MySQL是怎麼保證主備一致的
拋出問題:大傢知道 binlog 可以用來歸檔,也可以用來做主備同步,但它的內容是什麼樣的呢?為什麼備庫執行瞭 binlog 就可以跟主庫保持一致瞭呢?
MySQL 主備的基本原理
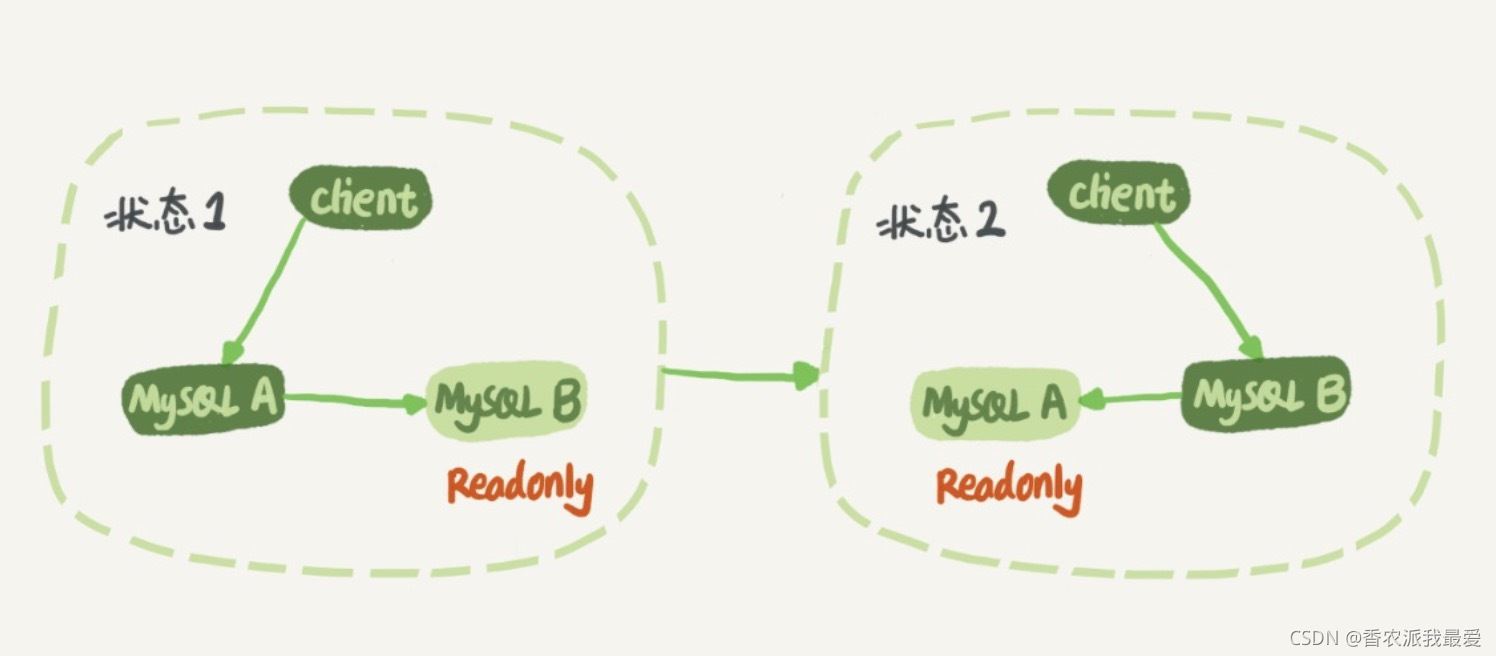
圖 1 MySQL 主備切換流程
在狀態 1 中,客戶端的讀寫都直接訪問節點 A,而節點 B 是 A 的備庫,隻是將 A 的更新都同步過來,到本地執行。這樣可以保持節點 B 和 A 的數據是相同的。
當需要切換的時候,就切成狀態 2。這時候客戶端讀寫訪問的都是節點 B,而節點 A 是 B 的備庫。
在狀態 1 中,雖然節點 B 沒有被直接訪問,但是建議你把節點 B(也就是備庫)設置成隻讀(readonly)模式。這樣做,有以下幾個考慮:
- 有時候一些運營類的查詢語句會被放到備庫上去查,設置為隻讀可以防止誤操作;
- 防止切換邏輯有 bug,比如切換過程中出現雙寫,造成主備不一致;
- 可以用 readonly 狀態,來判斷節點的角色。
我把備庫設置成隻讀瞭,還怎麼跟主庫保持同步更新呢?
