Java面試題沖刺第十六天–消息隊列
面試題1:說說你對消息隊列的理解,消息隊列為瞭解決什麼問題?
我們公司業務系統一開始體量較小,很多組件都是單機版就足夠,後來隨著用戶量逐漸擴大,我們程序也采用瞭微服務的設計思想,把很多服務進行瞭拆分,但後來在一些秒殺搶票活動或高頻業務中,服務依舊扛不住大量QPS,因此我們引入瞭消息隊列來優化該類問題。
消息隊列應用的場景大致分為三類:解耦、異步、削峰。
解耦
消息隊列類似設計模式中的觀察者模式(Observer)或發佈-訂閱模式(Pub-Sub)。生產者生成和發送消息到消息隊列,消費者從消息隊列中取走消息進行處理,稱為消費,使用消息隊列將“生產者”和“消費者”之間的操作關聯解耦,易於擴展。
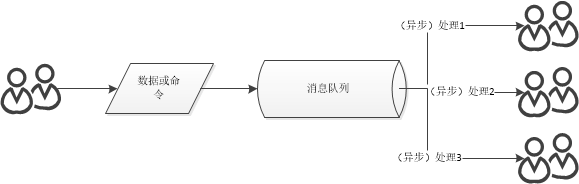
比如系統A為支付系統,一開始用戶支付完調用日志記錄系統B記錄就完瞭,後來內容越來越多,支付完成要調用加積分系統C、短信通知系統D、優惠券系統E等等…
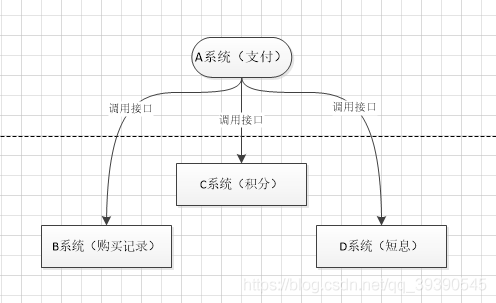
這個場景中,A 系統跟其它各種亂七八糟的系統嚴重耦合,A 系統產生一條支付成功的數據,很多系統接口都需要 A 系統調用把支付成功的數據發送過去。A 系統程序員要時刻考慮這些問題:
- 其他系統如果掛瞭該咋辦?是不是直接程序拋異常瞭?
- 一天到晚加業務,每次都重新部署?領導是不是狗?
那如果引入 MQ,A 系統產生一條數據,發送到 MQ 裡面去,每個子系統加上對消息隊列中支付成功消息的訂閱,持續監聽就可以瞭,哪個系統需要數據自己去 MQ 裡面消費。如果新系統需要數據,直接從 MQ 裡消費即可;如果某個系統不需要這條數據瞭,就取消對 MQ 消息的消費即可。
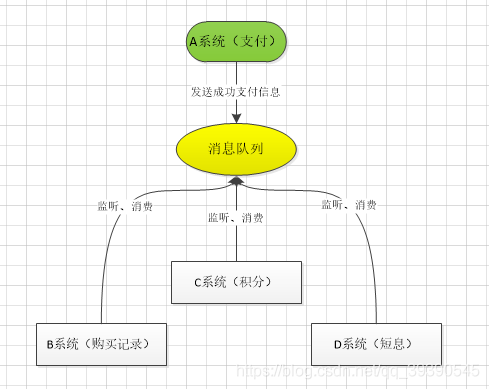
這樣下來,A系統壓根兒不需要去考慮要給誰發送數據,不需要維護這個代碼,也不需要考慮人傢是否調用成功、失敗超時等情況,我隻負責把支付成功的信息放到MQ裡就行瞭,至於能否正常加積分、能否正常短信通知,管我鳥事!~~可見,通過一個 MQ,Pub/Sub 發佈訂閱消息這麼一個模型,A 系統就跟其它系統徹底解耦瞭。
面試官:哦,那我聽出來瞭,你這是喜歡甩鍋啊!來,簡歷還你。

