pandas組內排序,並在每個分組內按序打上序號的操作
問題:
pandas組內排序,並在每個分組內按序打上序號
描述:
pandas dataframe 對dep_id組內的salary排序。希望給下面原本隻有前三列的dataframe,添加上第四列。
等價於sql裡的排序函數 row_number() over() 功能
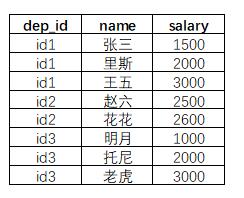
假設我已經建好瞭僅有前三列的dataframe,數據集命名為 MyData,
解決方案如下:
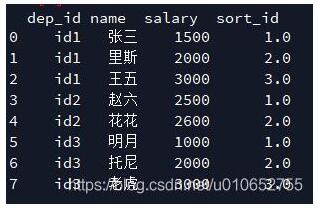
MyData['sort_id'] = MyData['salary'].groupby(MyData['dep_id']).rank()
結果如下:
補充:Pandas.DataFrame實現分組、排序並且為分組插入排名
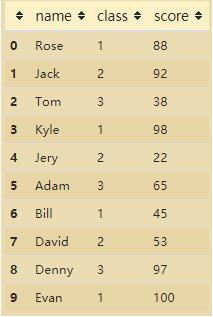
1. 示例數據(各班級學生得分)
import pandas as pd
data_dict = {"name":
["Rose", "Jack", "Tom", "Kyle", "Jery", "Adam", "Bill", "David", "Denny", "Evan"],
"class": [1, 2, 3, 1, 2, 3, 1, 2, 3, 1],
"score": [88, 92, 38, 98, 22, 65, 45, 53, 97, 100]}
df = pd.DataFrame(data=data_dict)
df
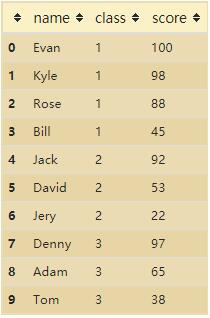
2. 按班級分組
df = df.groupby('class', sort=False)\
.apply(lambda x:x.sort_values("score", ascending=False))\
.reset_index(drop=True)
df
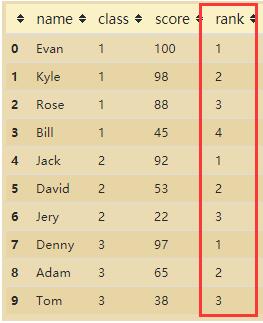
3. 給各分組班級增加排名列
df["rank"] = None
# 標識班級
flag = df.loc[0].values[1]
rank = 0
for i in range(len(df)):
temp = df.loc[i].values[1]
if (temp == flag).all():
# 同一班級
rank += 1
else:
# 不同班級,重新計算排名
flag = temp
rank = 1
df.loc[i, "rank"] = rank
df
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。如有錯誤或未考慮完全的地方,望不吝賜教。
推薦閱讀:
- pandas的排序、分組groupby及cumsum累計求和方式
- pandas groupby分組對象的組內排序解決方案
- pandas刪除部分數據後重新生成索引的實現
- Python機器學習三大件之二pandas
- Python 更快進行探索性數據分析的四個方法