這個問題,你不用擔心。因為 readonly 設置對超級 (super) 權限用戶是無效的,而用於同步更新的線程,就擁有超級權限。

圖 2 主備流程圖
主庫接收到客戶端的更新請求後,執行內部事務的更新邏輯,同時寫 binlog。備庫 B 跟主庫 A 之間維持瞭一個長連接。主庫 A 內部有一個線程,專門用於服務備庫 B 的這個長連接。一個事務日志同步的完整過程是這樣的:
- 在備庫 B 上通過 change master 命令,設置主庫 A 的 IP、端口、用戶名、密碼,以及要從哪個位置開始請求 binlog,這個位置包含文件名和日志偏移量。
- 在備庫 B 上執行 start slave 命令,這時候備庫會啟動兩個線程,就是圖中的 io_thread 和 sql_thread。其中 io_thread 負責與主庫建立連接。
- 主庫 A 校驗完用戶名、密碼後,開始按照備庫 B 傳過來的位置,從本地讀取 binlog,發給 B。
- 備庫 B 拿到 binlog 後,寫到本地文件,稱為中轉日志(relay log)。
- sql_thread 讀取中轉日志,解析出日志裡的命令,並執行。
後來由於多線程復制方案的引入,sql_thread 演化成為瞭多個線程。
binlog 的三種格式對比
binlog 有兩種格式,一種是 statement,一種是 row。可能你在其他資料上還會看到有第三種格式,叫作 mixed,其實它就是前兩種格式的混合。
mysql> CREATE TABLE t ( id int(11) NOT NULL, a int(11) DEFAULT NULL, t_modified timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (id), KEY a (a), KEY t_modified(t_modified) ) ENGINE=InnoDB; insert into t values(1,1,'2018-11-13'); insert into t values(2,2,'2018-11-12'); insert into t values(3,3,'2018-11-11'); insert into t values(4,4,'2018-11-10'); insert into t values(5,5,'2018-11-09');
如果要在表中刪除一行數據的話,我們來看看這個 delete 語句的 binlog 是怎麼記錄的。
mysql> delete from t /comment/ where a>=4 and t_modified<='2018-11-10' limit 1;
當 binlog_format=statement 時,binlog 裡面記錄的就是 SQL 語句的原文。你可以用mysql> show binlog events in ‘master.000001′;命令看 binlog 中的內容。

圖 3 statement 格式 binlog 示例
現在,我們來看一下圖 3 的輸出結果。
- 第一行 SET @@SESSION.GTID_NEXT=’ANONYMOUS’你可以先忽略,後面文章我們會在介紹主備切換的時候再提到;
- 第二行是一個 BEGIN,跟第四行的 commit 對應,表示中間是一個事務;
- 第三行就是真實執行的語句瞭。可以看到,在真實執行的 delete 命令之前,還有一個“use ‘test’”命令。這條命令不是我們主動執行的,而是 MySQL 根據當前要操作的表所在的數據庫,自行添加的。這樣做可以保證日志傳到備庫去執行的時候,不論當前的工作線程在哪個庫裡,都能夠正確地更新到 test 庫的表 t。
- use ‘test’命令之後的 delete 語句,就是我們輸入的 SQL 原文瞭。可以看到,binlog“忠實”地記錄瞭 SQL 命令,甚至連註釋也一並記錄瞭。
- 最後一行是一個 COMMIT。你可以看到裡面寫著 xid=61。
為瞭說明 statement 和 row 格式的區別,我們來看一下這條 delete 命令的執行效果圖:

圖 4 delete 執行 warnings
運行這條 delete 命令產生瞭一個 warning,原因是當前 binlog 設置的是 statement 格式,並且語句中有 limit,所以這個命令可能是 unsafe 的。為什麼這麼說呢?這是因為 delete 帶 limit,很可能會出現主備數據不一致的情況。
如果 delete 語句使用的是索引 a,那麼會根據索引 a 找到第一個滿足條件的行,也就是說刪除的是 a=4 這一行;
但如果使用的是索引 t_modified,那麼刪除的就是 t_modified=’2018-11-09’也就是 a=5 這一行。
由於 statement 格式下,記錄到 binlog 裡的是語句原文,因此可能會出現這樣一種情況:在主庫執行這條 SQL 語句的時候,用的是索引 a;而在備庫執行這條 SQL 語句的時候,卻使用瞭索引 t_modified。因此,MySQL 認為這樣寫是有風險的。
如果我把 binlog 的格式改為 binlog_format=‘row’, 是不是就沒有這個問題瞭呢?
