MySQL的索引系統采用B+樹的原因解析
1.什麼是索引?
索引是為瞭加速對表中數據行的檢索而創建的一種分散的存儲結構。(就好像我們小時候用的字典,有瞭字典查到對應的字就會變快)
2.為什麼需要索引?
首先我們需要瞭解一些概念和知識
- mysql數據存儲在什麼地方?—-磁盤
- 查詢數據比較慢的,一般情況下是卡在哪瞭? —-IO
- (所以我們要提高IO的效率,那麼如何提高呢?—- 次數和量兩個層面,例如:搬磚,搬一次和搬十次耗費的力氣是不一樣的,一次搬一塊和一次搬十塊耗費的力氣(占用IO資源)也是不一樣的。所以我們盡可能的在滿足自身需求的前提下,減少和IO的交互)
- 去磁盤讀取數據的時候,是用多少讀取多少嘛? —-磁盤預讀
- 磁盤預讀:內存跟磁盤在發生數據交互的時候,一般情況下有一個最小的邏輯單元,稱為頁,datapage,頁一般由操作系統決定是多大,一般是4k和8k,而我們在進行數據交互的時候,可以取頁的的整數倍來進行讀取,innodb存儲引擎每次讀取數據為16k
- 局部性原理:數據和程序都有聚集成群的傾向,同時之前被訪問過的數據和可能再次被查詢,涉及空間局部性、時間局部性
通過以上幾個概念我們大概知道索引是用來幹嘛的瞭—-預先設計好索引系統,等我們查詢數據的時候,減少和IO的交互來提高我們的查詢效率。
3.如何設計索引系統?
我們還是先明白幾個概念
- 索引存儲在哪?—- 磁盤,查詢數據的時候會優先將索引加載到內存中
- 索引在存儲的時候需要什麼信息?需要存什麼字段值?
—— key:實際數據行中儲存的值
—— 文件地址(指針、我們需要找到存儲數據文件在哪就得靠文件地址)
—— offset:偏移量(如果我們要取文件中的某一條數據時,就需要用到偏移量)
- 上面說的這種格式的數據要使用什麼樣的數據結構來儲存?
—— 上面可知我們我們的數據格式是 K-V類型的
知道K-V格式數據那我們就知道使用什麼數據結構來儲存瞭,有哈希表、樹(二叉樹、二分查找樹、二分平衡樹、紅黑樹、B樹、B+樹)
綜上所述,我們可以上面的數據結構來設計我們的索引系統
4.MYSQL索引系統是什麼呢?
為什麼不按照上面說的格式儲存呢?
眾所周知,mysql的索引系統使用的是B+樹,為什麼是B+樹呢?接下來我們逐個分析其他的存儲結構為什麼不行。在此之前,我們還是需要瞭解兩個前置知識—-OLAP和OLTP
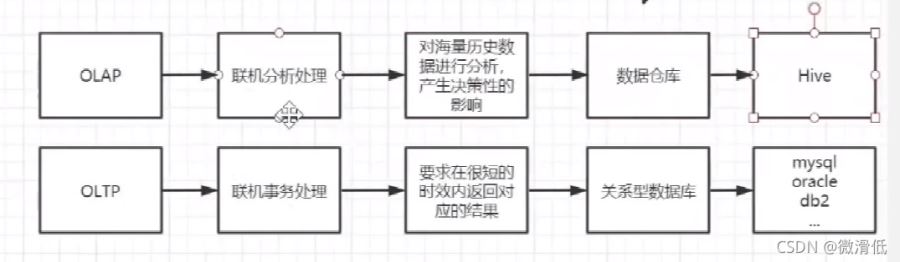
當我們存儲的數據量越多時,對應建立的索引也會越大,當我們從磁盤讀取到內存時就會產生IO問題,那我們又對索引建立索引嘛?不是的,所以mysql采取的B+樹
5.哈希表
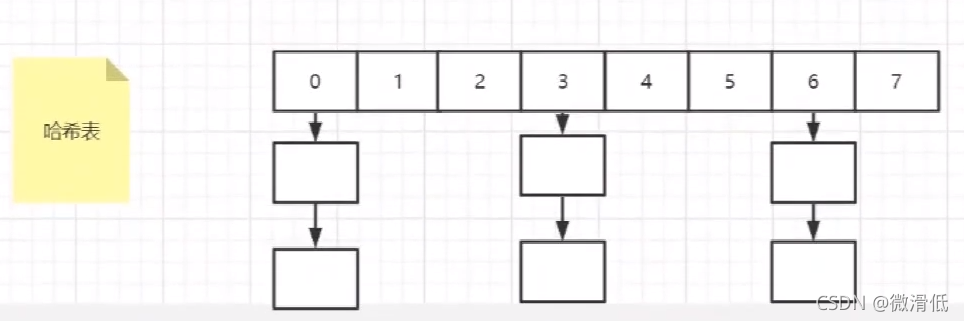
上面是哈希表的存儲結構,我們來探討這類的存儲結構的優缺點
缺點:
- 哈希沖突會造成數據散列不均勻,會產生大量的線性查詢,比較浪費時間
- 不支持范圍查詢,當進行范圍查詢的時候,必須要挨個遍歷
- 對於內存空間的要求比較高(要把全部數據加到到內存中)
優點:
如果是等值查詢,那麼會非常快
那麼在mysql中有沒有hash索引呢?
