詳解如何用Python登錄豆瓣並爬取影評
上一篇我們講過Cookie相關的知識,瞭解到Cookie是為瞭交互式web而誕生的,它主要用於以下三個方面:
- 會話狀態管理(如用戶登錄狀態、購物車、遊戲分數或其它需要記錄的信息)
- 個性化設置(如用戶自定義設置、主題等)
- 瀏覽器行為跟蹤(如跟蹤分析用戶行為等)
我們今天就用requests庫來登錄豆瓣然後爬取影評為例子,用代碼講解下Cookie的會話狀態管理(登錄)功能。
此教程僅用於學習,不得商業獲利!如有侵害任何公司利益,請告知刪除!
一、需求背景
之前豬哥帶大傢爬取瞭優酷的彈幕並生成詞雲圖片,發現優酷彈幕的質量並不高,有很多介詞和一些無效詞,比如:哈哈、啊啊、這些、那些。。。而豆瓣口碑一直不錯,有些書或者電影的推薦都很不錯,所以我們今天來爬取下豆瓣的影評,然後生成詞雲,看看效果如何吧!
二、功能描述
我們使用requests庫登錄豆瓣,然後爬取影評,最後生成詞雲!
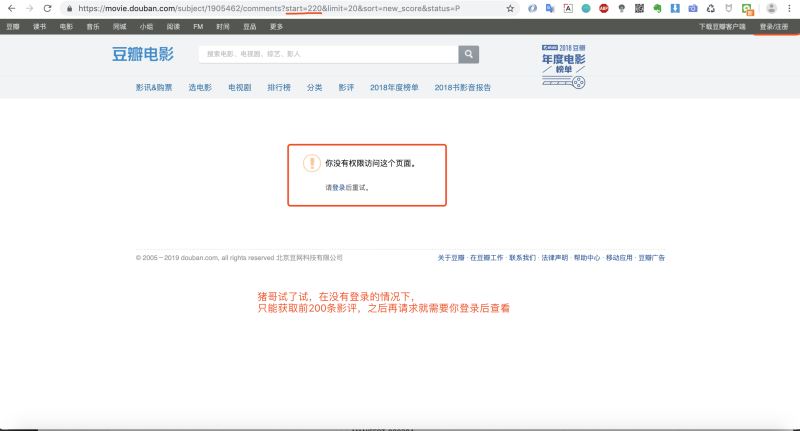
為什麼我們之前的案例(京東、優酷等)中不需要登錄,而今天爬取豆瓣需要登錄呢?那是因為豆瓣在沒有登錄狀態情況下隻允許你查看前200條影評,之後就需要登錄才能查看,這也算是一種反扒手段!
三、技術方案
我們看下簡單的技術方案,大致可以分為三部分:
- 分析豆瓣的登錄接口並用requests庫實現登錄並保存cookie
- 分析豆瓣影評接口實現批量抓取數據
- 使用詞雲做影評數據分析
方案確定之後我們就開始實際操作吧!
四、登錄豆瓣
做爬蟲前我們都是先從瀏覽器開始,使用調試窗口查看url。
1.分析豆瓣登錄接口
打開登錄頁面,然後調出調試窗口,輸入用戶名和密碼,點擊登錄。
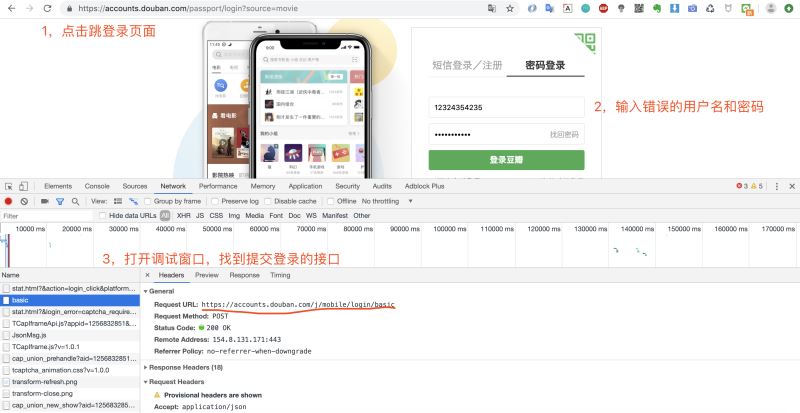
這裡豬哥建議輸入錯誤的密碼,這樣就不會因為頁面跳轉而捕捉不到請求!上面我們便獲取到登錄請求的URL:https://accounts.douban.com/j/mobile/login/basic
因為是一個POST請求,所以我們還需要看看請求登錄時攜帶的參數,我們將調試窗口往下拉查看Form Data。
