Redis底層數據結構詳解
Redis作為Key-Value存儲系統,數據結構如下:
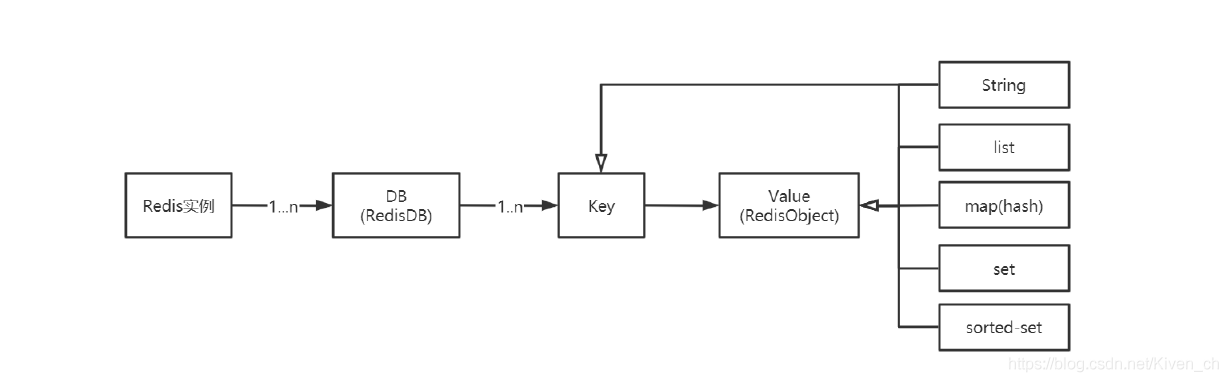
Redis沒有表的概念,Redis實例所對應的db以編號區分,db本身就是key的命名空間。
比如:user:1000作為key值,表示在user這個命名空間下id為1000的元素,類似於user表的id=1000的行。
RedisDB結構
Redis中存在“數據庫”的概念,該結構由redis.h中的redisDb定義。
當redis 服務器初始化時,會預先分配 16 個數據庫
所有數據庫保存到結構 redisServer 的一個成員 redisServer.db 數組中
redisClient中存在一個名叫db的指針指向當前使用的數據庫
RedisDB結構體源碼:
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* 存儲數據庫所有的key-value */
dict *expires; /* 存儲key的過期時間 */
dict *blocking_keys; /* blpop 存儲阻塞key和客戶端對象*/
dict *ready_keys; /* 阻塞後push 響應阻塞客戶端 存儲阻塞後push的key和客戶端對象 */
dict *watched_keys; /* 存儲watch監控的的key和客戶端對象 */
int id; /* Database ID */
long long avg_ttl; /* 存儲的數據庫對象的平均ttl(time to live),用於統計 */
unsigned long expires_cursor; /* 循環過期檢查的光標. */
list *defrag_later; /* 需要嘗試去清理磁盤碎片的鏈表,會慢慢的清理 */
} redisDb;
id
id是數據庫序號,為0-15(默認Redis有16個數據庫)
dict
存儲數據庫所有的key-value,後面要詳細講解
expires
存儲key的過期時間,後面要詳細講解
RedisObject結構
Value是一個對象
包含字符串對象,列表對象,哈希對象,集合對象和有序集合對象
結構信息概覽
typedef struct redisObject {
unsigned type:4; //類型 對象類型
unsigned encoding:4;//編碼
// LRU_BITS為24bit 記錄最後一次被命令程序訪問的時間
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; //引用計數
void *ptr;//指向底層實現數據結構的指針
} robj;
4位type
type 字段表示對象的類型,占 4 位;
REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
當我們執行 type 命令時,便是通過讀取 RedisObject 的 type 字段獲得對象的類型
127.0.0.1:6379> set a1 111 OK 127.0.0.1:6379> type a1 string
4位encoding
encoding 表示對象的內部編碼,占 4 位
每個對象有不同的實現編碼
Redis 可以根據不同的使用場景來為對象設置不同的編碼,大大提高瞭 Redis 的靈活性和效率。
通過 object encoding 命令,可以查看對象采用的編碼方式
127.0.0.1:6379> OBJECT encoding a1 "int"
24位LRU
lru 記錄的是對象最後一次被命令程序訪問的時間,( 4.0 版本占 24 位,2.6 版本占 22 位)。
高16位存儲一個分鐘數級別的時間戳,低8位存儲訪問計數(lfu : 最近訪問次數)
lru—-> 高16位: 最後被訪問的時間
