MySQL事務的隔離性是如何實現的
並發場景
最近做瞭一些分佈式事務的項目,對事務的隔離性有瞭更深的認識,後續寫文章聊分佈式事務。今天就復盤一下單機事務的隔離性是如何實現的?
隔離的本質就是控制並發,如果SQL語句就是串行執行的。那麼數據庫的四大特性中就不會有隔離性這個概念瞭,也就不會有臟讀,不可重復讀,幻讀等各種問題瞭
對數據庫的各種並發操作,隻有如下四種,寫寫,讀讀,讀寫和寫讀
寫-寫
事務A更新一條記錄的時候,事務B能同時更新同一條記錄嗎?
答案肯定是不能的,不然就會造成臟寫問題,那如何避免臟寫呢?答案就是加鎖
讀-讀
MySQL讀操作默認情況下不會加鎖,所以可以並行的讀
讀-寫 和 寫-讀
基於各種場景對並發操作容忍程度不同,MySQL就搞瞭個隔離性的概念。你自己根據業務場景選擇隔離級別。
√ 為會發生,×為不會發生
| 隔離級別 | 臟讀 | 不可重復讀 | 幻讀 |
|---|---|---|---|
| read uncommitted(未提交讀) | √ | √ | √ |
| read committed(提交讀) | × | √ | √ |
| repeatable read(可重復讀) | × | × | √ |
| serializable (可串行化) | × | × | × |
所以你看,MySQL是通過鎖和隔離級別對MySQL進行並發控制的
MySQL中的鎖
行級鎖
InnoDB存儲引擎中有如下兩種類型的行級鎖
- 共享鎖(Shared Lock,簡稱S鎖),在事務需要讀取一條記錄時,需要先獲取改記錄的S鎖
- 排他鎖(Exclusive Lock,簡稱X鎖),在事務要改動一條記錄時,需要先獲取該記錄的X鎖
如果事務T1獲取瞭一條記錄的S鎖之後,事務T2也要訪問這條記錄。如果事務T2想再獲取這個記錄的S鎖,可以成功,這種情況稱為鎖兼容,如果事務T2想再獲取這個記錄的X鎖,那麼此操作會被阻塞,直到事務T1提交之後將S鎖釋放掉
如果事務T1獲取瞭一條記錄的X鎖之後,那麼不管事務T2接著想獲取該記錄的S鎖還是X鎖都會被阻塞,直到事務1提交,這種情況稱為鎖不兼容。
多個事務可以同時讀取記錄,即共享鎖之間不互斥,但共享鎖會阻塞排他鎖。排他鎖之間互斥
S鎖和X鎖之間的兼容關系如下
| 兼容性 | X鎖 | S鎖 |
|---|---|---|
| X鎖 | 互斥 | 互斥 |
| S鎖 | 互斥 | 兼容 |
update,delete,insert 都會自動給涉及到的數據加上排他鎖,select 語句默認不會加任何鎖
那什麼情況下會對讀操作加鎖呢?
