Java並發中的Fork/Join 框架機制詳解
什麼是 Fork/Join 框架
Fork/Join 框架是一種在 JDk 7 引入的線程池,用於並行執行把一個大任務拆成多個小任務並行執行,最終匯總每個小任務結果得到大任務結果的特殊任務。通過其命名也很容易看出框架主要分為 Fork 和 Join 兩個階段,第一階段 Fork 是把一個大任務拆分為多個子任務並行的執行,第二階段 Join 是合並這些子任務的所有執行結果,最後得到大任務的結果。
這裡不難發現其執行主要流程:首先判斷一個任務是否足夠小,如果任務足夠小,則直接計算,否則,就拆分成幾個更小的小任務分別計算,這個過程可以反復的拆分成一系列小任務。Fork/Join 框架是一種基於 分治 的算法,通過拆分大任務成多個獨立的小任務,然後並行執行這些小任務,最後合並小任務的結果得到大任務的最終結果,通過並行計算以提高效率。。
Fork/Join 框架使用示例
下面通過一個計算列表中所有元素的總和的示例來看看 Fork/Join 框架是如何使用的,總的思路是:將這個列表分成許多子列表,然後對每個子列表的元素進行求和,然後,我們再計算所有這些值的總和就得到原始列表的和瞭。Fork/Join 框架中定義瞭 ForkJoinTask 來表示一個 Fork/Join 任務,其提供瞭 fork()、join() 等操作,通常情況下,我們並不需要直接繼承這個 ForkJoinTask 類,而是使用框架提供的兩個 ForkJoinTask 的子類:
- RecursiveAction 用於表示沒有返回結果的 Fork/Join 任務。
- RecursiveTask 用於表示有返回結果的 Fork/Join 任務。
很顯然,在這個示例中是需要返回結果的,可以定義 SumAction 類繼承自 RecursiveTask,代碼入下:
/**
* @author mghio
* @since 2021-07-25
*/
public class SumTask extends RecursiveTask<Long> {
private static final int SEQUENTIAL_THRESHOLD = 50;
private final List<Long> data;
public SumTask(List<Long> data) {
this.data = data;
}
@Override
protected Long compute() {