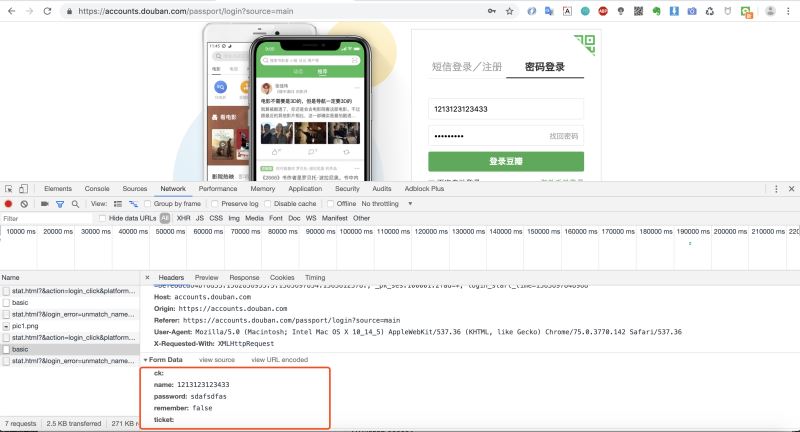
2.代碼實現登錄豆瓣
得到登錄請求URL和參數後,我們就可以來用requests庫來寫一個登錄功能!

3.保存會話狀態
上期我們在爬取優酷彈幕的時候我們是復制瀏覽器中的Cookie到請求頭中這來來保存會話狀態,但是我們如何讓代碼自動保存Cookie呢?
也許你見過或者使用過urllib庫,它用來保存Cookie的方式如下:
cookie = http.cookiejar.CookieJar() handler = urllib.request.HttpCookieProcessor(cookie) opener = urllib.request.build_opener(handler) opener(url)
但是前面我們介紹requests庫的時候就說過:
requests庫是一個基於urllib/3的第三方網絡庫,它的特點是功能強大,API優雅。由上圖我們可以看到,對於http客戶端python官方文檔也推薦我們使用requests庫,實際工作中requests庫也是使用的比較多的庫。
所以今天我們來看看requests庫是如何優雅的幫我們自動保存Cookie的?我們來對代碼做一點微調,使之能自動保存Cookie維持會話狀態!
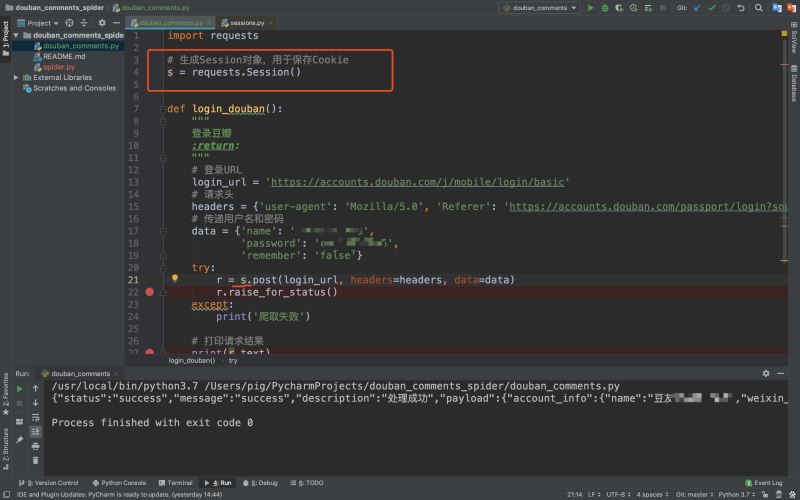
上述代碼中,我們做瞭兩處改動:
- 在最上面增加一行
s = requests.Session(),生成Session對象用來保存Cookie - 發起請求不再是原來的requests對象,而是變成瞭Session對象
我們可以看到發起請求的對象變成瞭session對象,它和原來的requests對象發起請求方式一樣,隻不過它每次請求會自動帶上Cookie,所以後面我們都用Session對象來發起請求!
4.這個Session對象是我們常說的session嗎?
講到這裡也許有同學會問:requests.Session對象是不是我們常說的session呢?