- select … lock in share mode,對讀取的記錄加S鎖
- select … for update ,對讀取的記錄加X鎖
- 在事務中讀取記錄,對讀取的記錄加S鎖
- 事務隔離級別在 SERIALIZABLE 下,對讀取的記錄加S鎖
InnoDB中有如下三種鎖
- Record Lock:對單個記錄加鎖
- Gap Lock:間隙鎖,鎖住記錄前面的間隙,不允許插入記錄
- Next-key Lock:同時鎖住數據和數據前面的間隙,即數據和數據前面的間隙都不允許插入記錄
寫個Demo演示一下
CREATE TABLE `girl` ( `id` int(11) NOT NULL, `name` varchar(255), `age` int(11), PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into girl values (1, '西施', 20), (5, '王昭君', 23), (8, '貂蟬', 25), (10, '楊玉環', 26), (12, '陳圓圓', 20);
Record Lock
對單個記錄加鎖
如把id值為8的數據加一個Record Lock,示意圖如下
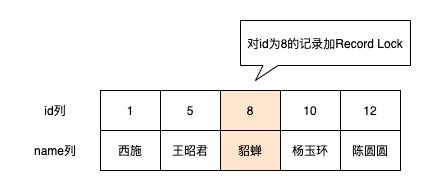
Record Lock也是有S鎖和X鎖之分的,兼容性和之前描述的一樣。
SQL執行加什麼樣的鎖受很多條件的制約,比如事務的隔離級別,執行時使用的索引(如,聚集索引,非聚集索引等),因此就不詳細分析瞭,舉幾個簡單的例子。
-- READ UNCOMMITTED/READ COMMITTED/REPEATABLE READ 利用主鍵進行等值查詢 -- 對id=8的記錄加S型Record Lock select * from girl where id = 8 lock in share mode; -- READ UNCOMMITTED/READ COMMITTED/REPEATABLE READ 利用主鍵進行等值查詢 -- 對id=8的記錄加X型Record Lock select * from girl where id = 8 for update;
Gap Lock
鎖住記錄前面的間隙,不允許插入記錄
MySQL在可重復讀隔離級別下可以通過MVCC和加鎖來解決幻讀問題
當前讀:加鎖
快照讀:MVCC
但是該如何加鎖呢?因為第一次執行讀取操作的時候,這些幻影記錄並不存在,我們沒有辦法加Record Lock,此時可以通過加Gap Lock解決,即對間隙加鎖。
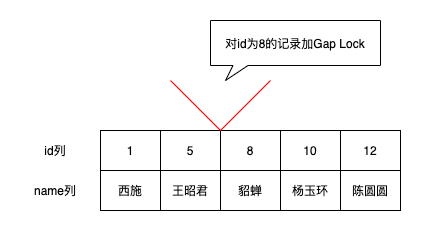
如一個事務對id=8的記錄加間隙鎖,則意味著不允許別的事務在id=8的記錄前面的間隙插入新記錄,即id值在(5, 8)這個區間內的記錄是不允許立即插入的。直到加間隙鎖的事務提交後,id值在(5, 8)這個區間中的記錄才可以被提交
我們來看如下一個SQL的加鎖過程
-- REPEATABLE READ 利用主鍵進行等值查詢 -- 但是主鍵值並不存在 -- 對id=8的聚集索引記錄加Gap Lock SELECT * FROM girl WHERE id = 7 LOCK IN SHARE MODE;
由於id=7的記錄不存在,為瞭禁止幻讀現象(避免在同一事務下執行相同的語句得到的結果集中有id=7的記錄),所以在當前事務提交前我們要預防別的事務插入id=7的記錄,此時在id=8的記錄上加一個Gap Lock即可,即不允許別的事務插入id值在(5, 8)這個區間的新記錄
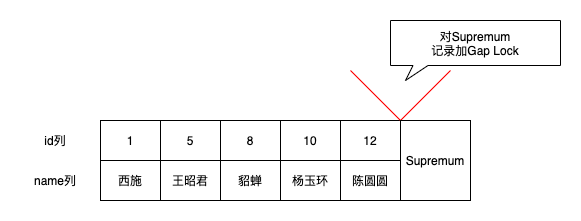
給大傢提一個問題,Gap Lock隻能鎖定記錄前面的間隙,那麼最後一條記錄後面的間隙該怎麼鎖定?