lfu—–>低8位:最近訪問次數
refcount
refcount 記錄的是該對象被引用的次數,類型為整型。
refcount 的作用,主要在於對象的引用計數和內存回收。
當對象的refcount>1時,稱為共享對象
Redis 為瞭節省內存,當有一些對象重復出現時,新的程序不會創建新的對象,而是仍然使用原來的對象。
ptr
ptr 指針指向具體的數據,比如:set hello world,ptr 指向包含字符串 world 的 SDS。
7種type 字符串對象
C語言: 字符數組 “\0”
Redis 使用瞭 SDS(Simple Dynamic String)。用於存儲字符串和整型數據。
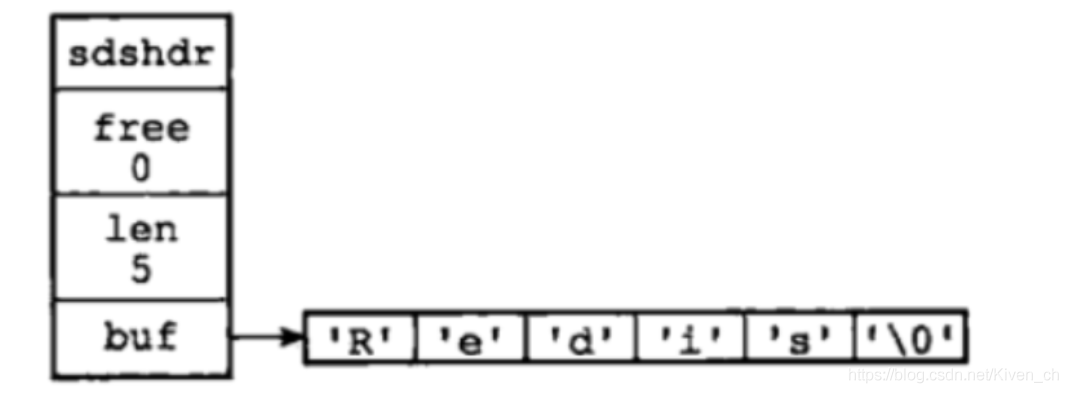
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
buf[] 的長度=len+free+1
SDS的優勢:
1.SDS 在 C 字符串的基礎上加入瞭 free 和 len 字段,獲取字符串長度:SDS 是 O(1),C 字符串是
O(n)。
buf數組的長度=free+len+1
2.SDS 由於記錄瞭長度,在可能造成緩沖區溢出時會自動重新分配內存,杜絕瞭緩沖區溢出。
3.可以存取二進制數據,以字符串長度len來作為結束標識
- C:
\0 空字符串 二進制數據包括空字符串,所以沒有辦法存取二進制數據
- SDS :
非二進制 \0
二進制: 字符串長度 可以存二進制數據
使用場景:
SDS的主要應用在:存儲字符串和整型數據、存儲key、AOF緩沖區和用戶輸入緩沖。
跳躍表(重要)
跳躍表是有序集合(sorted-set)的底層實現,效率高,實現簡單。
跳躍表的基本思想:
將有序鏈表中的部分節點分層,每一層都是一個有序鏈表。
查找
在查找時優先從最高層開始向後查找,當到達某個節點時,如果next節點值大於要查找的值或next指針指向null,則從當前節點下降一層繼續向後查找。
舉例:

查找元素9,按道理我們需要從頭結點開始遍歷,一共遍歷8個結點才能找到元素9。
第一次分層:
遍歷5次找到元素9(紅色的線為查找路徑)

第二次分層:
遍歷4次找到元素9

第三層分層:
遍歷4次找到元素9
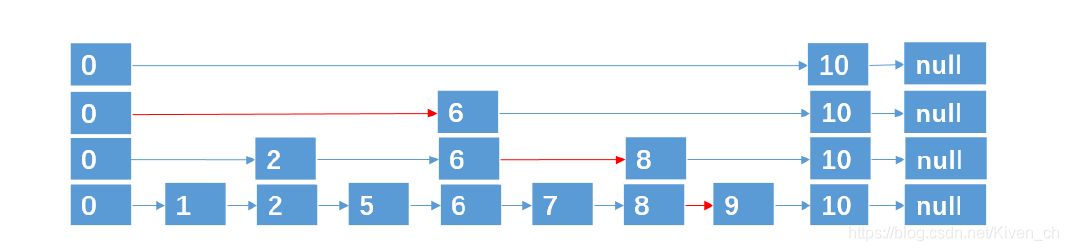
這種數據結構,就是跳躍表,它具有二分查找的功能。
插入與刪除
上面例子中,9個結點,一共4層,是理想的跳躍表。
通過拋硬幣(概率1/2)的方式來決定新插入結點跨越的層數,每層都需要判斷:
正面:插入上層
背面:不插入
達到1/2概率(計算次數)
刪除
找到指定元素並刪除每層的該元素即可
跳躍表特點:
每層都是一個有序鏈表
查找次數近似於層數(1/2)
底層包含所有元素
空間復雜度 O(n) 擴充瞭一倍
Redis跳躍表的實現
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
/* 存儲字符串類型數據 redis3.0版本中使用robj類型表示,但是在redis4.0.1中直接使用sds類型表示 */
sds ele;
/*存儲排序的分值*/
double score;
/*後退指針,指向當前節點最底層的前一個節點*/
struct zskiplistNode *backward;
/*層,柔性數組,隨機生成1-64的值*/
struct zskidictEntryplistLevel {
struct zskiplistNode *forward; //指向本層下一個節點
unsigned long span; //本層下個節點到本節點的元素個數
} level[];
} zskiplistNode;
typedef struct zskiplist {
//表頭節點和表尾節點
struct zskiplistNode *header, *tail;
//表中節點的數量