if (data.size() <= SEQUENTIAL_THRESHOLD) {
long sum = computeSumDirectly();
System.out.format("Sum of %s: %d\n", data.toString(), sum);
return sum;
} else {
int mid = data.size() / 2;
SumTask firstSubtask = new SumTask(data.subList(0, mid));
SumTask secondSubtask = new SumTask(data.subList(mid, data.size()));
// 執行子任務
firstSubtask.fork();
secondSubtask.fork();
// 等待子任務執行完成,並獲取結果
long firstSubTaskResult = firstSubtask.join();
long secondSubTaskResult = secondSubtask.join();
return firstSubTaskResult + secondSubTaskResult;
}
}
private long computeSumDirectly() {
long sum = 0;
for (Long l : data) {
sum += l;
}
return sum;
}
public static void main(String[] args) {
Random random = new Random();
List<Long> data = random
.longs(1_000, 1, 100)
.boxed()
.collect(Collectors.toList());
ForkJoinPool pool = new ForkJoinPool();
SumTask task = new SumTask(data);
pool.invoke(task);
System.out.println("Sum: " + pool.invoke(task));
}
}
這裡當列表大小小於 SEQUENTIAL_THRESHOLD 變量的值(閾值)時視為小任務,直接計算求和列表元素結果,否則再次拆分為小任務,運行結果如下:
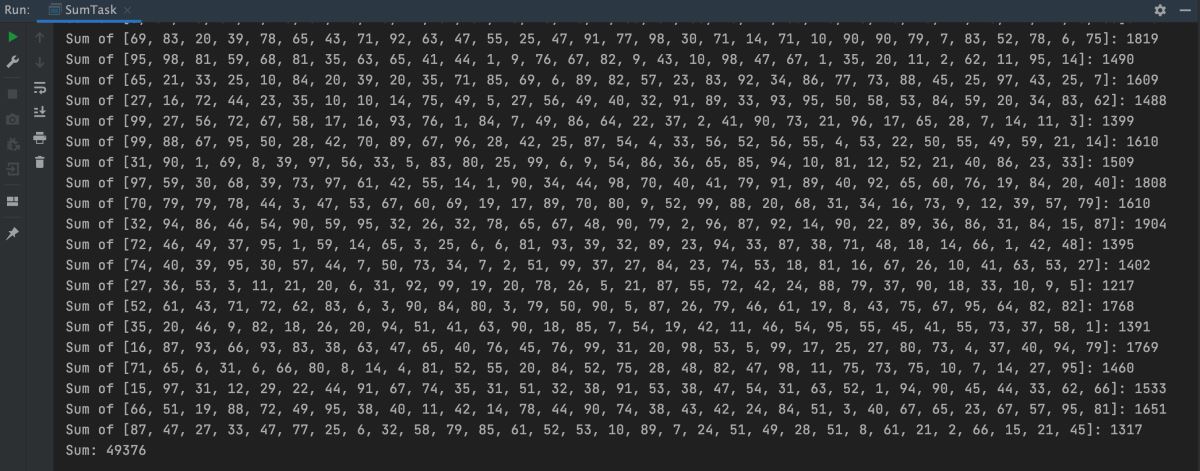