其實mysql數據是存在頁中的,每個頁有2個偽記錄
- Infimum記錄,表示該頁面中最小的記錄
- upremum記錄,表示該頁面中最大的記錄
為瞭防止其它事務插入id值在(12, +∞)這個區間的記錄,我們可以給id=12記錄所在頁面的Supremum記錄加上一個gap鎖,此時就可以阻止其他事務插入id值在(12, +∞)這個區間的新記錄
Next-key Lock
同時鎖住數據和數據前面的間隙,即數據和數據前面的間隙都不允許插入記錄
所以你可以這樣理解Next-key Lock=Record Lock+Gap Lock
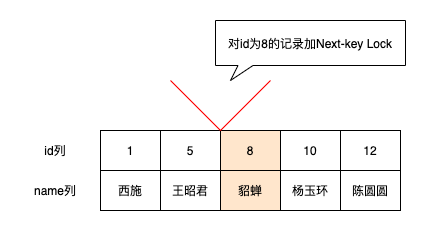
-- REPEATABLE READ 利用主鍵進行范圍查詢 -- 對id=8的聚集索引記錄加S型Record Lock -- 對id>8的所有聚集索引記錄加S型Next-key Lock(包括Supremum偽記錄) SELECT * FROM girl WHERE id >= 8 LOCK IN SHARE MODE;
因為要解決幻讀的問題,所以需要禁別的事務插入id>=8的記錄,所以
- 對id=8的聚集索引記錄加S型Record Lock
- 對id>8的所有聚集索引記錄加S型Next-key Lock(包括Supremum偽記錄)
表級鎖
表鎖也有S鎖和X鎖之分
在對某個表執行select,insert,update,delete語句時,innodb存儲引擎是不會為這個表添加表級別的S鎖或者X鎖。
在對表執行一些諸如ALTER TABLE,DROP TABLE這類的DDL語句時,會對這個表加X鎖,因此其他事務對這個表執行諸如SELECT INSERT UPDATE DELETE的語句會發生阻塞
在系統變量autocommit=0,innodb_table_locks = 1時,手動獲取InnoDB存儲引擎提供的表t的S鎖或者X鎖,可以這麼寫
對表t加表級別的S鎖
lock tables t read
對表t加表級別的X鎖
lock tables t write
如果一個事務給表加瞭S鎖,那麼
- 別的事務可以繼續獲得該表的S鎖
- 別的事務可以繼續獲得表中某些記錄的S鎖
- 別的事務不可以繼續獲得該表的X鎖
- 別的事務不可以繼續獲得表中某些記錄的X鎖
如果一個事務給表加瞭X鎖,那麼
- 別的事務不可以繼續獲得該表的S鎖
- 別的事務不可以繼續獲得表中某些記錄的S鎖
- 別的事務不可以繼續獲得該表的X鎖
- 別的事務不可以繼續獲得表中某些記錄的X鎖
所以修改線上的表時一定要小心,因為會使大量事務阻塞,目前有很多成熟的修改線上表的方法,不再贅述
隔離級別
讀未提交:每次讀取最新的記錄,沒有做特殊處理
串行化:事務串行執行,不會產生並發
所以我們重點關註讀已提交和可重復讀的隔離實現!
這兩種隔離級別是通過MVCC(多版本並發控制)來實現的,本質就是MySQL通過undolog存儲瞭多個版本的歷史數據,根據規則讀取某一歷史版本的數據,這樣就可以在無鎖的情況下實現讀寫並行,提高數據庫性能
那麼undolog是如何存儲修改前的記錄?