unsigned long length;
//表中層數最大的節點的層數
int level;
} zskiplist;
完整的跳躍表結構體:
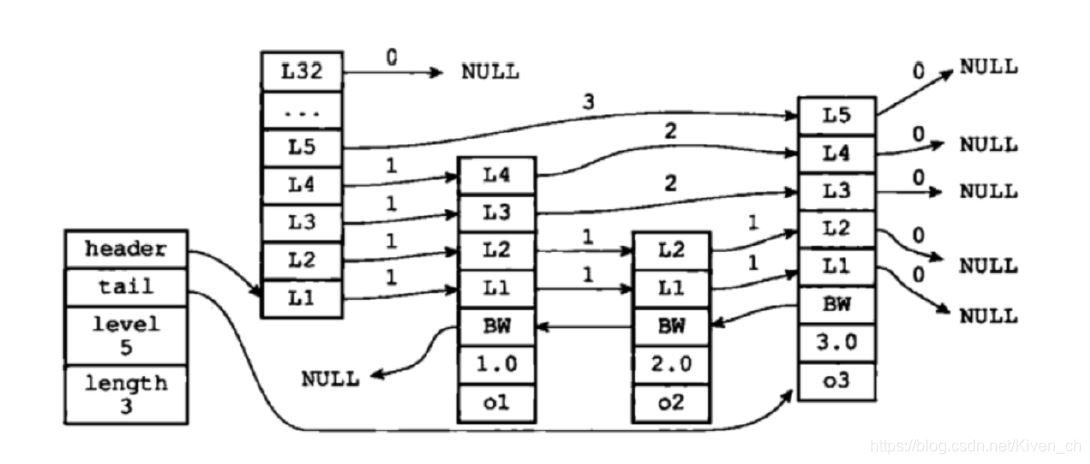
跳躍表的優勢:
1、可以快速查找到需要的節點 O(logn)
2、可以在O(1)的時間復雜度下,快速獲得跳躍表的頭節點、尾結點、長度和高度。
應用場景:有序集合的實現
字典(重要)
字典dict又稱散列表(hash),是用來存儲鍵值對的一種數據結構。
Redis整個數據庫是用字典來存儲的。(K-V結構)
對Redis進行CURD操作其實就是對字典中的數據進行CURD操作。
數組
數組:用來存儲數據的容器,采用頭指針+偏移量的方式能夠以O(1)的時間復雜度定位到數據所在的內存地址。
Redis 海量存儲 快
Hash函數
Hash(散列),作用是把任意長度的輸入通過散列算法轉換成固定類型、固定長度的散列值。
hash函數可以把Redis裡的key:包括字符串、整數、浮點數統一轉換成整數。
key=100.1 String “100.1” 5位長度的字符串
Redis-cli :times 33
Redis-Server : MurmurHash
數組下標=hash(key)%數組容量(hash值%數組容量得到的餘數)
Hash沖突
不同的key經過計算後出現數組下標一致,稱為Hash沖突。
采用單鏈表在相同的下標位置處存儲原始key和value
當根據key找Value時,找到數組下標,遍歷單鏈表可以找出key相同的value
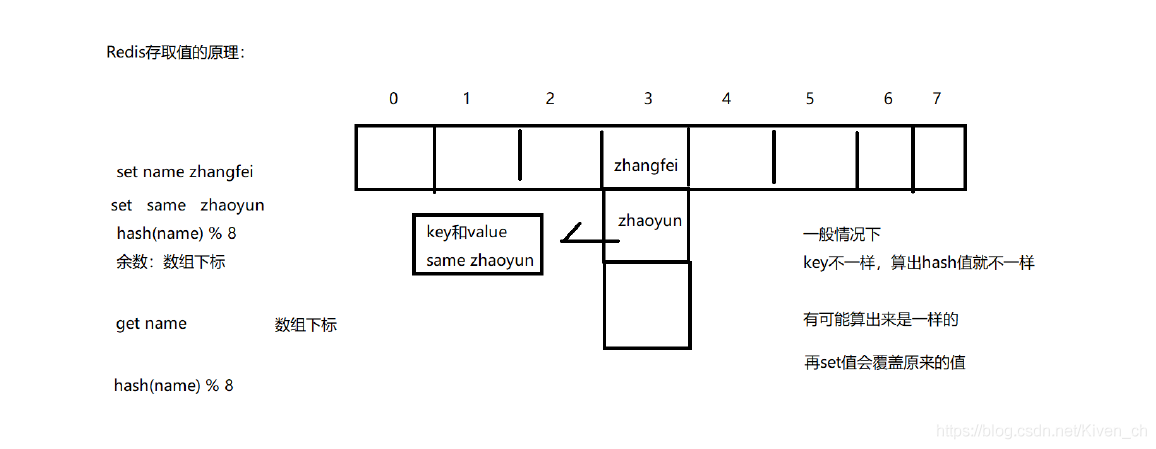
Redis字典的實現
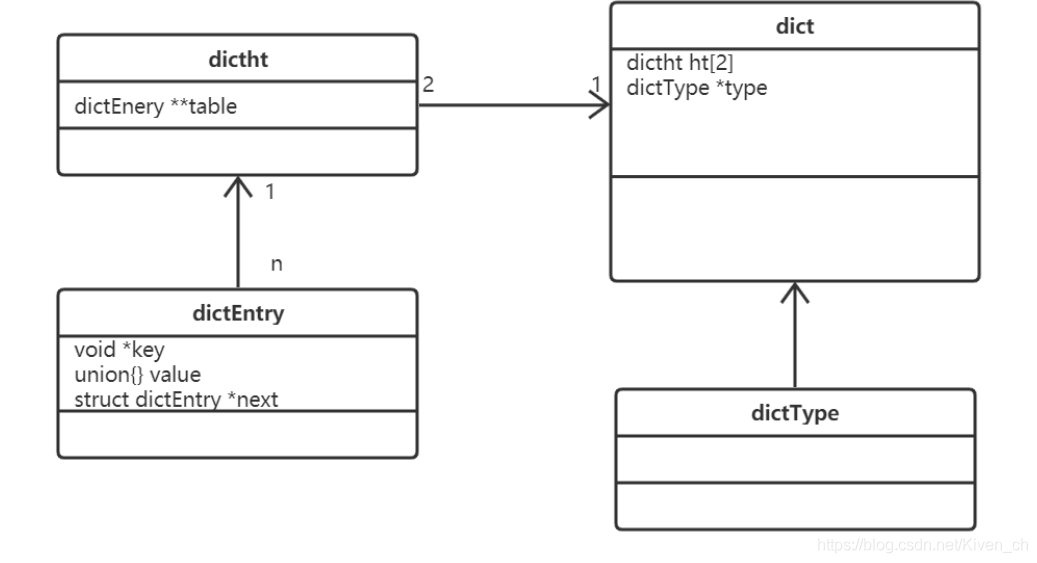
Redis字典實現包括:字典(dict)、Hash表(dictht)、Hash表節點(dictEntry)。
Hash表
typedef struct dictht {
dictEntry **table; // 哈希表數組
unsigned long size; // 哈希表數組的大小
unsigned long sizemask; // 用於映射位置的掩碼,值永遠等於(size-1)
unsigned long used; // 哈希表已有節點的數量,包含next單鏈表數據
} dictht;
1、hash表的數組初始容量為4,隨著k-v存儲量的增加需要對hash表數組進行擴容,新擴容量為當前量的一倍,即4,8,16,32
2、索引值=Hash值&掩碼值(Hash值與Hash表容量取餘)
Hash表節點
typedef struct dictEntry {
void *key; // 鍵
union { // 值v的類型可以是以下4種類型
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一個哈希表節點,形成單向鏈表 解決hash沖突, 單鏈表中會存儲key和value
} dictEntry;
key字段存儲的是鍵值對中的鍵
v字段是個聯合體,存儲的是鍵值對中的值。
next指向下一個哈希表節點,用於解決hash沖突

dict字典
typedef struct dict {
dictType *type; //該字典對應的特定操作函數
void *privdata; //上述類型函數對應的可選參數
dictht ht[2];/* 兩張哈希表,存儲鍵值對數據,ht[0]為原生哈希表,ht[1]為 rehash 哈希表 */
long rehashidx; /* rehash標識 當等於-1時表示沒有在rehash,否則表示正在進行rehash操作,
存儲的值表示hash表 ht[0]的rehash進行到哪個索引值(數組下標)*/
unsigned long iterators; /* 當前運行的迭代器數量 */
} dict;