通過這個示例代碼可以發現,Fork/Join 框架 中 ForkJoinTask 任務與平常的一般任務的主要不同點在於:ForkJoinTask 需要實現抽象方法 compute() 來定義計算邏輯,在這個方法裡一般通用的實現模板是,首先先判斷當前任務是否是小任務,如果是,就執行執行任務,如果不是小任務,則再次拆分為兩個子任務,然後當每個子任務調用 fork() 方法時,會再次進入到 compute() 方法中,檢查當前任務是否需要再拆分為子任務,如果已經是小任務,則執行當前任務並返回結果,否則繼續分割,最後調用 join() 方法等待所有子任務執行完成並獲得執行結果。偽代碼如下:
if (problem is small) {
directly solve problem.
} else {
Step 1. split problem into independent parts.
Step 2. fork new subtasks to solve each part.
Step 3. join all subtasks.
Step 4. compose result from subresults.
}
Fork/Join 框架設計
Fork/Join 框架核心思想是把一個大任務拆分成若幹個小任務,然後匯總每個小任務的結果最終得到大任務的結果,如果讓你設計一個這樣的框架,你會如何實現呢?(建議思考一下),Fork/Join 框架的整個流程正如其名所示,分為兩個步驟:
- 大任務分割 需要有這麼一個的類,用來將大任務拆分為子任務,可能一次拆分後的子任務還是比較大,需要多次拆分,直到拆分出來的子任務符合我們定義的小任務才結束。
- 執行任務並合並任務結果 第一步拆分出來的子任務分別存放在一個個 雙端隊列 裡面(P.S. 這裡為什麼要使用雙端隊列請看下文),然後每個隊列啟動一個線程從隊列中獲取任務執行。這些子任務的執行結果都會放到一個統一的隊列中,然後再啟動一個線程從這個隊列中拿數據,最後合並這些數據返回。
Fork/Join 框架使用瞭如下兩個類來完成以上兩個步驟:
- ForkJoinTask 類 在上文的實例中也有提到,表示 ForkJoin 任務,在使用框架時首先必須先定義任務,通常隻需要繼承自 ForkJoinTask 類的子類 RecursiveAction(無返回結果) 或者 RecursiveTask(有返回結果)即可。