答案當然不是,我們常說的session是保存在服務端的,而requests.Session對象隻是一個用於保存Cookie的對象而已,我們可以看看它的源碼介紹
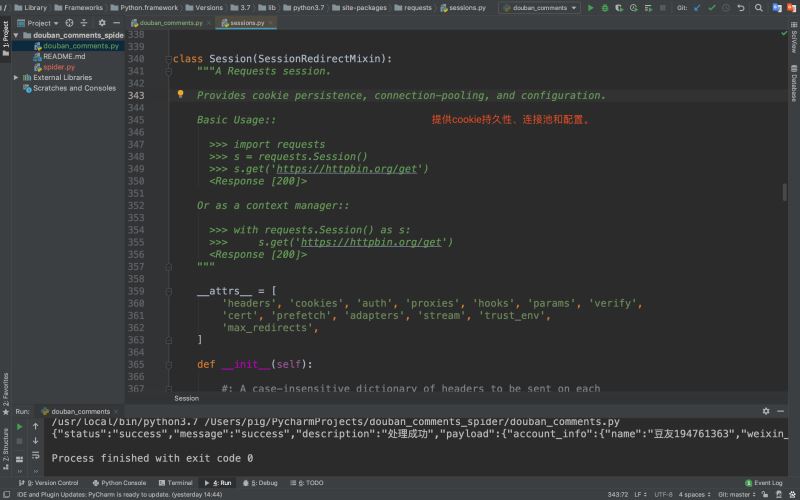
所以大傢千萬不要將requests.Session對象與session技術搞混瞭!
五、爬取影評
我們實現瞭登錄和保存會話狀態之後,就可以開始幹正事啦!
1.分析豆瓣影評接口
首先在豆瓣中找到自己想要分析的電影,這裡豬哥選擇一部美國電影**《荒野生存》**,因為這部電影是豬哥心中之最,沒有之一!
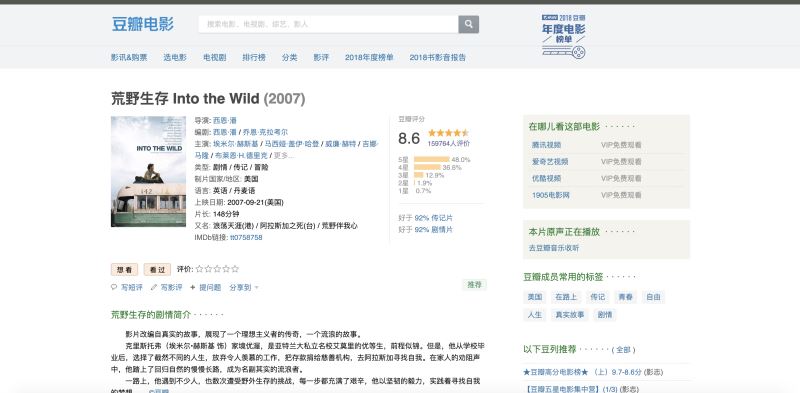
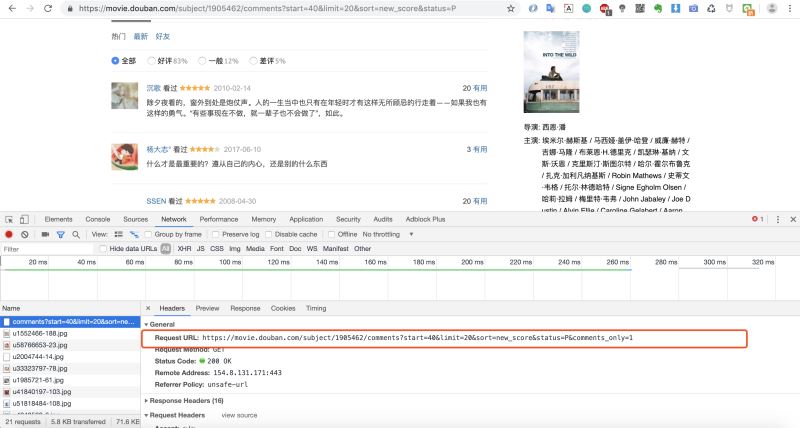
然後下拉找到影評,調出調試窗口,找到加載影評的URL
2.爬取一條影評數據
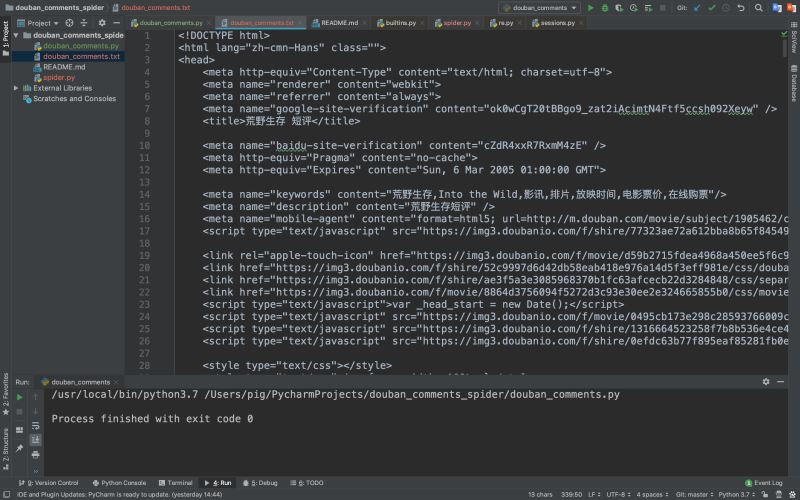
但是爬取下來的是一個HTML網頁數據,我們需要將影評數據提取出來
3.影評內容提取
上圖中我們可以看到爬取返回的是html,而影評數據便是嵌套在html標簽中,如何提取影評內容呢?