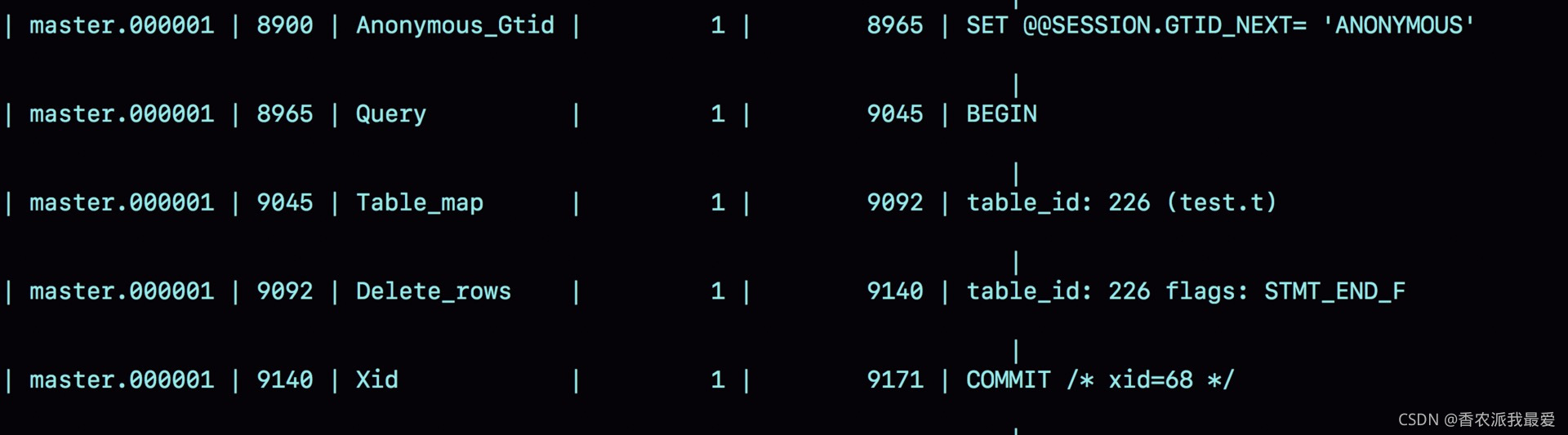
圖 5 row 格式 binlog 示例
與 statement 格式的 binlog 相比,前後的 BEGIN 和 COMMIT 是一樣的。但是,row 格式的 binlog 裡沒有瞭 SQL 語句的原文,而是替換成瞭兩個 event:Table_map 和 Delete_rows。
- Table_map event,用於說明接下來要操作的表是 test 庫的表 t;
- Delete_rows event,用於定義刪除的行為。
借助 mysqlbinlog 工具,用下面這個命令解析和查看 binlog 中的內容。這個事務的 binlog 是從 8900 這個位置開始的,所以可以用 start-position 參數來指定從這個位置的日志開始解析。
mysqlbinlog -vv data/master.000001 --start-position=8900;
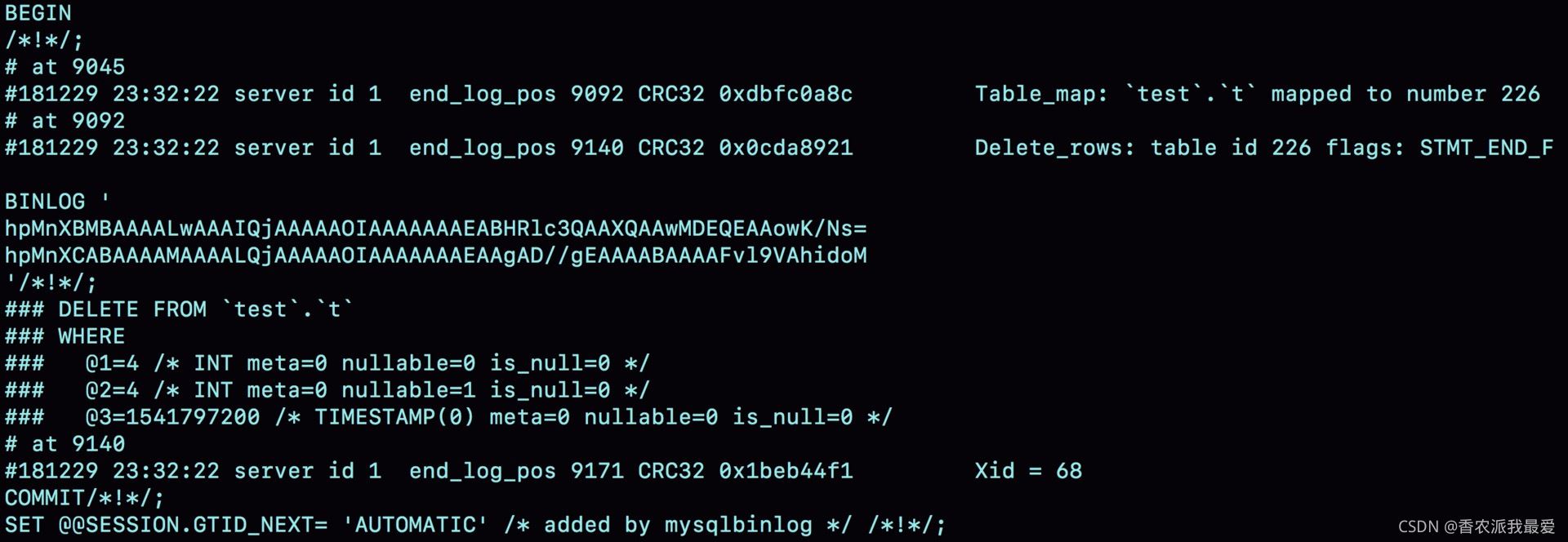
圖 6 row 格式 binlog 示例的詳細信息
從這個圖中,我們可以看到以下幾個信息:
- server id 1,表示這個事務是在 server_id=1 的這個庫上執行的。