type字段,指向dictType結構體,裡邊包括瞭對該字典操作的函數指針
typedef struct dictType {
// 計算哈希值的函數
uint64_t (*hashFunction)(const void *key);
// 復制鍵的函數
void *(*keyDup)(void *privdata, const void *key);
// 比較鍵的函數
void *(*valDup)(void *privdata, const void *obj);
// 比較鍵的函數
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 銷毀鍵的函數
void (*keyDestructor)(void *privdata, void *key);
// 銷毀值的函數
void (*valDestructor)(void *privdata, void *obj);
} dictType;
Redis字典除瞭主數據庫的K-V數據存儲以外,還可以用於:散列表對象、哨兵模式中的主從節點管理等在不同的應用中,字典的形態都可能不同,dictType是為瞭實現各種形態的字典而抽象出來的操作函數(多態)。
完整的Redis字典數據結構:
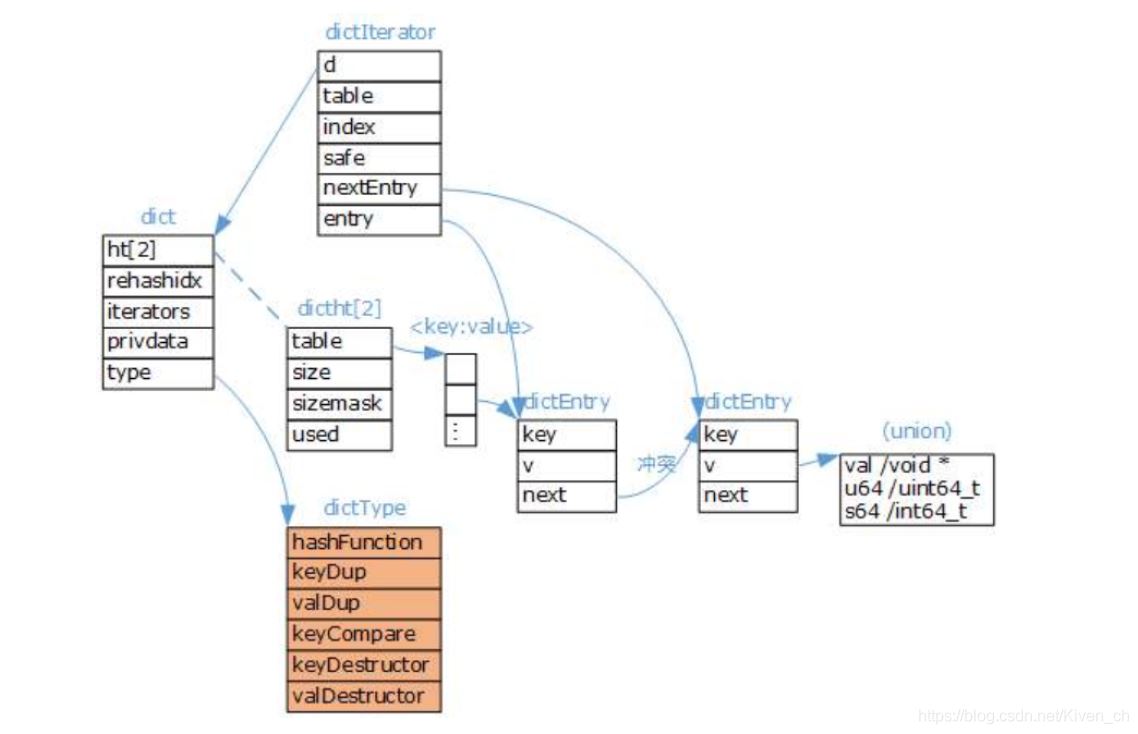
字典擴容
字典達到存儲上限(閾值 0.75),需要rehash(擴容)
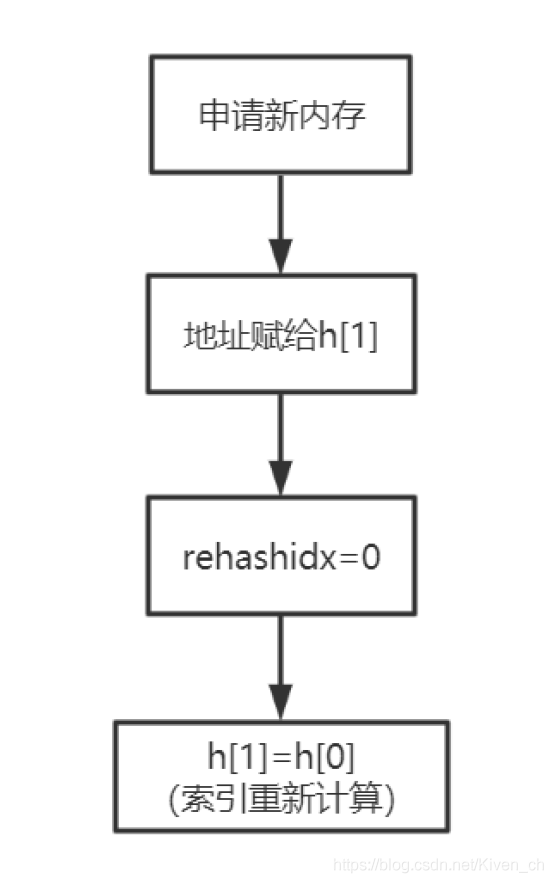
說明:
初次申請默認容量為4個dictEntry,非初次申請為當前hash表容量的一倍。rehashidx=0表示要進行rehash操作。新增加的數據在新的hash表h[1]修改、刪除、查詢在老hash表h[0]、新hash表h[1]中(rehash中)將老的hash表h[0]的數據重新計算索引值後全部遷移到新的hash表h[1]中,這個過程稱為rehash。 漸進式rehash
當數據量巨大時rehash的過程是非常緩慢的,所以需要進行優化。
服務器忙,則隻對一個節點進行rehash
服務器閑,可批量rehash(100節點)
應用場景:
1、主數據庫的K-V數據存儲
2、散列表對象(hash)
3、哨兵模式中的主從節點管理
壓縮列表
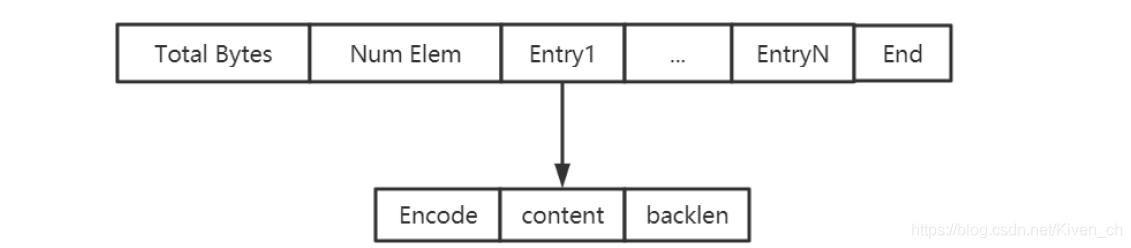
壓縮列表(ziplist)是由一系列特殊編碼的連續內存塊組成的順序型數據結構
節省內存
是一個字節數組,可以包含多個節點(entry)。每個節點可以保存一個字節數組或一個整數。
壓縮列表的數據結構如下:

zlbytes:壓縮列表的字節長度
zltail:壓縮列表尾元素相對於壓縮列表起始地址的偏移量
zllen:壓縮列表的元素個數
entry1…entryX : 壓縮列表的各個節點
zlend:壓縮列表的結尾,占一個字節,恒為0xFF(255)
entryX元素的編碼結構:

previous_entry_length:前一個元素的字節長度
encoding:表示當前元素的編碼
content:數據內容
ziplist結構體如下:
struct ziplist<T>{
unsigned int zlbytes; // ziplist的長度字節數,包含頭部、所有entry和zipend。
unsigned int zloffset; // 從ziplist的頭指針到指向最後一個entry的偏移量,用於快速反向查詢
unsigned short int zllength; // entry元素個數T[] entry; // 元素值
unsigned char zlend; // ziplist結束符,值固定為0xFF
}
typedef struct zlentry {
unsigned int prevrawlensize; //previous_entry_length字段的長度