對於使用InnoDB存儲引擎的表來說,聚集索引記錄中都包含下面2個必要的隱藏列
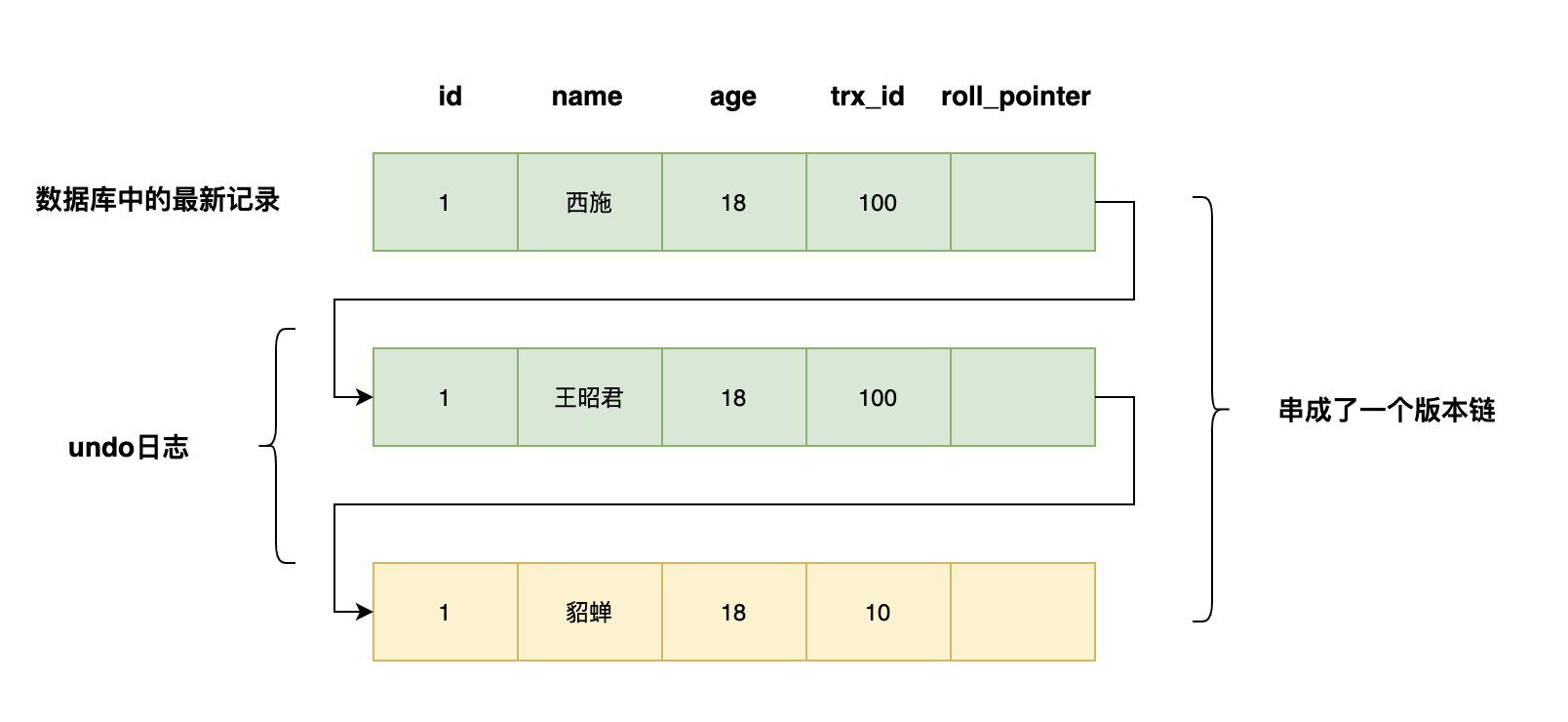
trx_id:一個事務每次對某條聚集索引記錄進行改動時,都會把該事務的事務id賦值給trx_id隱藏列
roll_pointer:每次對某條聚集索引記錄進行改動時,都會把舊的版本寫入undo日志中。這個隱藏列就相當於一個指針,通過他找到該記錄修改前的信息
如果一個記錄的name從貂蟬被依次改為王昭君,西施,會有如下的記錄,多個記錄構成瞭一個版本鏈
為瞭判斷版本鏈中哪個版本對當前事務是可見的,MySQL設計出瞭ReadView的概念。4個重要的內容如下
- m_ids:在生成ReadView時,當前系統中活躍的事務id列表
- min_trx_id:在生成ReadView時,當前系統中活躍的最小的事務id,也就是m_ids中的最小值
- max_trx_id:在生成ReadView時,系統應該分配給下一個事務的事務id值
- creator_trx_id:生成該ReadView的事務的事務id
當對表中的記錄進行改動時,執行insert,delete,update這些語句時,才會為事務分配唯一的事務id,否則一個事務的事務id值默認為0。
max_trx_id並不是m_ids中的最大值,事務id是遞增分配的。比如現在有事務id為1,2,3這三個事務,之後事務id為3的事務提交瞭,當有一個新的事務生成ReadView時,m_ids的值就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4