- 每個 event 都有 CRC32 的值,這是因為我把參數 binlog_checksum 設置成瞭 CRC32。
- Table_map event 跟在圖 5 中看到的相同,顯示瞭接下來要打開的表,map 到數字 226。現在我們這條 SQL 語句隻操作瞭一張表,如果要操作多張表呢?每個表都有一個對應的 Table_map event、都會 map 到一個單獨的數字,用於區分對不同表的操作。
- 我們在 mysqlbinlog 的命令中,使用瞭 -vv 參數是為瞭把內容都解析出來,所以從結果裡面可以看到各個字段的值(比如,@1=4、 @2=4 這些值)。
- binlog_row_image 的默認配置是 FULL,因此 Delete_event 裡面,包含瞭刪掉的行的所有字段的值。如果把binlog_row_image 設置為 MINIMAL,則隻會記錄必要的信息,在這個例子裡,就是隻會記錄 id=4 這個信息。
最後的 Xid event,用於表示事務被正確地提交瞭。
binlog_format 使用 row 格式的時候,binlog 裡面記錄瞭真實刪除行的主鍵 id,這樣 binlog 傳到備庫去的時候,就肯定會刪除 id=4 的行,不會有主備刪除不同行的問題。
為什麼會有 mixed 格式的 binlog?