- memory存儲引擎使用的是hash索引
- innodb支持自適應hash
6.樹
6.1 二叉樹

二叉樹本身是無序的,當我們在進行數據查找時要挨個去跟每個節點進行數據對比,看是否符合我們的數據要求,效率低下
6.2 二分查找樹(Binary Search Tree ,BST)
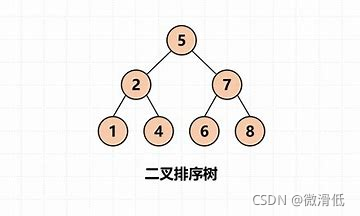
二分查找樹的特點:插入數據的時候必須有序,左子樹必須小於跟節點,右子樹必須保證大於根節點。所以使用二分查找樹對比二叉樹來顯然提高瞭查詢效率。
但是如果數據插入是遞增或者遞減的順序的話,二分查找樹就會退化成鏈表,查找效率又降低瞭
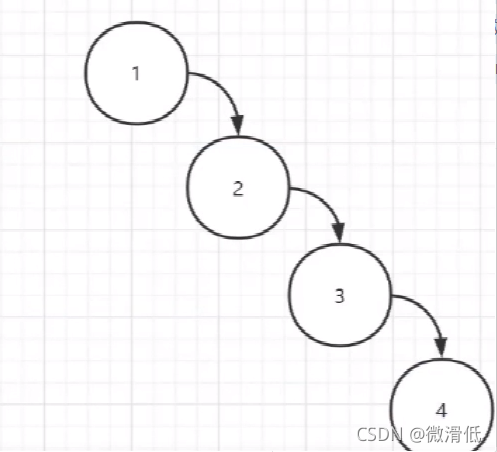
6.3 平衡二叉樹(Balanced Binary Tree, AVL樹)

根據二叉查找樹的所暴露出的問題,我們通過使用AVL樹經過左旋或者右旋讓樹平衡。但是為瞭保證平衡,在插入數據的時候必須要旋轉,通過插入性能的損失來彌補查詢性能的提升。讀多寫少的情況還好,但是如果我讀寫請求一樣多,那就不合適瞭。
6.4 紅黑樹
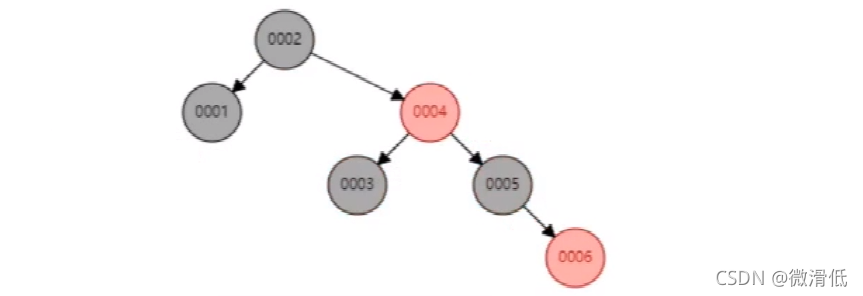
紅黑樹也是經過左旋和右旋讓樹平衡起來,還有變色的行為,最長子樹隻要不超過最短子樹的兩倍即可…所以就能讓查詢性能和插入性能近似取得一個平衡,但是隨著數據的插入,發現樹的深度會變深,深的深度越深,意味著IO次數越多,影響數據讀取的效率。
6.5 B樹
針對紅黑樹暴露的問題,那麼我們應該如何提高讀取的效率呢?我們能不能從有序的二叉樹,變成有序的多叉樹呢,這樣我們就可以儲存更多的數據
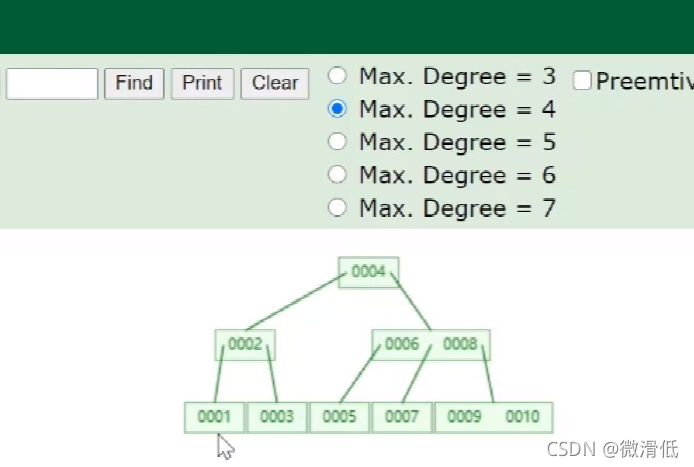
Degree為4表示的是一個節點存儲三個數據值,超過就要變換。那麼實際的數據是怎麼存儲的呢?我們需要Key和完整的數據行
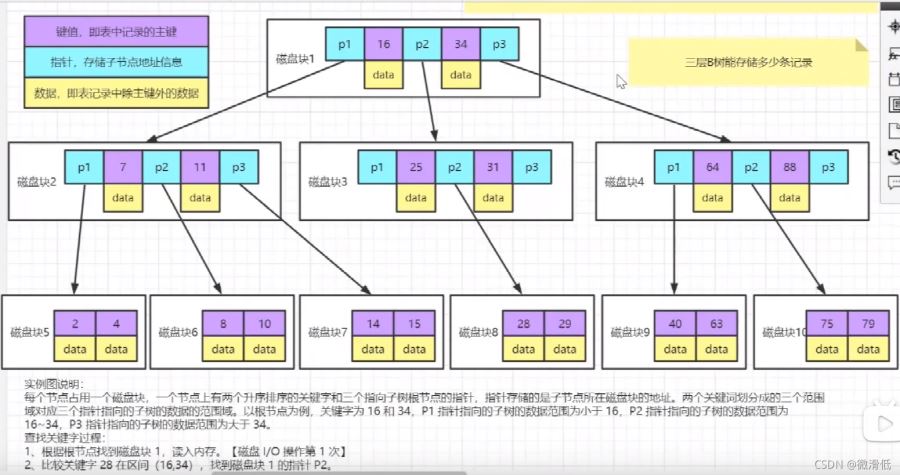
上圖是B樹實際存儲數據的圖,每個節點有三個元素key、指針、數據。