這裡我們使用正則表達式來匹配想要的標簽內容,當然也有更高級的提取方法,比如使用某些庫(比如bs4、xpath等)去解析html提取內容,而且使用庫效率也比較高,但這是我們後面的內容,我們今天就用正則來匹配!
我們先來分析下返回html 的網頁結構
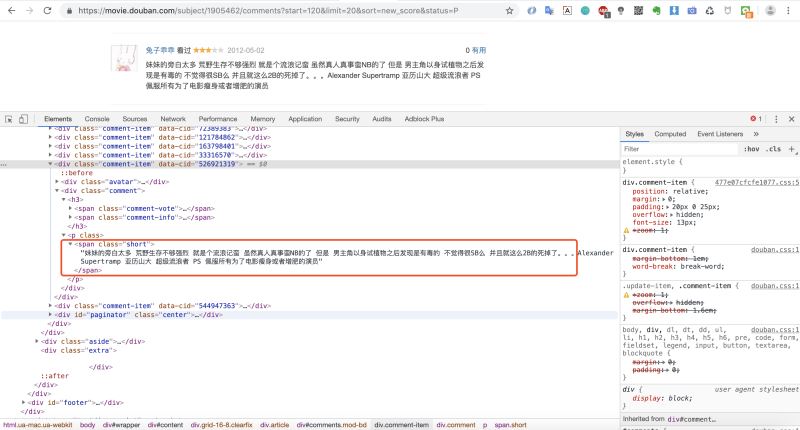
我們發現影評內容都是在<span class="short"></span>這個標簽裡,那我們 就可以寫正則來匹配這個標簽裡的內容啦!

檢查下提取的內容
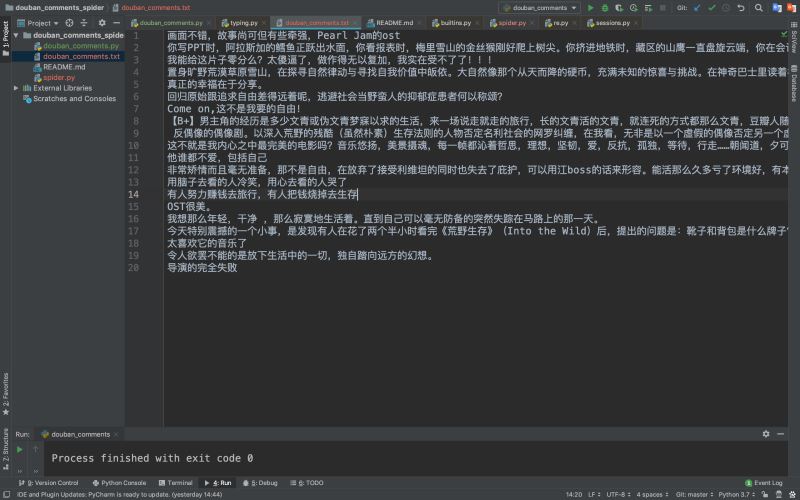
4.批量爬取
我們爬取、提取、保存完一條數據之後,我們來批量爬取一下。根據前面幾次爬取的經驗,我們知道批量爬取的關鍵在於找到分頁參數,我們可以很快發現URL中有一個start參數便是控制分頁的參數。
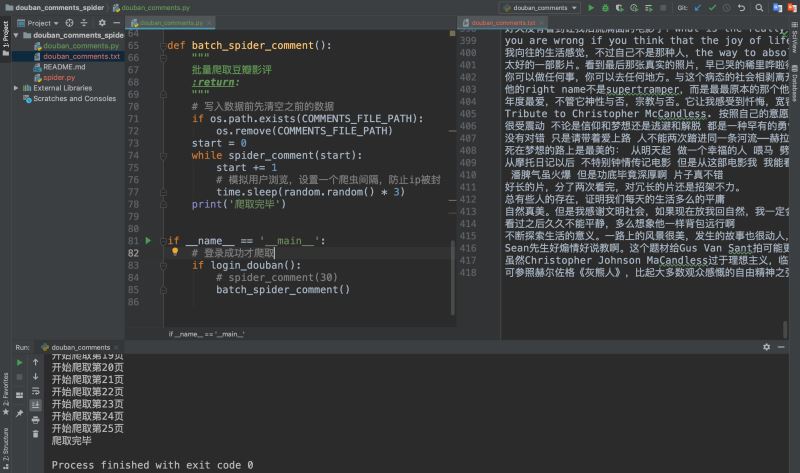
這裡隻爬取瞭25頁就爬完,我們可以去瀏覽器中驗證一下,是不是真的隻有25頁,豬哥驗證過確實隻有25頁!
六、分析影評
數據抓取下來之後,我們就來使用詞雲分析一下這部電影吧!
基於使用詞雲分析的案例前面已經講過兩個瞭,所以豬哥隻會簡單的講解一下!
1.使用結巴分詞
因為我們下載的影評是一段一段的文字,而我們做的詞雲是統計單詞出現的次數,所以需要先分詞!