因為有些 statement 格式的 binlog 可能會導致主備不一致,所以要使用 row 格式。
但 row 格式的缺點是,很占空間。比如你用一個 delete 語句刪掉 10 萬行數據,用 statement 的話就是一個 SQL 語句被記錄到 binlog 中,占用幾十個字節的空間。但如果用 row 格式的 binlog,就要把這 10 萬條記錄都寫到 binlog 中。這樣做,不僅會占用更大的空間,同時寫 binlog 也要耗費 IO 資源,影響執行速度。
所以,MySQL 就取瞭個折中方案,也就是有瞭 mixed 格式的 binlog。mixed 格式的意思是,MySQL 自己會判斷這條 SQL 語句是否可能引起主備不一致,如果有可能,就用 row 格式,否則就用 statement 格式。 也就是說,mixed 格式可以利用 statment 格式的優點,同時又避免瞭數據不一致的風險。
現在越來越多的場景要求把 MySQL 的 binlog 格式設置成 row。這麼做的理由有很多,舉一個可以直接看出來的好處:恢復數據。
我們就分別從 delete、insert 和 update 這三種 SQL 語句的角度,來看看數據恢復的問題。
- 通過圖 6 你可以看出來,即使我執行的是 delete 語句,row 格式的 binlog 也會把被刪掉的行的整行信息保存起來。所以,如果你在執行完一條 delete 語句以後,發現刪錯數據瞭,可以直接把 binlog 中記錄的 delete 語句轉成 insert,把被錯刪的數據插入回去就可以恢復瞭。
- 如果你是執行錯瞭 insert 語句呢?那就更直接瞭。row 格式下,insert 語句的 binlog 裡會記錄所有的字段信息,這些信息可以用來精確定位剛剛被插入的那一行。這時,你直接把 insert 語句轉成 delete 語句,刪除掉這被誤插入的一行數據就可以瞭。
- 如果執行的是 update 語句的話,binlog 裡面會記錄修改前整行的數據和修改後的整行數據。所以,如果你誤執行瞭 update 語句的話,隻需要把這個 event 前後的兩行信息對調一下,再去數據庫裡面執行,就能恢復這個更新操作瞭。
由 delete、insert 或者 update 語句導致的數據操作錯誤,需要恢復到操作之前狀態的情況,也時有發生。MariaDB 的Flashback工具就是基於上面介紹的原理來回滾數據的。
mysql> insert into t values(10,10, now());
把 binlog 格式設置為 mixed,你覺得 MySQL 會把它記錄為 row 格式還是 statement 格式呢?

圖 7 mixed 格式和 now()
MySQL 用的居然是 statement 格式。接下來,我們再用 mysqlbinlog 工具來看看:

圖 8 TIMESTAMP 命令
原來 binlog 在記錄 event 的時候,多記瞭一條命令:SET TIMESTAMP=1546103491。它用 SET TIMESTAMP 命令約定瞭接下來的 now() 函數的返回時間。通過這條 SET TIMESTAMP 命令,MySQL 就確保瞭主備數據的一致性。
重放 binlog 數據的時候,是這麼做的:用 mysqlbinlog 解析出日志,然後把裡面的 statement 語句直接拷貝出來執行。
