超詳細PyTorch實現手寫數字識別器的示例代碼
前言
深度學習中有很多玩具數據,mnist就是其中一個,一個人能否入門深度學習往往就是以能否玩轉mnist數據來判斷的,在前面很多基礎介紹後我們就可以來實現一個簡單的手寫數字識別的網絡瞭
數據的處理
我們使用pytorch自帶的包進行數據的預處理
import torch import torchvision import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5), (0.5)) ]) trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True,num_workers=2)
註釋:transforms.Normalize用於數據的標準化,具體實現
mean:均值 總和後除個數
std:方差 每個元素減去均值再平方再除個數
norm_data = (tensor - mean) / std
這裡就直接將圖片標準化到瞭-1到1的范圍,標準化的原因就是因為如果某個數在數據中很大很大,就導致其權重較大,從而影響到其他數據,而本身我們的數據都是平等的,所以標準化後將數據分佈到-1到1的范圍,使得所有數據都不會有太大的權重導致網絡出現巨大的波動
trainloader現在是一個可迭代的對象,那麼我們可以使用for循環進行遍歷瞭,由於是使用yield返回的數據,為瞭節約內存
觀察一下數據
def imshow(img): img = img / 2 + 0.5 # unnormalize npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # torchvision.utils.make_grid 將圖片進行拼接 imshow(torchvision.utils.make_grid(iter(trainloader).next()[0]))

構建網絡
from torch import nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=28, kernel_size=5) # 14
self.pool = nn.MaxPool2d(kernel_size=2, stride=2) # 無參數學習因此無需設置兩個
self.conv2 = nn.Conv2d(in_channels=28, out_channels=28*2, kernel_size=5) # 7
self.fc1 = nn.Linear(in_features=28*2*4*4, out_features=1024)
self.fc2 = nn.Linear(in_features=1024, out_features=10)