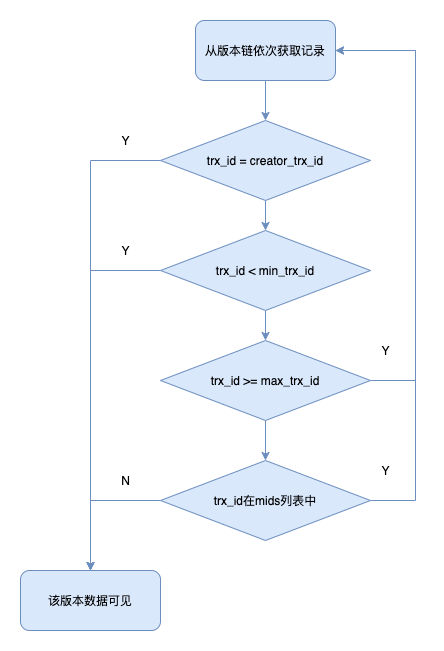
執行過程如下:
- 如果被訪問版本的trx_id=creator_id,意味著當前事務在訪問它自己修改過的記錄,所以該版本可以被當前事務訪問
- 如果被訪問版本的trx_id<min_trx_id,表明生成該版本的事務在當前事務生成ReadView前已經提交,所以該版本可以被當前事務訪問
- 被訪問版本的trx_id>=max_trx_id,表明生成該版本的事務在當前事務生成ReadView後才開啟,該版本不可以被當前事務訪問
- 被訪問版本的trx_id是否在m_ids列表中
- 4.1 是,創建ReadView時,該版本還是活躍的,該版本不可以被訪問。順著版本鏈找下一個版本的數據,繼續執行上面的步驟判斷可見性,如果最後一個版本還不可見,意味著記錄對當前事務完全不可見
- 4.2 否,創建ReadView時,生成該版本的事務已經被提交,該版本可以被訪問
好瞭,我們知道瞭版本可見性的獲取規則,那麼是怎麼實現讀已提交和可重復讀的呢?
其實很簡單,就是生成ReadView的時機不同
舉個例子,先建立如下表
CREATE TABLE `girl` ( `id` int(11) NOT NULL, `name` varchar(255), `age` int(11), PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Read Committed