你現在知道瞭,這個方法是有風險的。因為有些語句的執行結果是依賴於上下文命令的,直接執行的結果很可能是錯誤的。
所以,用 binlog 來恢復數據的標準做法是,用 mysqlbinlog 工具解析出來,然後把解析結果整個發給 MySQL 執行。類似下面的命令:
mysqlbinlog master.000001 --start-position=2738 --stop-position=2942 | mysql -h127.0.0.1 -P13000 -u$user -p$pwd;
這個命令的意思是,將 master.000001 文件裡面從第 2738 字節到第 2942 字節中間這段內容解析出來,放到 MySQL 去執行。
循環復制問題
binlog 的特性確保瞭在備庫執行相同的 binlog,可以得到與主庫相同的狀態。我們可以認為正常情況下主備的數據是一致的。也就是說,圖 1 中 A、B 兩個節點的內容是一致的。其實,圖 1 中我畫的是 M-S 結構,但實際生產上使用比較多的是雙 M 結構,也就是圖 9 所示的主備切換流程。
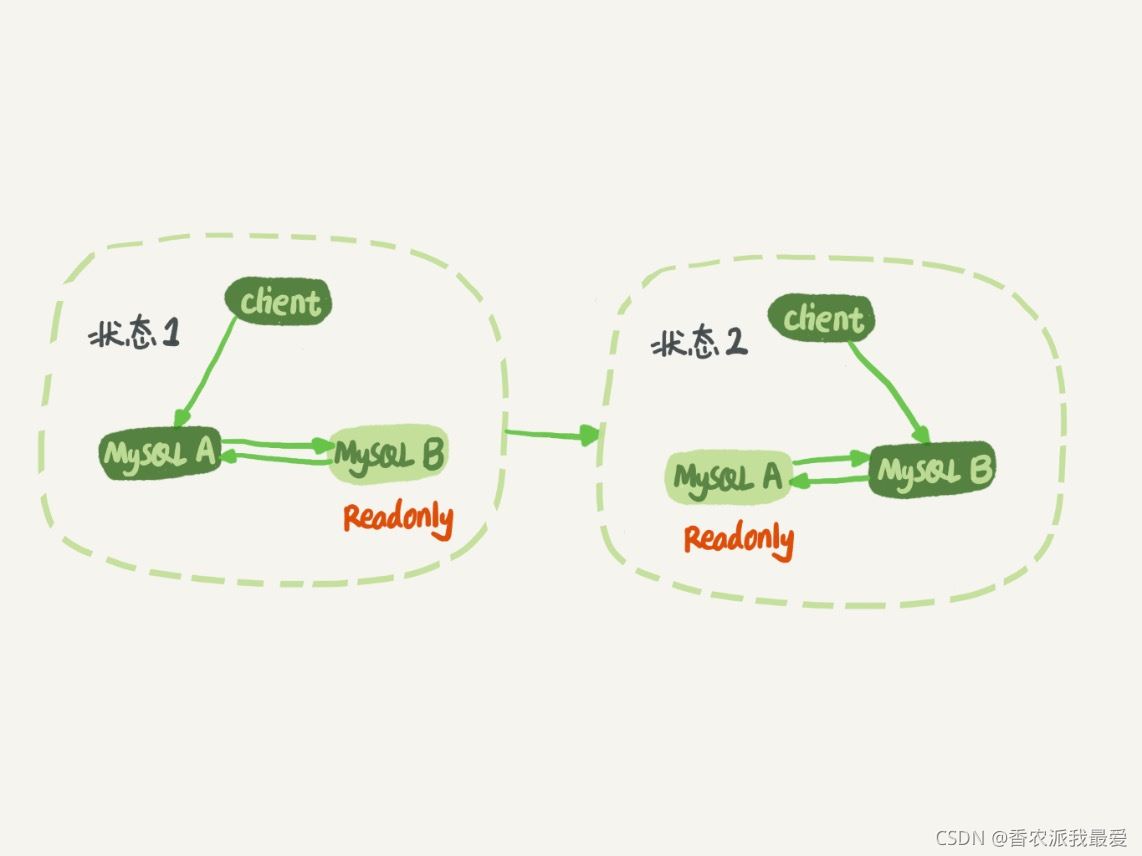
圖 9 MySQL 主備切換流程 — 雙 M 結構
節點 A 和 B 之間總是互為主備關系。這樣在切換的時候就不用再修改主備關系。
但是,雙 M 結構還有一個問題需要解決。
業務邏輯在節點 A 上更新瞭一條語句,然後再把生成的 binlog 發給節點 B,節點 B 執行完這條更新語句後也會生成 binlog。(我建議你把參數 log_slave_updates 設置為 on,表示備庫執行 relay log 後生成 binlog)。
那麼,如果節點 A 同時是節點 B 的備庫,相當於又把節點 B 新生成的 binlog 拿過來執行瞭一次,然後節點 A 和 B 間,會不斷地循環執行這個更新語句,也就是循環復制瞭。這個要怎麼解決呢?
從上面的圖 6 中可以看到,MySQL 在 binlog 中記錄瞭這個命令第一次執行時所在實例的 server id。因此,我們可以用下面的邏輯,來解決兩個節點間的循環復制的問題:
- 規定兩個庫的 server id 必須不同,如果相同,則它們之間不能設定為主備關系;
- 一個備庫接到 binlog 並在重放的過程中,生成與原 binlog 的 server id 相同的新的 binlog;
- 每個庫在收到從自己的主庫發過來的日志後,先判斷 server id,如果跟自己的相同,表示這個日志是自己生成的,就直接丟棄這個日志。
按照這個邏輯,如果我們設置瞭雙 M 結構,日志的執行流就會變成這樣:
- 從節點 A 更新的事務,binlog 裡面記的都是 A 的 server id;
- 傳到節點 B 執行一次以後,節點 B 生成的 binlog 的 server id 也是 A 的 server id;
- 再傳回給節點 A,A 判斷到這個 server id 與自己的相同,就不會再處理這個日志。所以,死循環在這裡就斷掉瞭。
總結:
到此這篇關於MySQL是怎麼保證主備一致的的文章就介紹到這瞭,更多相關MySQL是怎麼保證主備一致的內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!