2.使用詞雲分析
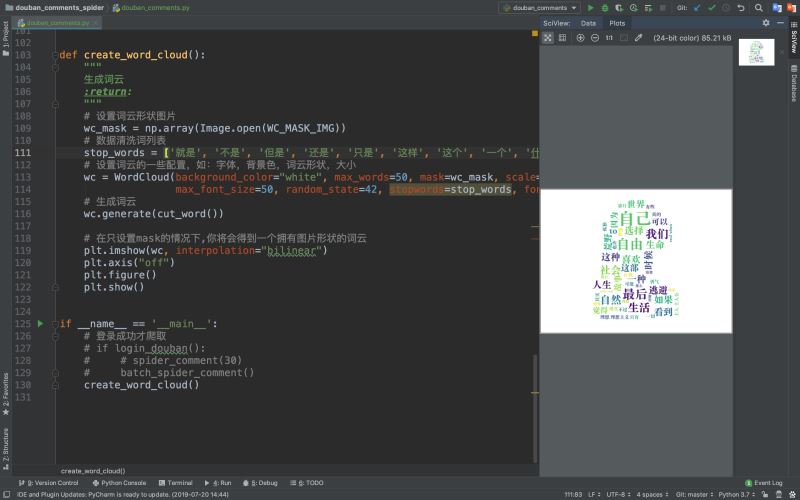
最終成果:

從這些詞中我們可以知道這是關於一部關於追尋自我與現實生活的電影,豬哥裂墻推薦!!!
七、總結
今天我們以爬取豆瓣為例子,學到瞭不少的東西,來總結一下:
- 學習如何使用requests庫發起POST請求
- 學習瞭如何使用requests庫登錄網站
- 學習瞭如何使用requests庫的Session對象保持會話狀態
- 學習瞭如何使用正則表達式提取網頁標簽中的內容
鑒於篇幅有限,爬蟲過程中遇到的很多細節和技巧並沒有完全寫出來,所以希望大傢能自己動手實踐
源碼地址:https://github.com/pig6/douban_comments_spider
到此這篇關於詳解如何用Python登錄豆瓣並爬取影評的文章就介紹到這瞭,更多相關Python爬取影評內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python爬蟲基礎之urllib的使用
- python爬蟲用request庫處理cookie的實例講解
- python模擬登陸網站的示例
- Python爬蟲中urllib3與urllib的區別是什麼
- Python爬蟲之urllib庫詳解