Read Committed(讀已提交),每次讀取數據前都生成一個ReadView
下面是3個事務執行的過程,一行代表一個時間點
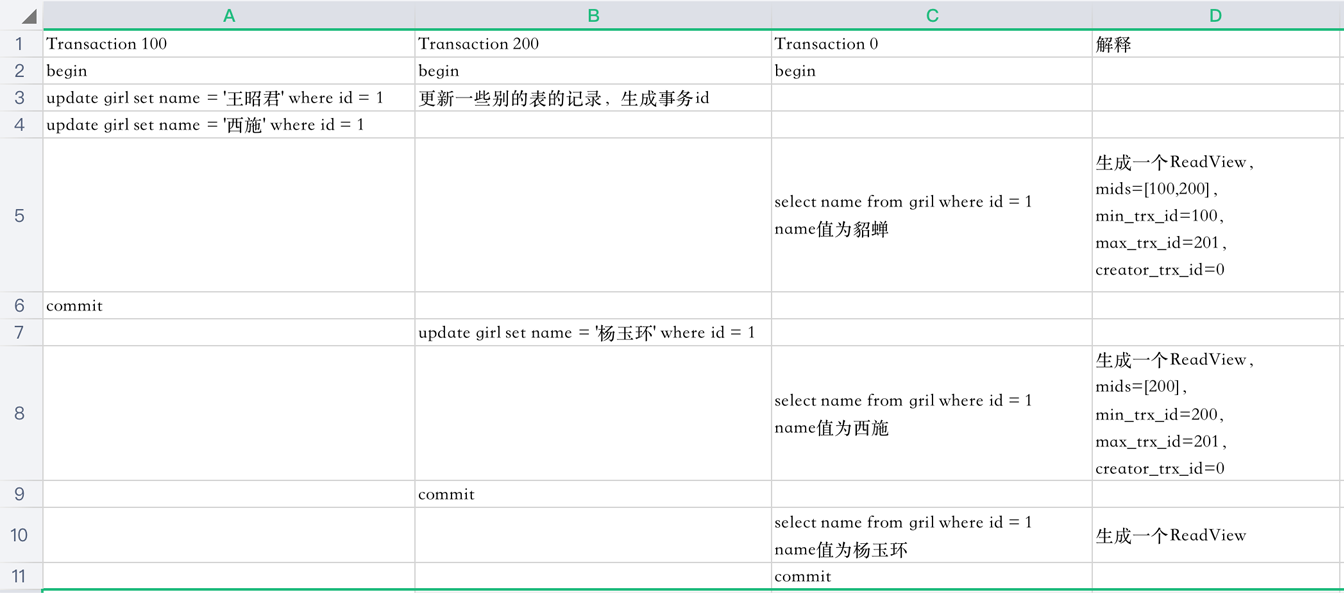
先分析一下5這個時間點select的執行過程
- 系統中有兩個事務id分別為100,200的事務正在執行
- 執行select語句時生成一個ReadView,mids=[100,200],min_trx_id=100,max_trx_id=201,creator_trx_id=0(select這個事務沒有執行更改操作,事務id默認為0)
- 最新版本的name列為西施,該版本trx_id值為100,在mids列表中,不符合可見性要求,根據roll_pointer跳到下一個版本
- 下一個版本的name列王昭君,該版本的trx_id值為100,也在mids列表內,因此也不符合要求,繼續跳到下一個版本
- 下一個版本的name列為貂蟬,該版本的trx_id值為10,小於min_trx_id,因此最後返回的name值為貂蟬
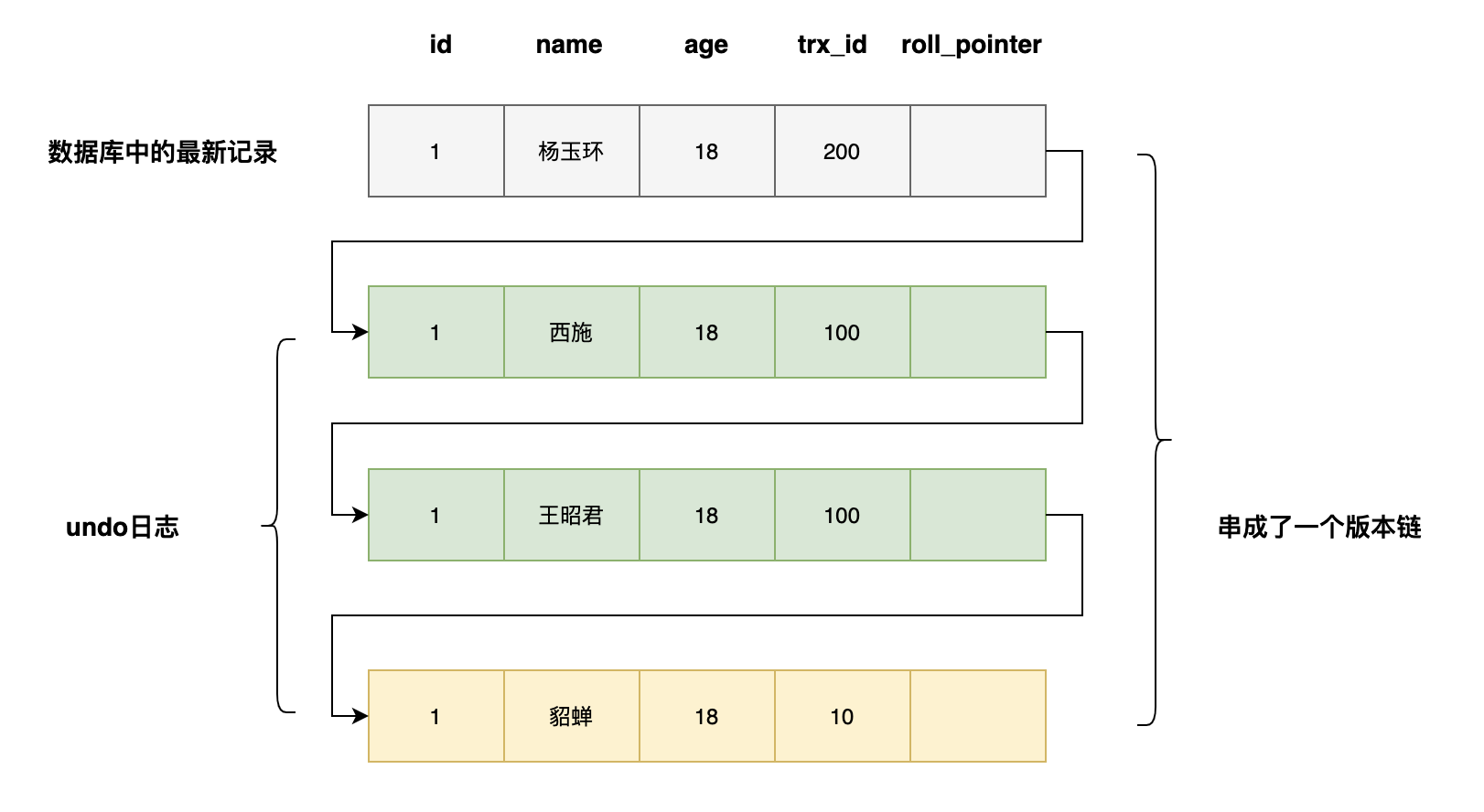
再分析一下8這個時間點select的執行過程
- 系統中有一個事務id為200的事務正在執行(事務id為100的事務已經提交)
- 執行select語句時生成一個ReadView,mids=[200],min_trx_id=200,max_trx_id=201,creator_trx_id=0
