利用Numba與Cython結合提升python運行效率詳解
Numba
Numba是一個即時(JIT)編譯器,它將Python代碼轉換為用於CPU和GPU的本地機器指令。代碼可以在導入時、運行時或提前編譯。
通過使用jit裝飾器,使用Numba非常容易:
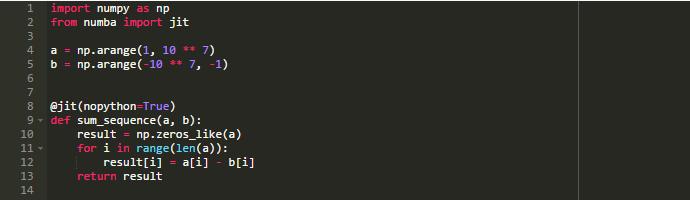

正如你所知道的,在Python中,所有代碼塊都被編譯成字節碼:
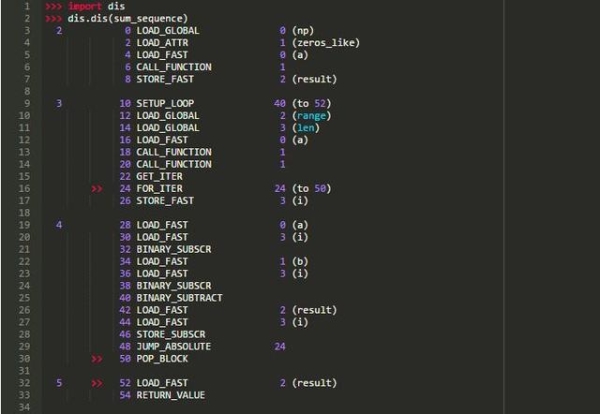
代碼優化
為瞭優化Python代碼,Numba從提供的函數中提取一個字節碼,並在其上運行一組分析器。Python字節碼包含一系列小而簡單的指令,因此不必從Python實現中使用源代碼就可以從字節碼中重構函數的邏輯。轉換的過程涉及多個階段,但Numba將Python字節碼轉換為LLVM中間表示 (IR)。
請註意,LLVM IR是一種低級編程語言,它類似於匯編語法,與Python無關。
Numba 模式
Numba中有兩種模式:nopython 和 object。前者不使用Python運行時並且在沒有Python依賴項的情況下生成本機代碼。 本機代碼是靜態類型的,運行非常快。而對象模式使用Python對象和Python C API,這通常不會帶來顯著的速度改進。在這兩種情況下,Python代碼都是使用LLVM編譯的。
什麼是LLVM?
LLVM是一種編譯器,它采用代碼的特殊中間表示(IR),並將其編譯成本機代碼。編譯過程涉及許多額外的傳遞,其中編譯器優化IR。LLVM工具鏈很好地優化瞭IR,不僅為Numba編譯代碼,而且優化Numba。整個系統大致如下:
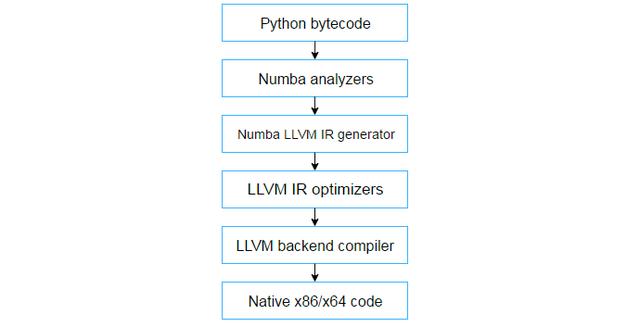
Python numba 體系結構
Numba的優勢:
- 易用性
- 自動並行化
- 支持numpy操作和對象
- GPU支持
Numba的劣勢:
多層的抽象使得調試和優化變得非常困難
在nopython模式下無法與Python及其模塊進行交互
有限的類支持
Cython
取代分析字節碼和生成IR,Cython使用Python語法的超集,它後來轉換成C代碼。在使用Cython時,基本上是用高級Python語法編寫C代碼。
在Cython中,通常不必擔心Python包裝器和低級API調用,因為所有交互都會自動擴展到合適的C代碼。
與Numba不同,所有的Cython代碼應該在專門文件中與常規Python代碼分開。Cython將這些文件解析並轉換成C代碼,然後使用提供的C編譯器 (例如, gcc)編譯它。
Python代碼已經是有效的Cython代碼。

但是,類型版本工作得更快。
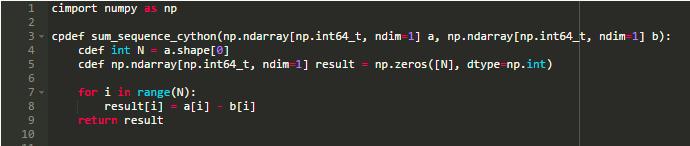

編寫快速Cython代碼需要理解C和Python內部結構。如果你熟悉C,你的Cython代碼可以運行得和C代碼一樣快。
Cython的優勢:
- 通過Python API的使用控制
- 與C/C++庫和C/C++代碼的簡單接口
- 並行執行支持
- 支持Python類,在C中提供面向對象的特性
Cython的劣勢:
- 學習曲線
- 需要C和Python內部專業技術
- 模塊的組織不方便
Numba 對 Cython
就個人而言,我更喜歡小項目和ETL實驗用Numba。你可以將其插入現有項目中。如果我需要啟動一個大項目或為C庫編寫包裝器,我將使用Cython,因為它提供更多的控制和更容易調試。
此外,Cython是許多庫的標準,如pandas、scikit-learn、scipy、Spacy、gensim和lxml。
以上就是利用Numba與Cython結合提升python運行效率詳解的詳細內容,更多關於提升python運行效率的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- 這十大Python庫你真應該知道
- 隻需要這一行代碼就能讓python計算速度提高十倍
- numba提升python運行速度的實例方法
- Python 機器學習工具包SKlearn的安裝與使用
- python數字圖像處理環境安裝與配置過程示例