- ForkJoinPool 從名字也可以猜到一二瞭,就是用來執行 ForkJoinTask 的線程池。大任務拆分出的子任務會添加到當前線程的雙端隊列的頭部。
喜歡思考的你,心中想必會想到這麼一種場景,當我們需要完成一個大任務時,會先把這個大任務拆分為多個獨立的子任務,這些子任務會放到獨立的隊列中,並為每個隊列都創建一個單獨的線程去執行隊列裡的任務,即這裡線程和隊列時一對一的關系,那麼當有的線程可能會先把自己隊列的任務執行完成瞭,而有的線程則沒有執行完成,這就導致一些先執行完任務的線程幹等瞭,這是個好問題。
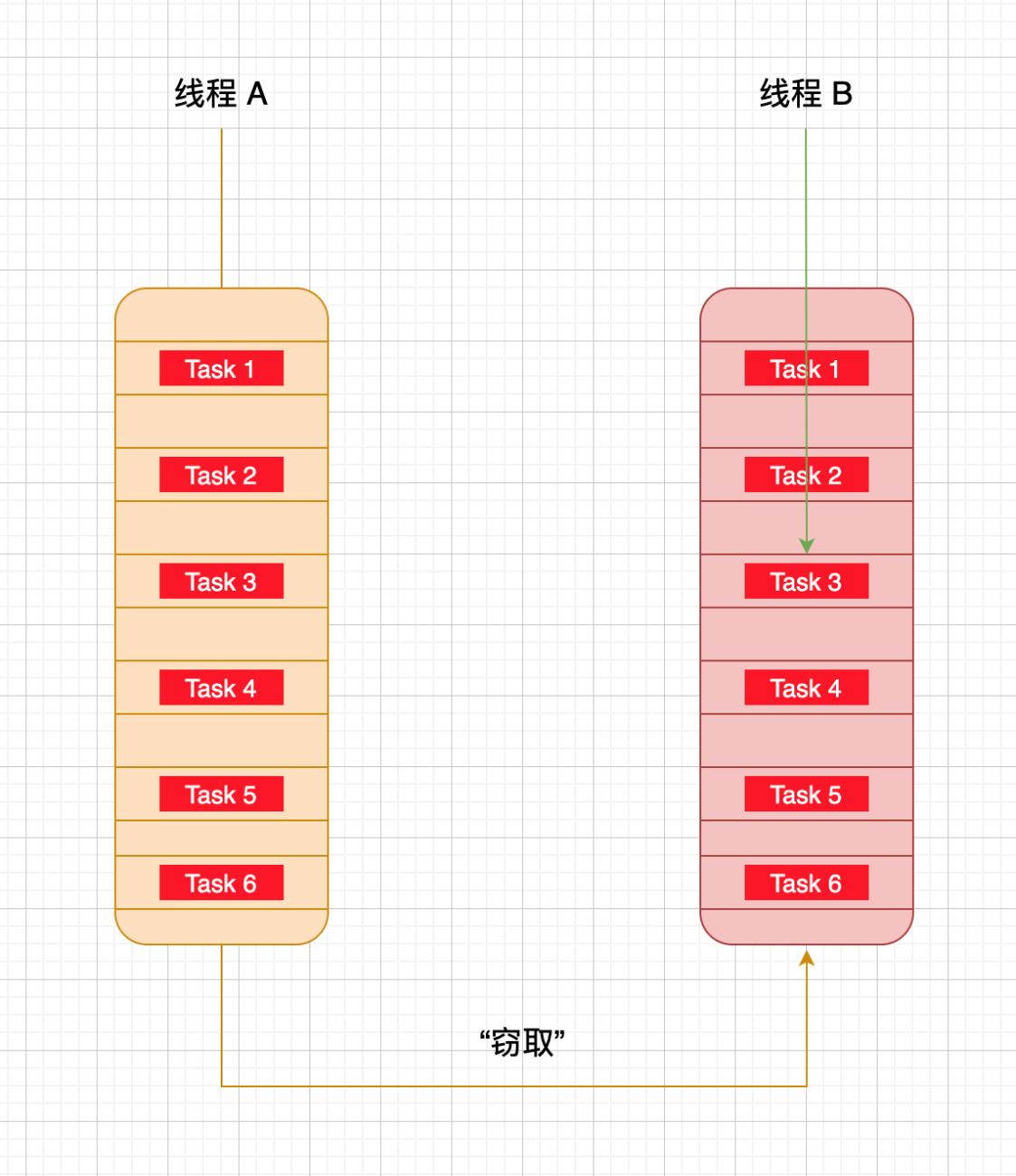
既然是做並發的,肯定要最大程度壓榨計算機的性能,對於這種場景並發大師 Doug Lea 使用瞭工作竊取算法處理,使用工作竊取算法後,先完成自己隊列中任務的線程會去其它線程的隊列中”竊取“一個任務來執行,哈哈,一方有難,八方支援。但是此時這個線程和隊列的持有線程會同時訪問同一個隊列,所以為瞭減少竊取任務的線程和被竊取任務的線程之間的競爭,ForkJoin 選擇瞭雙端隊列這種數據結構,這樣就可以按照這種規則執行任務瞭:被竊取任務的線程始終從隊列頭部獲取任務並執行,竊取任務的線程使用從隊列尾部獲取任務執行。這個算法在絕大部分情況下都可以充分利用多線程進行並行計算,但是在雙端隊列裡隻有一個任務等極端情況下還是會存在一定程度的競爭。
Fork/Join 框架實現原理
Fork/Join 框架的實現核心是 ForkJoinPool 類,該類的重要組成部分為 ForkJoinTask 數組和 ForkJoinWorkerThread 數組,其中 ForkJoinTask 數組用來存放框架使用者給提交給 ForkJoinPool 的任務,ForkJoinWorkerThread 數組則負責執行這些任務。任務有如下四種狀態:
NORMAL 已完成
CANCELLED 被取消
SIGNAL 信號
EXCEPTIONAL 發生異常
下面來看看這兩個類的核心方法實現原理,首先來看 ForkJoinTask 的 fork() 方法,源碼如下:

方法對於 ForkJoinWorkerThread 類型的線程,首先會調用 ForkJoinWorkerThread 的 workQueue 的 push() 方法異步的去執行這個任務,然後馬上返回結果。繼續跟進 ForkJoinPool 的 push() 方法,源碼如下:
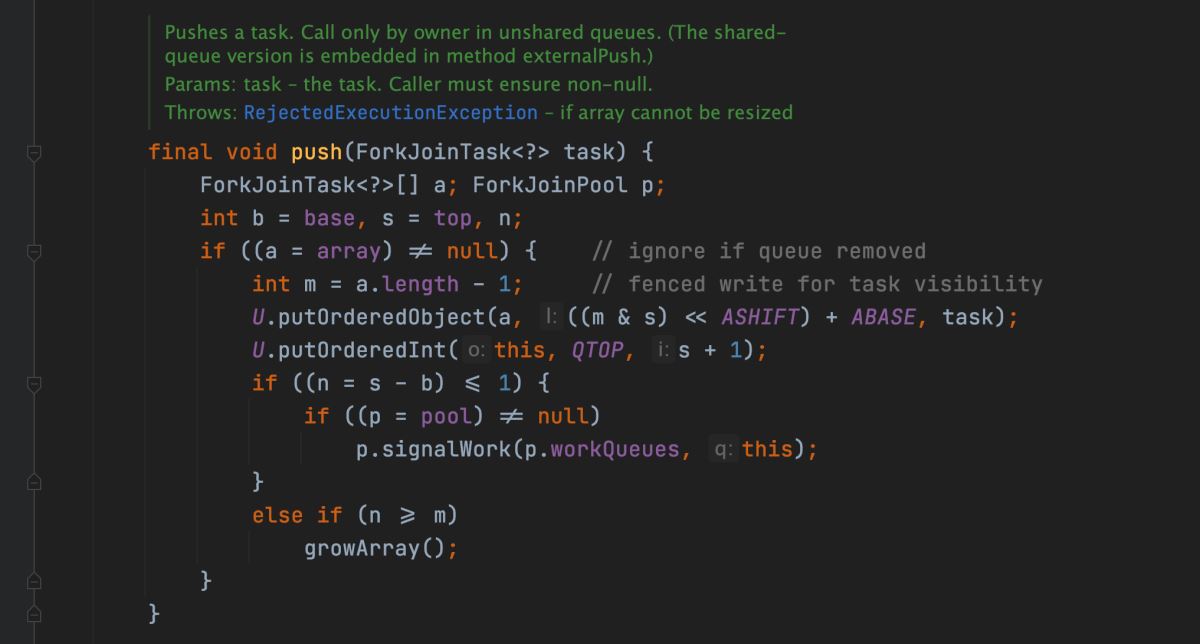
方法將當前任務添加到 ForkJoinTask 任務隊列數組中,然後再調用 ForkJoinPool 的 signalWork 方法創建或者喚醒一個工作線程來執行該任務。然後再來看看 ForkJoinTask 的 join() 方法,方法源碼如下:


方法首先調用瞭 doJoin() 方法,該方法返回當前任務的狀態,根據返回的任務狀態做不同的處理:
- 已完成狀態則直接返回結果
- 被取消狀態則直接拋出異常(CancellationException)
- 發生異常狀態則直接拋出對應的異常
繼續跟進 doJoin() 方法,方法源碼如下:
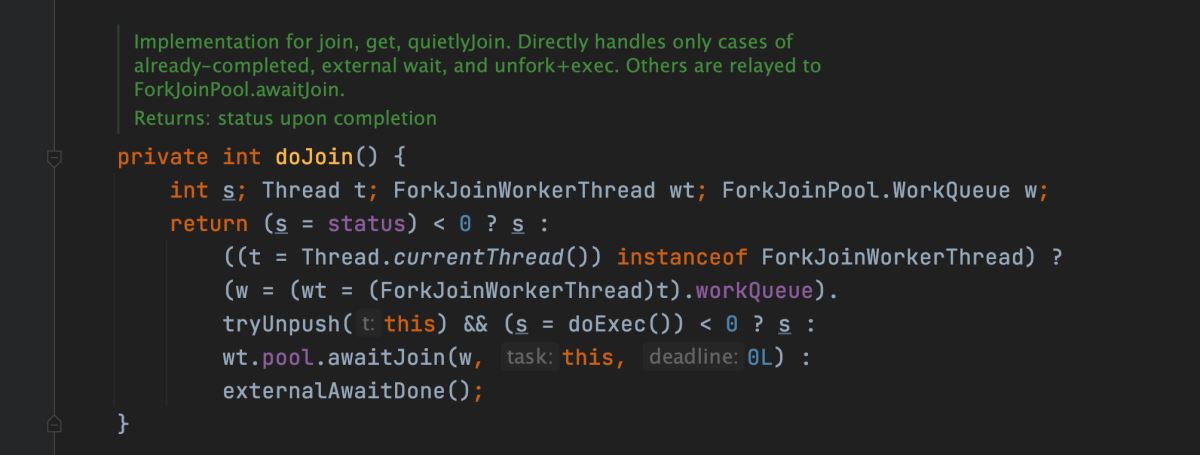
方法首先判斷當前任務狀態是否已經執行完成,如果執行完成則直接返回任務狀態。如果沒有執行完成,則從任務數組中(workQueue)取出任務並執行,任務執行完成則設置任務狀態為 NORMAL,如果出現異常則記錄異常並設置任務狀態為 EXCEPTIONAL(在 doExec() 方法中)。
總結
本文主要介紹瞭 Java 並發框架中的 Fork/Join 框架的基本原理和其使用的工作竊取算法(work-stealing)、設計方式和部分實現源碼。Fork/Join 框架在 JDK 的官方標準庫中也有應用。比如 JDK 1.8+ 標準庫提供的 Arrays.parallelSort(array) 可以進行並行排序,它的原理就是內部通過 Fork/Join 框架對大數組分拆進行並行排序,可以提高排序的速度,還有集合中的 Collection.parallelStream() 方法底層也是基於 Fork/Join 框架實現的,最後就是定義小任務的閾值往往是需要通過測試驗證才能合理給出,並且保證程序可以達到最好的性能。
到此這篇關於Java 並發中的Fork/Join 框架機制詳解的文章就介紹到這瞭,更多相關Java Fork/Join 框架內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Java並發編程之Fork/Join框架的理解
- Java多線程高並發中的Fork/Join框架機制詳解
- 輕輕松松吃透Java並發fork/join框架
- Java 並發編程之ForkJoin框架
- Java線程的並發工具類實現原理解析