redis keys與scan命令的區別說明
redis keys和scan的區別
redis的keys命令,通常在用來刪除相關key時使用,但這個命令有一個弊端,在redis擁有數百萬及以上的keys時,執行速度會比較慢,更致命的是,這個命令會阻塞redis多路復用的io主線程,如果這個線程阻塞,在此期間,其他發向redis服務端的命令,都會被阻塞,從而引發一系列級聯反應,導致瞬間相應卡頓,從而引發超時等問題,所以應該在生產環境禁止用使用keys和類似的命令smembers,這種時間復雜度為O(N),且會阻塞主線程的命令,是非常危險的。
如果在生產環境上,我們有需要查找然後刪除key的需求,我們應該使用scan命令,來替代key。scan也是O(N)復雜度,支持通配查找key的命令,不同keys的是它采用的是遊標按批次迭代返回數據,可以不用阻塞主線程。
scan:漸進式遍歷鍵
SCAN cursor [MATCH pattern] [COUNT count]
scan 參數提供瞭三個參數(6.0後增加瞭一個type參數,具體看官方文檔),第一個是 cursor 整數值(hash桶的索引值),第二個是 key 的正則模式,第三個是一次遍歷的key的數量(參考值,底層遍歷的數量不一定),並不是符合條件的結果數量。
第一次遍歷時,cursor 值為 0,然後將返回結果中第一個整數值作為下一次遍歷的 cursor。
一直遍歷到返回的 cursor 值為 0 時結束。
使用案例如下:
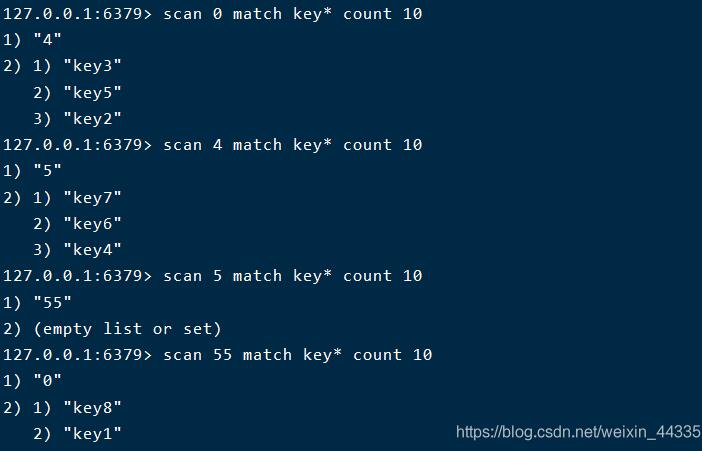
從運行結果,我們可以看出幾個問題:
雖然我們指定瞭掃描的count是10,但它實際掃描出來的數量不一定是10
scan他可能遍歷出重復的key
這邊解釋一下,為什麼掃描出來得數量不一定是10。這是因為match實際上相當於過濾器的作用,所以scan其實是先掃描10個元素出來,然後再根據pattern一過濾,那麼剩下來的滿足條件元素就可能沒有10個瞭,甚至可能一個都沒有。
此外呢,如果在scan的過程中有鍵的變化(增加、刪除、修改),那麼新增的鍵可能不會被遍歷出來,即scan不能保證完整的遍歷出所有的鍵,這是我們開發的時候需要考慮的。
關於更多的細節,比如為什麼新增的鍵可能不能被遍歷出來,等我後面更深入的學習瞭redis底層的數據結構在回來補充。
總之,對於redis的大數量操作,很難做到很精確。

補充:redis模糊查詢keys和scan的比較和用法
一、keys
1、語法
keys pattern
2、說明
redis中允許模糊查詢的有3個通配符,分別是:*,?,[]
*:通配任意多個字符
?:通配單個字符
[]:通配括號內的某一個字符
3、操作
192.168.230.21:6379[2]> set hello 1 OK 192.168.230.21:6379[2]> set word 1 OK 192.168.230.21:6379[2]> set hellp 1 OK 192.168.230.21:6379[2]> set ahellog 1 OK 192.168.230.21:6379[2]> set hellog 1 OK 192.168.230.21:6379[2]> keys * 1) "hello" 2) "hellog" 3) "hellp" 4) "word" 5) "ahellog" 192.168.230.21:6379[2]> keys *hell* 1) "hello" 2) "hellog" 3) "hellp" 4) "ahellog" 192.168.230.21:6379[2]> keys hell* 1) "hello" 2) "hellog" 3) "hellp" //知道前面的一些字母,忘記瞭最後一個字母 192.168.230.21:6379[2]> keys hell? 1) "hello" 2) "hellp" //知道前面的一些字母,忘記瞭最後兩個個字母 192.168.230.21:6379[2]> keys hell?? 1) "hellog" //知道前面四個字母,最後一個字母有可能是p t y 其中的一個 192.168.230.21:6379[2]> keys hell[pty] 1) "hellp" 192.168.230.21:6379[2]>
二、scan
1、語法
SCAN cursor [MATCH pattern] [COUNT count]
2、說明
scan 遊標 MATCH <給定模式相匹配的元素> count 每次迭代所返回的元素數量 ,SCAN 命令是增量的循環,每次調用隻會返回一小部分的元素。scan會返回兩個結果,一個是用於下次遍歷的遊標,一個是結果集;
SCAN 命令是一個基於遊標的迭代器(cursor based iterator): SCAN 命令每次被調用之後, 都會向用戶返回一個新的遊標, 用戶在下次迭代時需要使用這個新遊標作為 SCAN 命令的遊標參數, 以此來延續之前的迭代過程。
當 SCAN 命令的遊標參數被設置為 0 時, 服務器將開始一次新的迭代, 而當服務器向用戶返回值為 0 的遊標時, 表示迭代已結束
3、操作
192.168.230.21:6379[2]> keys * 1) "hello" 2) "hellog" 3) "hellp" 4) "word" 5) "ahellog" 192.168.230.21:6379[2]> scan 0 match *ll* count 2 1) "5" 2) 1) "hellp" 2) "hello" 192.168.230.21:6379[2]> scan 5 match *ll* count 2 1) "0" 2) 1) "hellog" 2) "ahellog" 192.168.230.21:6379[2]>
三、性能對比
1、我們在獲取redis裡面的某個db裡面的所有數據可以用 `keys `這樣的指令來實現。但是存在一個問題就是這樣做的話,在數據量很大的情況下效率是很不理想的;
2、Keys模糊匹配,請大傢在實際運用的時候忽略掉。因為Keys會引發Redis鎖,並且增加Redis的CPU占用,情況是很惡劣的;如果數據龐大的話可能需要幾秒或更長,對於生產服務器上鎖定幾秒這絕對是災難瞭;
3、新的命令SCAN出現,它可以幫助我們解決因為用keys遍歷大數據量的數據庫而導致服務器阻塞的情況,因為它每次都隻便利一小部分數據,每次操作對應的時間復雜度是O(1);
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。如有錯誤或未考慮完全的地方,望不吝賜教。
推薦閱讀:
- php redis的scan用法實例分析
- Redis SCAN命令詳解
- spring redis 如何實現模糊查找key
- Redis Cluster 字段模糊匹配及刪除
- 淺談Redis的keys命令到底有多慢