unsigned int prevrawlen; //previous_entry_length字段存儲的內容
unsigned int lensize; //encoding字段的長度
unsigned int len; //數據內容長度
unsigned int headersize; //當前元素的首部長度,即previous_entry_length字段長度與 encoding字段長度之和。
unsigned char encoding; //數據類型
unsigned char *p; //當前元素首地址
} zlentry;
應用場景:
sorted-set和hash元素個數少且是小整數或短字符串(直接使用)
list用快速鏈表(quicklist)數據結構存儲,而快速鏈表是雙向列表與壓縮列表的組合。(間接使用)
整數集合
整數集合(intset)是一個有序的(整數升序)、存儲整數的連續存儲結構。
當Redis集合類型的元素都是整數並且都處在64位有符號整數范圍內(-2^63 ~ 2^63 -1 ),使用該結構體存儲。
127.0.0.1:6379> SADD set:1 12 6 8 (integer) 3 127.0.0.1:6379> OBJECT encoding set:1 "intset" 127.0.0.1:6379> SADD set:2 1 1000000000000000000000000000000000000000000000000000000 99999999999999999999999999999 (integer) 3 127.0.0.1:6379> OBJECT encoding set:2 "hashtable"
intset的結構圖如下:

typedef struct intset{
//編碼方式
uint32_t encoding;
//集合包含的元素數量
uint32_t length;
//保存元素的數組
int8_t contents[];
}intset;
應用場景:
可以保存類型為int16_t、int32_t 或者int64_t 的整數值,並且保證集合中不會出現重復元素。
快速列表(重要)
快速列表(quicklist)是Redis底層重要的數據結構。是列表的底層實現。(在Redis3.2之前,Redis采用雙向鏈表(adlist)和壓縮列表(ziplist)實現。)在Redis3.2以後結合adlist和ziplist的優勢Redis設計出瞭quicklist。
127.0.0.1:6379> LPUSH list:001 2 3 5 6 7 (integer) 5 127.0.0.1:6379> OBJECT encoding list:001 "quicklist"
雙向列表(adlist)
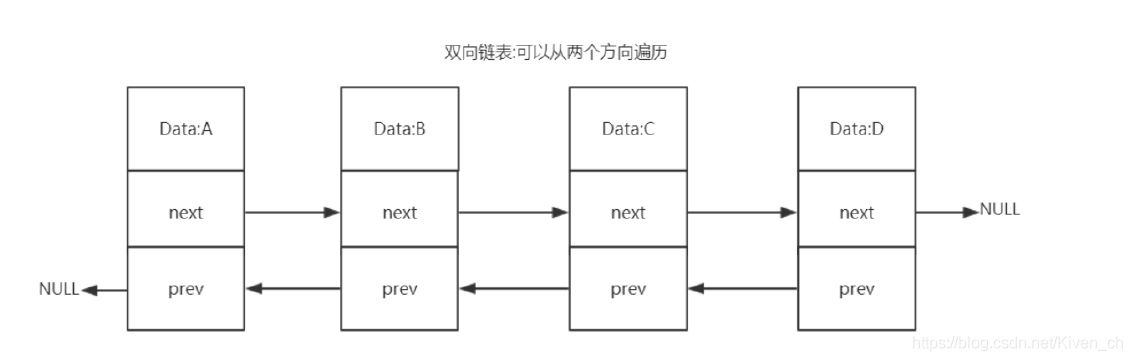
雙向鏈表優勢:
- 雙向:鏈表具有前置節點和後置節點的引用,獲取這兩個節點時間復雜度都為O(1)。
- 普通鏈表(單鏈表):節點類保留下一節點的引用。鏈表類隻保留頭節點的引用,隻能從頭節點插入刪除
- 無環:表頭節點的 prev 指針和表尾節點的 next 指針都指向 NULL,對鏈表的訪問都是以 NULL 結束。
- 環狀:頭的前一個節點指向尾節點
- 帶鏈表長度計數器:通過 len 屬性獲取鏈表長度的時間復雜度為 O(1)。
- 多態:鏈表節點使用 void* 指針來保存節點值,可以保存各種不同類型的值。
快速列表
quicklist是一個雙向鏈表,鏈表中的每個節點時一個ziplist結構。quicklist中的每個節點ziplist都能夠存儲多個數據元素。
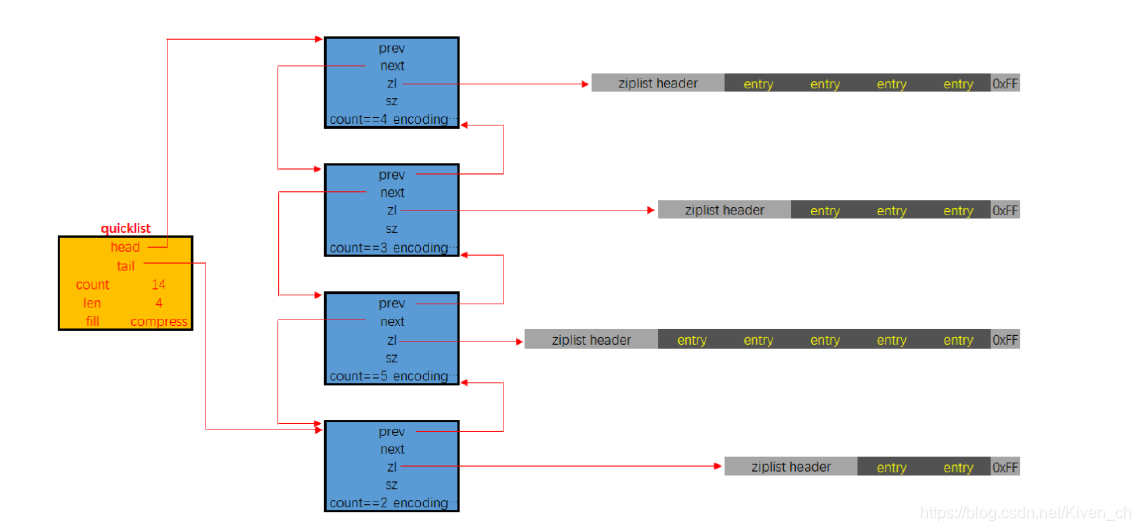
quicklist的結構定義如下:
#if UINTPTR_MAX == 0xffffffff
/* 32-bit */