def forward(self, inputs):
x = self.pool(F.relu(self.conv1(inputs)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(inputs.size()[0],-1)
x = F.relu(self.fc1(x))
return self.fc2(x)
下面是卷積的動態演示
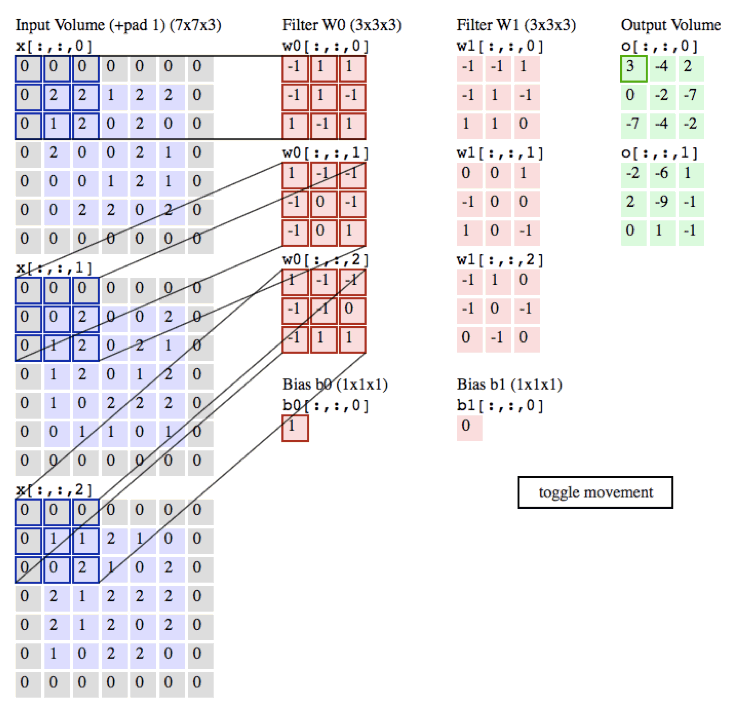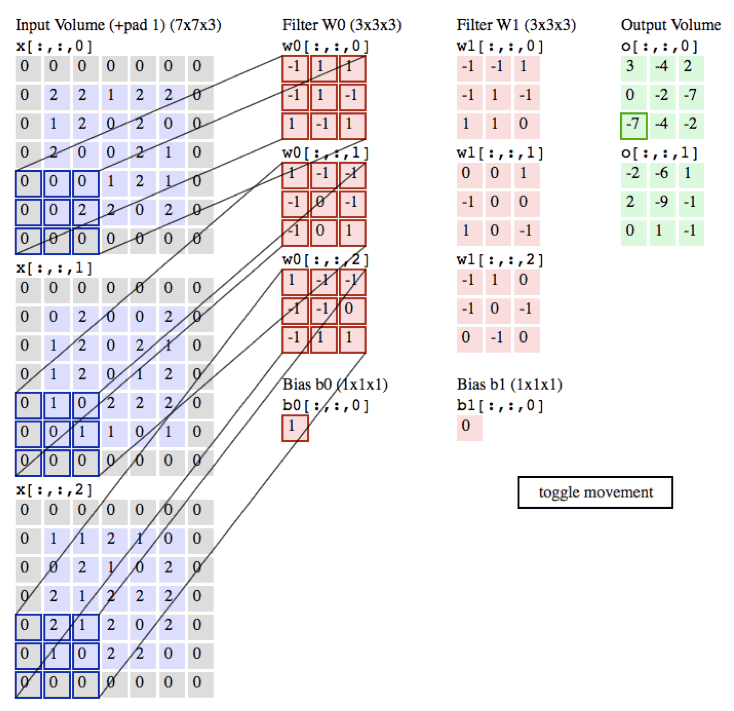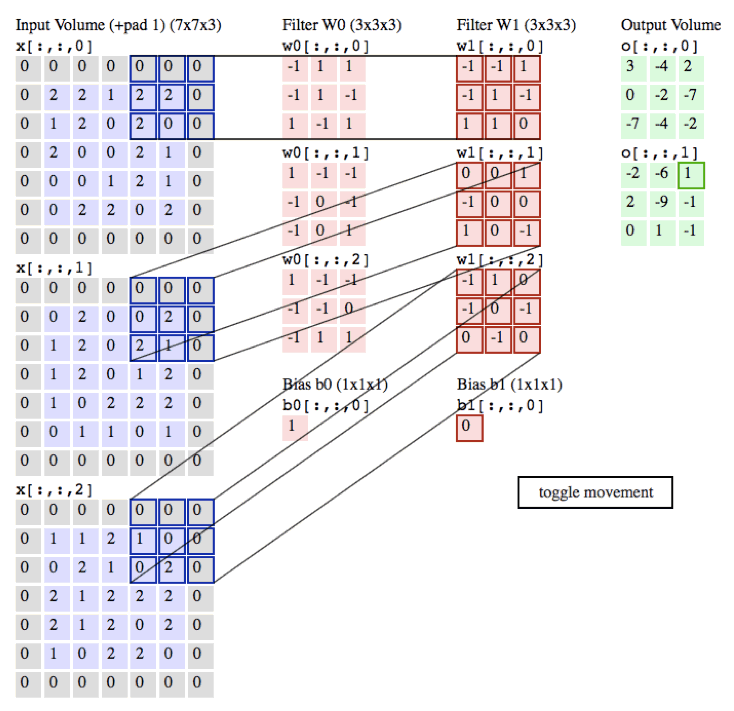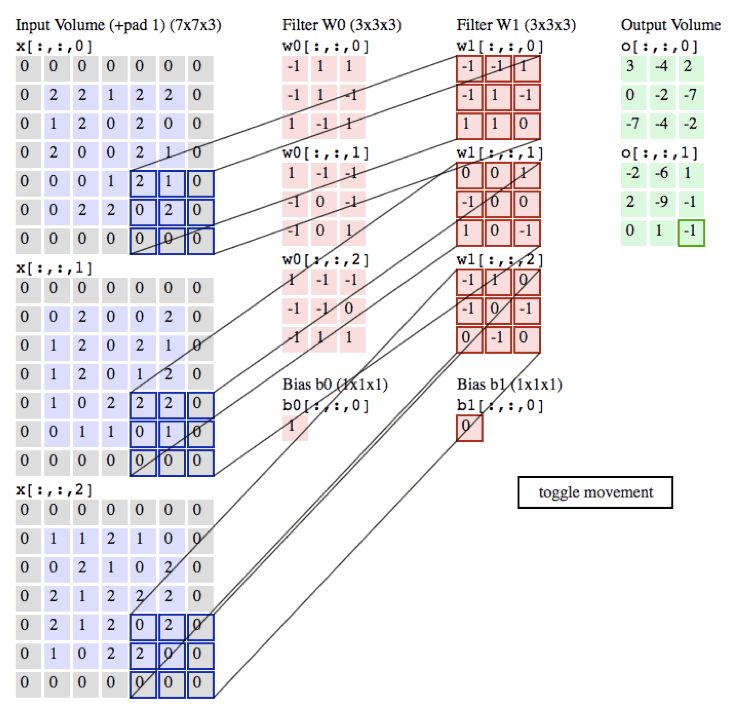
in_channels:為輸入通道數 彩色圖片有3個通道 黑白有1個通道
out_channels:輸出通道數
kernel_size:卷積核的大小
stride:卷積的步長
padding:外邊距大小
輸出的size計算公式
- h = (h – kernel_size + 2*padding)/stride + 1
- w = (w – kernel_size + 2*padding)/stride + 1
MaxPool2d:是沒有參數進行運算的

實例化網絡優化器,並且使用GPU進行訓練
net = Net()
opt = torch.optim.Adam(params=net.parameters(), lr=0.001)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
Net( (conv1): Conv2d(1, 28, kernel_size=(5, 5), stride=(1, 1)) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(28, 56, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=896, out_features=1024, bias=True) (fc2): Linear(in_features=1024, out_features=10, bias=True) )
訓練主要代碼
for epoch in range(50):
for images, labels in trainloader:
images = images.to(device)
labels = labels.to(device)
pre_label = net(images)