我:額。。不,我開玩笑的,當然不能這樣做,這裡其實涉及到MQ在分佈式事務中數據一致性的問題;聽我跟您解釋。
數據一致性
這個其實是分佈式服務本身就存在的一個問題,不僅僅是消息隊列的問題,但是放在這裡說是因為用瞭消息隊列這個問題會更明顯。
就像咱們上面說的,你支付成功的服務自己保證自己的邏輯成功處理瞭,你成功發瞭消息,但是短信系統,積分系統等等這麼多系統,他們成功還是失敗你就不管瞭?當然不行,這樣坑隊友的行為,狄大人都幫不瞭你~
怎麼辦?那就把所有的服務都放到一個事務裡,所有都成功成功才能算這一次下單是成功的,要成功一起成功,要失敗一起失敗。
異步
A 系統接收一個請求,需要在自己本地寫庫,還需要在 BCD 三個系統寫庫,自己本地寫庫要 3ms,BCD 三個系統分別寫庫要 300ms、400ms、200ms。最終請求總延時是 3 + 300 + 400 + 200 = 903ms,接近 1秒,用戶感覺搞個毛線?慢的一批。
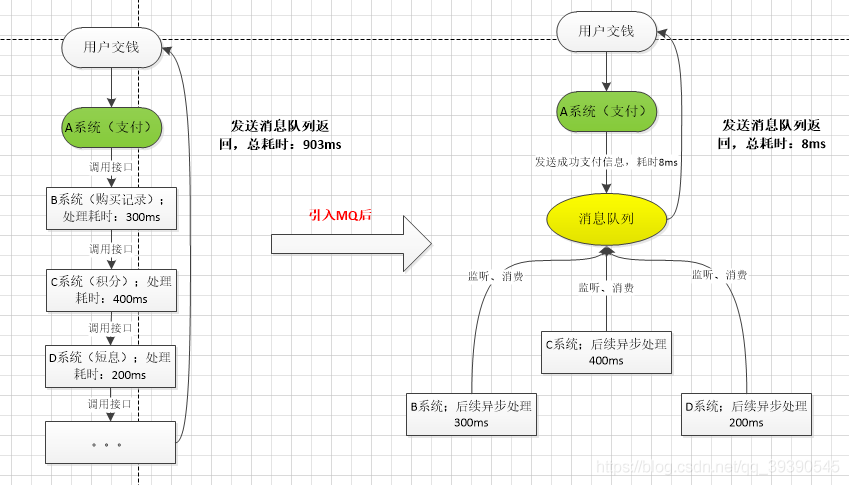
一般互聯網類的企業,對於用戶直接的操作,一般要求是每個請求都必須在 200 ms 以內完成,對用戶幾乎是無感知的,如果1秒足以說明該系統不可用,垃圾系統。
如果這裡使用瞭消息隊列,那麼 A 系統連續發送 3 條消息到 MQ 隊列中,假如耗時 5ms,A 系統從接受一個請求到返回響應給用戶,總時長是 3 + 5 = 8ms,對於用戶而言,其實感覺上就是點個按鈕,8ms 以後就直接返回瞭,體驗感很好
削峰
比如我們系統有代售搶票業務,平時每天QPS也就50左右,A 系統風平浪靜。結果每次一到春運搶票,每秒並發請求數量突然會暴增到10000以上。但是系統是直接基於 MySQL 的,大量的請求直接打到 MySQL,比如一般MySQL能抗2000條請求,現在每秒10000 條 SQL,可能就直接把 MySQL 給打死瞭,導致系統崩潰。但是高峰期一過就又沒人瞭,QPS回到50,對整個系統幾乎沒有任何的壓力。
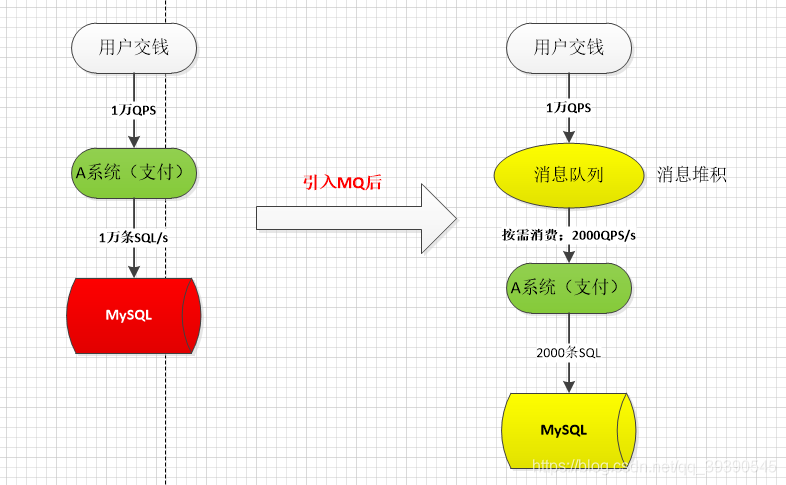