# define QL_FILL_BITS 14
# define QL_COMP_BITS 14
# define QL_BM_BITS 4
#elif UINTPTR_MAX == 0xffffffffffffffff
/* 64-bit */
# define QL_FILL_BITS 16
# define QL_COMP_BITS 16
# define QL_BM_BITS 4 /* we can encode more, but we rather limit the user
since they cause performance degradation. */
#else
# error unknown arch bits count
#endif
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmakrs are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist {
quicklistNode *head; // 指向quicklist的頭部
quicklistNode *tail; // 指向quicklist的尾部
unsigned long count; /* 列表中所有數據項的個數總和 */
unsigned long len; /* quicklist節點的個數,即ziplist的個數 */
int fill : QL_FILL_BITS; /* ziplist大小限定,由list-max-ziplist-size給定 (Redis設定)*/
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS; /*節點壓縮深度設置,由list-compress-depth給定*/
quicklistBookmark bookmarks[]; /*可選新特性 使用realloc重新分配空間的時候會用到*/
} quicklist;
quicklistNode的結構定義如下:
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev; // 指向上一個ziplist節點
struct quicklistNode *next; // 指向下一個ziplist節點
unsigned char *zl; // 數據指針,如果沒有被壓縮,就指向ziplist結構,反之指向 quicklistLZF結構
unsigned int sz; // 表示指向ziplist結構的總長度(內存占用長度)
unsigned int count : 16; // 表示ziplist中的數據項個數
unsigned int encoding : 2; // 編碼方式,1--ziplist,2--quicklistLZF
unsigned int container : 2; // 預留字段,存放數據的方式,1--NONE,2--ziplist
unsigned int recompress : 1; // 解壓標記,當查看一個被壓縮的數據時,需要暫時解壓,標記此參數為 1,之後再重新進行壓縮
unsigned int attempted_compress : 1; // 測試相關
unsigned int extra : 10; // 擴展字段,暫時沒用
} quicklistNode;
數據壓縮
quicklist每個節點的實際數據存儲結構為ziplist,這種結構的優勢在於節省存儲空間。為瞭進一步降低ziplist的存儲空間,還可以對ziplist進行壓縮。Redis采用的壓縮算法是LZF。其基本思想是:數據與前面重復的記錄重復位置及長度,不重復的記錄原始數據。
壓縮過後的數據可以分成多個片段,每個片段有兩個部分:解釋字段和數據字段。quicklistLZF的結構體如下:
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF {
