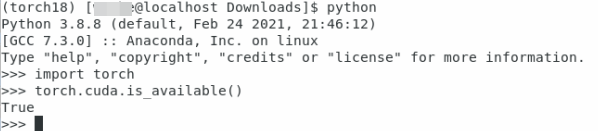
首先在終端輸入python進入python環境:
pyhton
然後導入torch包,查看cuda是否可用:
import torch torch.cuda.is_available()
如果打印的是True表示成功
離線安裝
有些時候,可能你的設備無法連接外網,此時需要提前準備好需要安裝的whl文件,那麼我們這裡就以torch和torchvision為例(註意安裝torch前需要提前安裝好numpy包)。剛剛我們在線安裝時發現安裝指令最後有個網址,https://download.pytorch.org/whl/torch_stable.html,沒錯就是官方存放所有的安裝包,所以我們可以直接去那裡下載。

我們在這裡可以找到我們需要的torch-1.8.0+cu111-cp38-cp38-linux_x86_64.whl以及torchvision-0.9.0+cu111-cp38-cp38-linux_x86_64.whl兩個文件即可。註意,cu111代表CUDA11.1,cp38表示python3.8的編譯環境,linux_x86_64表示x86的平臺64位操作系統。下載完成後,我們將這兩個文件傳入你的離線主機(服務器)中。接著在保存這兩個文件夾的目錄下打開終端:
進入對應虛擬環境
conda activate torch18
安裝torch
pip install torch-1.8.0+cu111-cp38-cp38-linux_x86_64.whl
安裝torchvison
pip install torchvision-0.9.0+cu111-cp38-cp38-linux_x86_64.whl
安裝完成後進行簡單的測試:
首先在終端輸入python進入python環境:
pyhton
然後導入torch包,查看cuda是否可用:
import torch torch.cuda.is_available()
如果打印的是True表示成功
通過docker安裝
在有些情況下是需要使用docker來跑深度學習環境的(現在很多大公司都是使用paas平臺來部署的)。那麼我們就需要使用pytorch官方的docker鏡像瞭。我們可以在docker hub上去搜索相關鏡像,https://registry.hub.docker.com/。下圖是我搜索的pytorch字段的結果(點擊Tags後)。
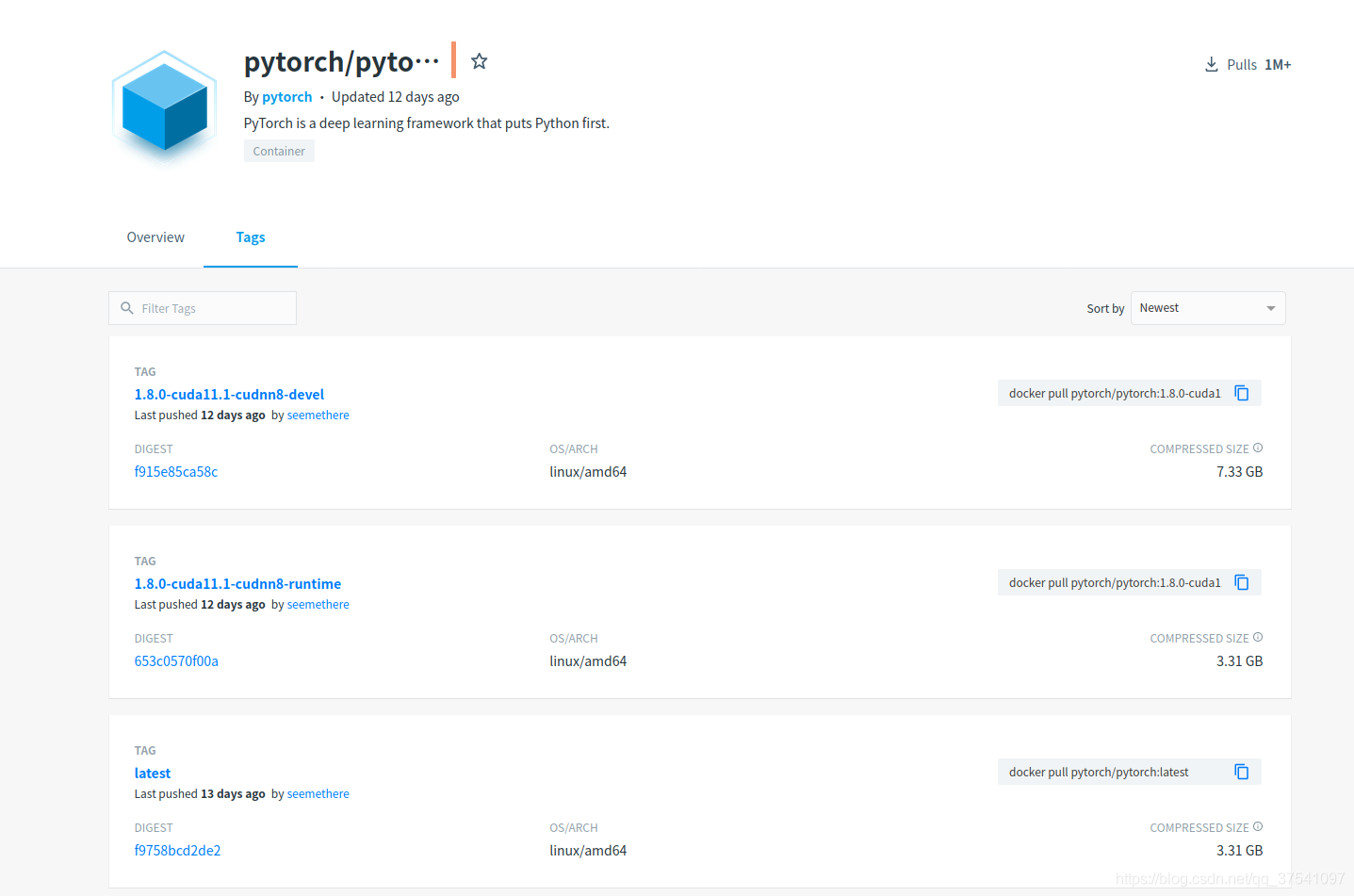
我們可以看到當前最新的docker 鏡像有pytorch/pytorch:1.8.0-cuda11.1-cudnn8-devel和pytorch/pytorch:1.8.0-cuda11.1-cudnn8-runtime,對於普通開發者下載pytorch/pytorch:1.8.0-cuda11.1-cudnn8-runtime就行瞭。關於安裝docker的過程這裡不贅述。