如果這裡使用 MQ,每秒 1w 個請求寫入 MQ,A 系統每秒鐘最多處理 2000 個請求,因為 MySQL 每秒鐘最多處理 2k 個。A 系統從 MQ 中慢慢拉取請求,每秒鐘就拉取 2k 個請求,不要超過自己每秒能處理的最大請求數量就 ok瞭,這樣下來,哪怕是高峰期的時候,A 系統也不會掛掉。當然瞭,用戶的響應時間肯定會受影響,畢竟秒殺嘛,隻要把前多少條請求處理好,其餘的搶票失敗就行瞭。
另外,MQ 每秒鐘 1w 個請求進來,隻處理 2k 個請求出去,結果會導致在中午高峰期,可能有幾十萬甚至幾百萬的請求積壓在 MQ 中。
這個短暫的高峰期積壓是 ok 的,因為高峰期過瞭之後,每秒鐘就 50 個請求進 MQ,但是A 系統依然會按照每秒 2k 個請求的速度在處理。所以說,隻要高峰期一過,A 系統就會快速將積壓的消息給消費掉。
追問1:消息隊列有什麼優缺點
- 系統可用性降低
系統引入的外部依賴越多,越容易掛掉。本來你就是 A 系統調用 BCD 三個系統的接口就好瞭,人 ABCD 四個系統好好的,沒啥問題,你偏加個 MQ 進來,萬一 MQ 掛瞭咋整,MQ 一掛,整套系統崩潰的,你不就完瞭?如何保證消息隊列的高可用?
- 系統復雜度提高
硬生生加個 MQ 進來,你怎麼保證消息一定被消費?如何避免消息重復投遞或重復消費?數據丟失怎麼辦?怎麼保證消息傳遞的順序性?
- 一致性問題
A 系統處理完瞭直接返回成功瞭,人都以為你這個請求就成功瞭;但是問題是,要是 BCD 三個系統那裡,BD 兩個系統寫庫成功瞭,結果 C 系統寫庫失敗瞭,咋整?你這數據就不一致瞭。
面試題2:對於消息中間機,你們是怎麼做技術選型的?
目前市面上比較主流的消息隊列中間件主要有,Kafka、ActiveMQ、RabbitMQ、RocketMQ 等。
ActiveMQ和RabbitMQ這兩由於吞吐量的原因,隻有業務體量一般的公司在用,RabbitMQ由於是erlang語言開發的,我們都不瞭解,因此擴展和維護成本都很高,查個問題都頭疼。
Kafka和RocketMQ一直在各自擅長的領域發光發亮,兩者的吞吐量、可靠性、時效性等都很可觀。
我們通過圖表看看這幾個消息中間機的對比:
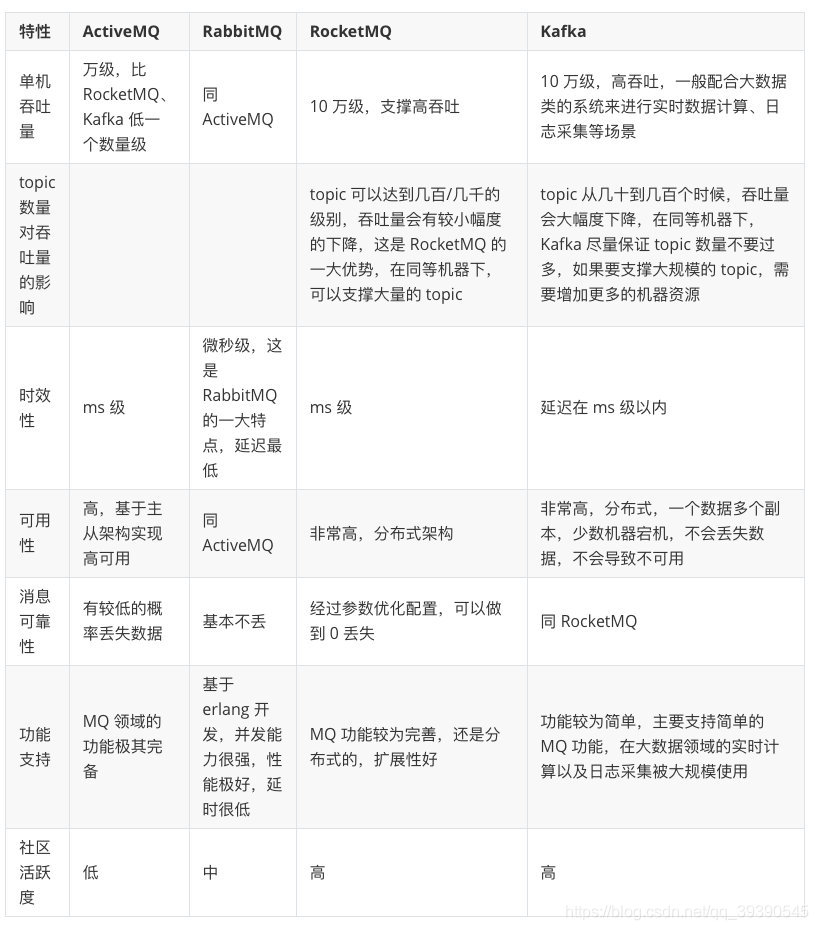
大傢其實一下子就能看到差距瞭,就拿吞吐量來說,早期比較活躍的ActiveMQ 和RabbitMQ基本上不是後兩者的對手瞭,在現在這樣大數據的年代吞吐量是真的很重要。