- 最新版本的name列為楊玉環,該版本trx_id值為200,在mids列表中,不符合可見性要求,根據roll_pointer跳到下一個版本
- 下一個版本的name列為西施,該版本的trx_id值為100,小於min_trx_id,因此最後返回的name值為西施
當事務id為200的事務提交時,查詢得到的name列為楊玉環。
Repeatable Read
Repeatable Read(可重復讀),在第一次讀取數據時生成一個ReadView

可重復讀因為隻在第一次讀取數據的時候生成ReadView,所以每次讀到的是相同的版本,即name值一直為貂蟬,具體的過程上面已經演示瞭兩遍瞭,我這裡就不重復演示瞭,相信你一定會自己分析瞭。
參考博客
[1]https://souche.yuque.com/bggh1p/8961260/gyzlaf
[2]https://zhuanlan.zhihu.com/p/35477890
到此這篇關於MySQL事務的隔離性是如何實現的的文章就介紹到這瞭,更多相關MySQL事務的隔離性內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- MySQL多版本並發控制MVCC詳解
- MySQL多版本並發控制MVCC底層原理解析
- 詳解MySQL中事務隔離級別的實現原理
- MySQL MVVC多版本並發控制的實現詳解
- MySQL臟讀幻讀不可重復讀及事務的隔離級別和MVCC、LBCC實現