1)我們直接通過以下指令就能pull這個鏡像瞭
docker pull pytorch/pytorch:1.8.0-cuda11.1-cudnn8-runtime
2)註意,在啟動鏡像前需要確保已安裝NVIDIA Container Toolkit,否則會報錯(若已安裝可直接跳過此步驟):
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
安裝NVIDIA Container Toolkit,參考官方文檔:https://github.com/NVIDIA/nvidia-docker
這裡以Centos7為例:
首先根據你的系統類型以及版本下載對應.repo文件到/etc/yum.repos.d
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
清空yum的過期緩存數據(如果不是root用戶需要加sudo)
yum clean expire-cache
安裝NVIDIA Container Toolkit(如果不是root用戶需要加sudo)
yum install -y nvidia-docker2
重啟docker服務(如果不是root用戶需要加sudo)
systemctl restart docker
3)通過docker啟動pytorch1.8.0容器
docker run --gpus all --rm -it --ipc=host pytorch/pytorch:1.8.0-cuda11.1-cudnn8-runtime
4)進入容器後可以通過nvidia-smi看到所有的GPU設備信息
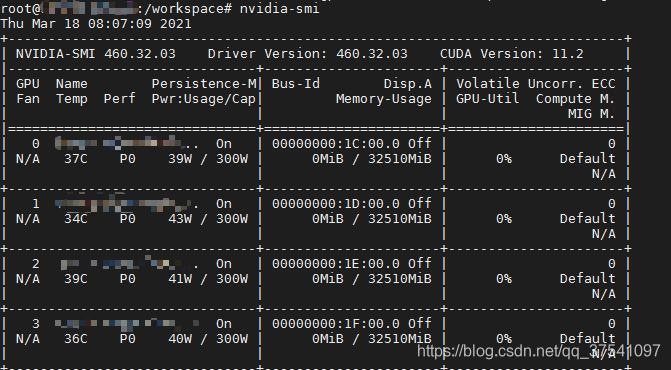
5)接著進入python環境簡單測試下pytorch能否正常調用GPU(打印True為成功)
import torch torch.cuda.is_available()

到此這篇關於Linux安裝Pytorch1.8GPU(CUDA11.1)的實現的文章就介紹到這瞭,更多相關Linux安裝Pytorch GPU 內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- docker容器使用GPU方法實現
- 詳解win10下pytorch-gpu安裝以及CUDA詳細安裝過程
- docker容器內安裝TensorRT的問題
- Win10下安裝CUDA11.0+CUDNN8.0+tensorflow-gpu2.4.1+pytorch1.7.0+paddlepaddle-gpu2.0.0
- Linux安裝Docker詳細教程