查找實例,如果我想找28這個數據,先從磁盤塊1開始發現讀取不到,經對比范圍在p2指針指向的磁盤塊3,還是沒找到,再根據磁盤塊3的p2指針指向磁盤塊8找到28。我們來分析一下,每個磁盤塊大小為16kb,我們查找瞭三個磁盤塊隻需讀取48kb,那麼三層B樹能存儲多少條記錄呢?
我們理想化一下,假設key和指針不占用大小,一條數據占用1k的大小,那麼磁盤1數據可以存儲16條,磁盤3也是16條,磁盤8也是16條,那麼我們隻能存儲161616=4096條記錄,這明顯有點少瞭,而且我們是理想化的,實際key和指針也是占用大小的。
於是乎我們不禁思考,為什麼存儲的數據量那麼少?
我們發現每層存儲的大小都被data給占用瞭,那麼我們能不能隻存儲key跟指針呢?為此就引出瞭B+樹
6.6 B+樹

B樹到B+樹的演變:非葉子節點不存儲數據,葉子節點才存儲數據
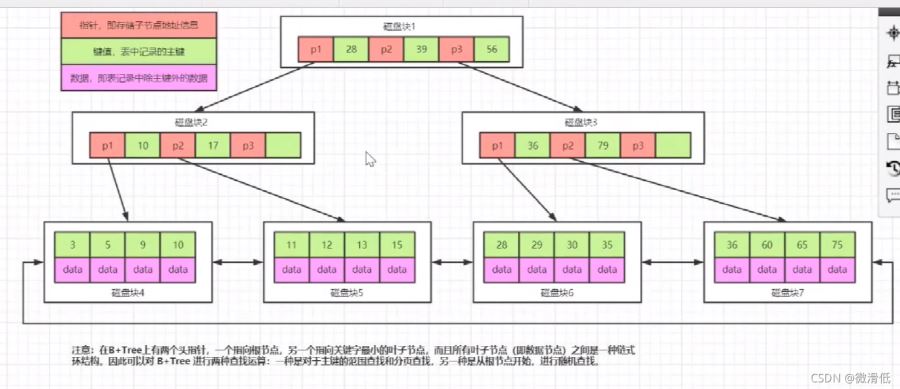
上圖我們可以假設p1和28為一組占用10字節大小,那麼第一層可以存儲16000/10=1600個這樣的大小,第二層也是1600,第三層data占用1kb,那就是16條,所以總的存儲1600160016=40960000(4096萬)條記錄
mysql索引結構一般3~4層,但是還要註意一個問題。假設我們就是3層存儲結構,如何存儲更多的數據?
剛剛我們假設的是p1和28為10字節大小,那如果它們是1字節呢,那麼存儲總量是160001600010=4096000000。所以就引申出面試一直被提到的建立索引用int還是var好?
答:保證key的長度越小也好,varchar小於4字節用varcahr,大於4字節用int
根據B+樹的特點,存儲量大,查詢快,所以mysql使用的就是B+樹
總結
至此mysql索引系統為什麼使用的是B+樹就講述完瞭,如果有什麼講錯的地方希望能提醒我改正過來。
到此這篇關於MySQL的索引系統采用B+樹的原因解析的文章就介紹到這瞭,更多相關MySQL索引B+樹內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!