面試題3:如何確保消息正確地發送至 RabbitMQ?如何確保消息接收方消費瞭消息?
發送方確認模式
將信道設置成confirm模式(發送方確認模式),則所有在信道上發佈的消息都會被指派一個唯一的ID。
一旦消息被投遞到目的隊列後,或者消息被寫入磁盤後(可持久化的消息),信道會發送一個確認給生產者(包含消息唯一ID)。
如果RabbitMQ發生內部錯誤從而導致消息丟失,會發送一條Nack(not acknowledged,未確認)消息。
發送方確認模式是異步的,生產者應用程序在等待確認的同時,可以繼續發送消息。當確認消息到達生產者應用程序,生產者應用程序的回調方法就會被觸發來處理確認消息。
接收方確認機制
消費者接收每一條消息後都必須進行確認(消息接收和消息確認是兩個不同操作)。隻有消費者確認瞭消息,RabbitMQ才能安全地把消息從隊列中刪除。
這裡並沒有用到超時機制,RabbitMQ僅通過Consumer的連接中斷來確認是否需要重新發送消息。也就是說,隻要連接不中斷,RabbitMQ給瞭Consumer足夠長的時間來處理消息。保證數據的最終一致性;
追問1:如何保證MQ消息的可靠傳輸?
以我們常用的RabbitMQ為例,消息不可靠的情況可能是消息丟失,劫持等原因;
丟失又分為:生產者丟失消息、消息隊列丟失消息、消費者丟失消息;
生產者丟失消息:從生產者弄丟數據這個角度來看,RabbitMQ提供confirm模式來確保生產者不丟消息;
confirm模式用的居多:一旦channel進入confirm模式,所有在該信道上發佈的消息都將會被指派一個唯一的ID(從1開始),一旦消息被投遞到所有匹配的隊列之後;RabbitMQ就會發送一個ACK給生產者(包含消息的唯一ID),這就使得生產者知道消息已經正確到達目的隊列瞭;
如果rabbitMQ沒能處理該消息,則會發送一個Nack消息給你,你可以進行重試操作。
消息隊列丟數據:消息持久化。
處理消息隊列丟數據的情況,一般是開啟持久化磁盤的配置。
持久化配置和confirm機制配合使用,在消息持久化磁盤後,再給生產者發送一個Ack信號。
這樣,如果消息持久化磁盤之前,rabbitMQ陣亡瞭,那麼生產者收不到Ack信號,生產者會自動重發。
總結
本篇文章就到這裡瞭,希望能給你帶來幫助,也希望您關註WalkonNet的更多內容!