loss = F.cross_entropy(input=pre_label, target=labels).mean()
pre_label = torch.argmax(pre_label, dim=1)
acc = (pre_label==labels).sum()/torch.tensor(labels.size()[0], dtype=torch.float32)
net.zero_grad()
loss.backward()
opt.step()
print(acc.detach().cpu().numpy(), loss.detach().cpu().numpy())
F.cross_entropy交叉熵函數

源碼中已經幫助我們實現瞭softmax因此不需要自己進行softmax操作瞭
torch.argmax計算最大數所在索引值
acc = (pre_label==labels).sum()/torch.tensor(labels.size()[0], dtype=torch.float32) # pre_label==labels 相同維度進行比較相同返回True不同的返回False,True為1 False為0, 即可獲取到相等的個數,再除總個數,就得到瞭Accuracy準確度瞭
預測
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=True,num_workers=2) images, labels = iter(testloader).next() images = images.to(device) labels = labels.to(device) with torch.no_grad(): pre_label = net(images) pre_label = torch.argmax(pre_label, dim=1) acc = (pre_label==labels).sum()/torch.tensor(labels.size()[0], dtype=torch.float32) print(acc)
總結
本節我們瞭解瞭標準化數據·、卷積的原理、簡答的構建瞭一個網絡,並讓它去識別手寫體,也是對前面章節的總匯瞭
到此這篇關於超詳細PyTorch實現手寫數字識別器的示例代碼的文章就介紹到這瞭,更多相關PyTorch 手寫數字識別器內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- PyTorch 遷移學習實踐(幾分鐘即可訓練好自己的模型)
- 淺談Pytorch 定義的網絡結構層能否重復使用
- pytorch查看網絡參數顯存占用量等操作
- Pytorch深度學習之實現病蟲害圖像分類
- pytorch如何利用ResNet18進行手寫數字識別