unsigned int sz; /* LZF壓縮後占用的字節數*/
char compressed[]; //柔性數組,指向數據部分
} quicklistLZF;
應用場景
列表(List)的底層實現、發佈與訂閱、慢查詢、監視器等功能。
流對象
stream主要由:消息、生產者、消費者和消費組構成。
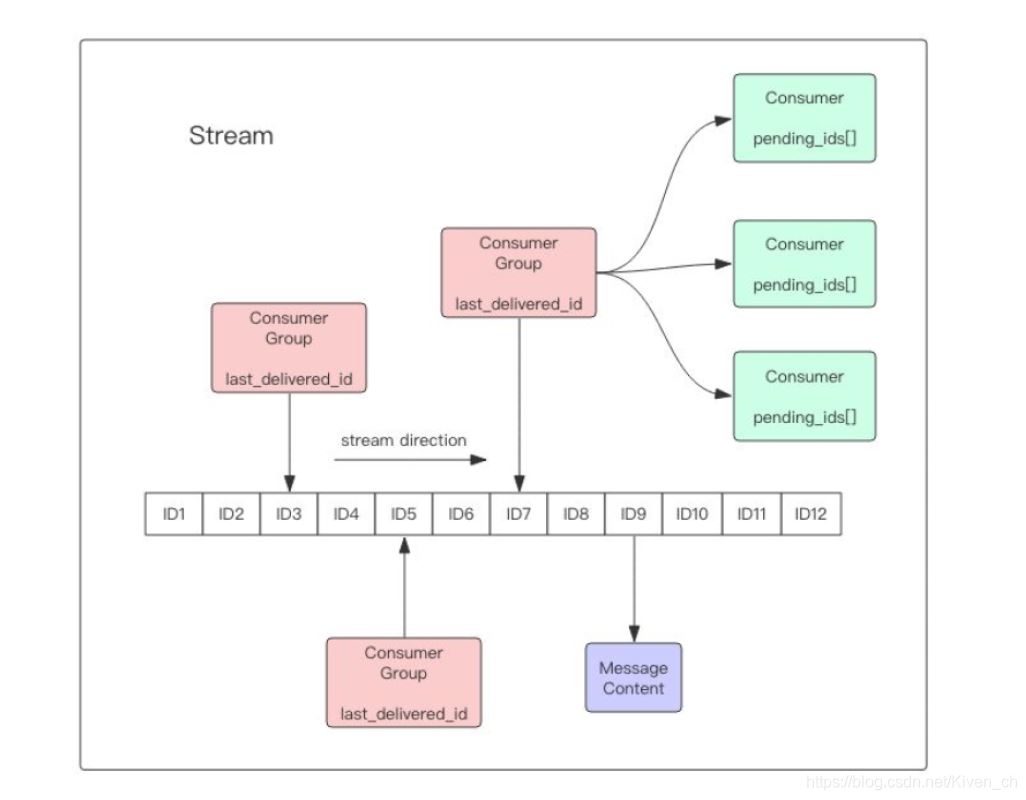
Redis Stream的底層主要使用瞭listpack(緊湊列表)和Rax樹(基數樹)。
listpack
listpack表示一個字符串列表的序列化,listpack可用於存儲字符串或整數。用於存儲stream的消息內容。
結構如下圖:
Rax樹
Rax 是一個有序字典樹 (基數樹 Radix Tree),按照 key 的字典序排列,支持快速地定位、插入和刪除操作。
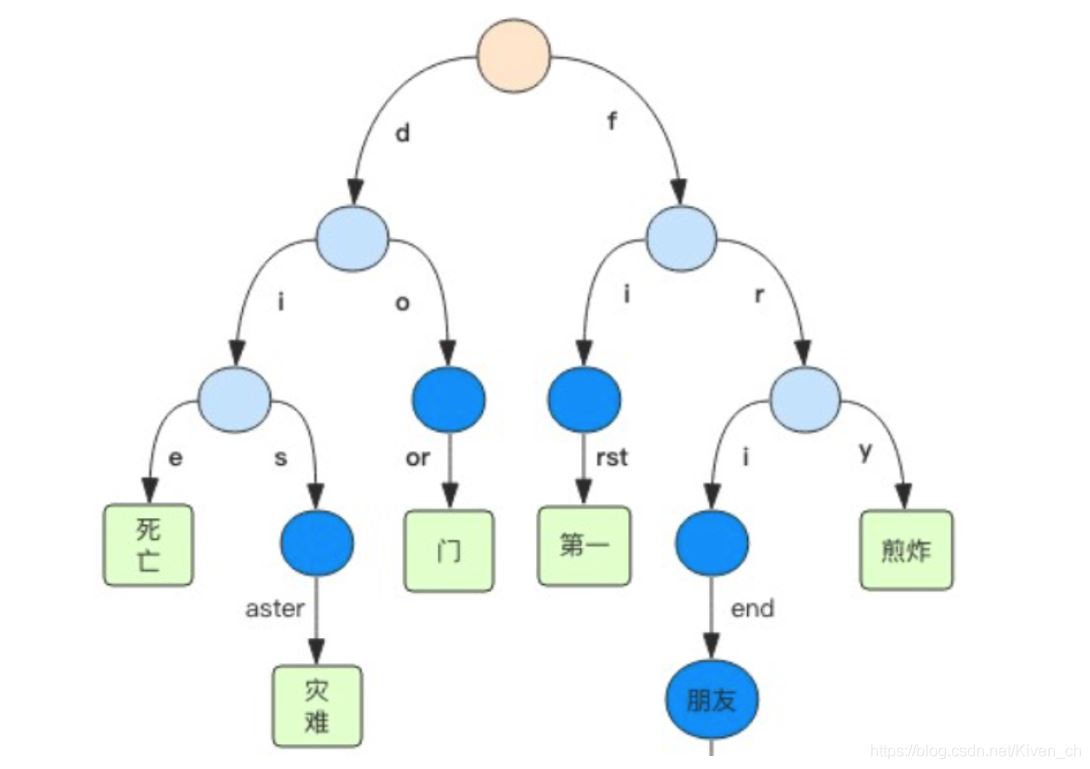
Rax 被用在 Redis Stream 結構裡面用於存儲消息隊列,在 Stream 裡面消息 ID 的前綴是時間戳 + 序號,這樣的消息可以理解為時間序列消息。使用 Rax 結構 進行存儲就可以快速地根據消息 ID 定位到具體的消息,然後繼續遍歷指定消息 之後的所有消息。
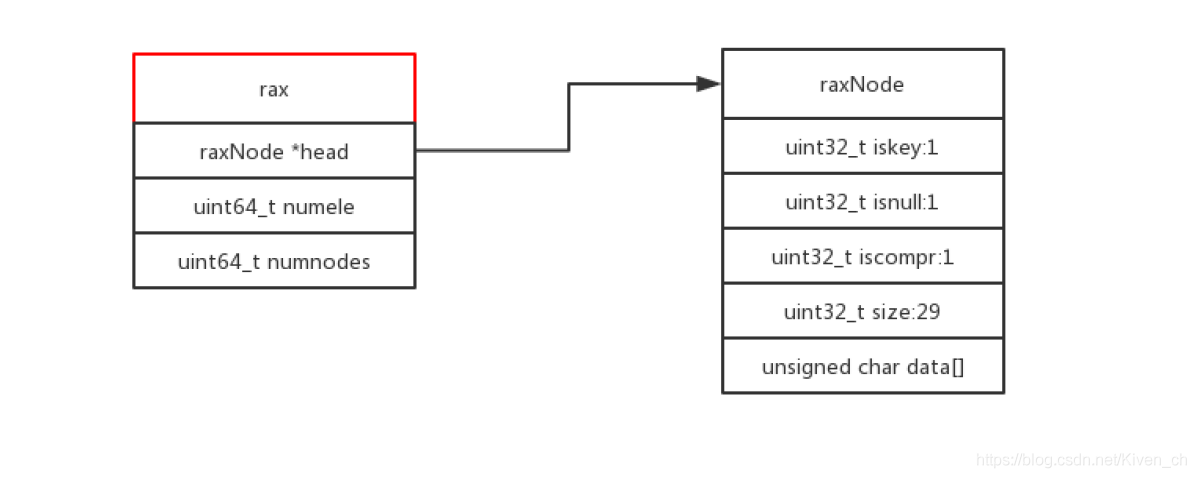
應用場景:
stream的底層實現
10種encoding
/* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 /* Encoded as integer */ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
encoding 表示對象的內部編碼,占 4 位。
Redis通過 encoding 屬性為對象設置不同的編碼
對於少的和小的數據,Redis采用小的和壓縮的存儲方式,體現Redis的靈活性
大大提高瞭 Redis 的存儲量和執行效率
比如Set對象:
intset : 元素是64位以內的整數
hashtable:元素是64位以外的整數
127.0.0.1:6379> sadd set:001 1 3 5 6 2 (integer) 5 127.0.0.1:6379> object encoding set:001 "intset" 127.0.0.1:6379> sadd set:004 1 100000000000000000000000000 9999999999 (integer) 3 127.0.0.1:6379> object encoding set:004 "hashtable"
String
int、raw、embstr
int
REDIS_ENCODING_INT(int類型的整數)
127.0.0.1:6379> set n1 123 OK 127.0.0.1:6379> object encoding n1 "int"
embstr
REDIS_ENCODING_EMBSTR(編碼的簡單動態字符串)
小字符串 長度小於44個字節
127.0.0.1:6379> set name:001 zhangfei OK 127.0.0.1:6379> object encoding name:001 "embstr"
raw
REDIS_ENCODING_RAW (簡單動態字符串)
大字符串 長度大於44個字節
127.0.0.1:6379> set address:001 asdasdasdasdasdasdsadasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdas OK 127.0.0.1:6379> object encoding address:001 "raw"
list
列表的編碼是quicklist。
REDIS_ENCODING_QUICKLIST(快速列表)
127.0.0.1:6379> lpush list:001 1 2 5 4 3 (integer) 5 127.0.0.1:6379> object encoding list:001 "quicklist"
hash
散列的編碼是字典和壓縮列表
dict
REDIS_ENCODING_HT(字典)
當散列表元素的個數比較多或元素不是小整數或短字符串時。
127.0.0.1:6379> hmset user:003 username111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111 zhangfei password 111 num 2300000000000000000000000000000000000000000000000000 OK 127.0.0.1:6379> object encoding user:003 "hashtable"
ziplist
REDIS_ENCODING_ZIPLIST(壓縮列表)
當散列表元素的個數比較少,且元素都是小整數或短字符串時。
127.0.0.1:6379> HSET user:001 username zhanyun password 123456 (integer) 2 127.0.0.1:6379> OBJECT encoding user:001 "ziplist"
set
集合的編碼是整形集合和字典
intset
REDIS_ENCODING_INTSET(整數集合)
當Redis集合類型的元素都是整數並且都處在64位有符號整數范圍內(-9223372036854775808 ~ 9223372036854775807)
127.0.0.1:6379> sadd set:001 1 3 5 6 2 (integer) 5 127.0.0.1:6379> object encoding set:001 "intset"
dict
REDIS_ENCODING_HT(字典)
當Redis集合類型的元素是非整數或都處在64位有符號整數范圍外(>9223372036854775807)
127.0.0.1:6379> sadd set:004 1 100000000000000000000000000 9999999999 (integer) 3 127.0.0.1:6379> object encoding set:004 "hashtable"
zset
有序集合的編碼是壓縮列表和跳躍表+字典
ziplist
REDIS_ENCODING_ZIPLIST(壓縮列表)
當元素的個數比較少,且元素都是小整數或短字符串時。
127.0.0.1:6379> zadd hit:1 100 item1 20 item2 45 item3 (integer) 3 127.0.0.1:6379> object encoding hit:1 "ziplist"
skiplist + dict
REDIS_ENCODING_SKIPLIST(跳躍表+字典)
當元素的個數比較多或元素不是小整數或短字符串時。
127.0.0.1:6379> zadd hit:2 100 item1111111111111111111111111111111111111111111111111111111111111111111111111111 1111111111111111111111111111111111 20 item2 45 item3 (integer) 3 127.0.0.1:6379> object encoding hit:2 "skiplist"
到此這篇關於Redis底層數據結構的文章就介紹到這瞭,更多相關Redis數據結構內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!