為什麼RedisCluster設計成16384個槽
親愛的同學們,你是否使用過Redis集群呢?那Redis集群的原理又是什麼呢?記住下面兩句話:
- Redis Sentinal著眼於高可用,在master宕機時會自動將slave提升為master,繼續提供服務。
- Redis Cluster著眼於擴展性,在單個redis內存不足時,使用Cluster進行分片存儲。
一、數據分片策略
佈式數據存儲方案中最為重要的一點就是數據分片,也就是所謂的 Sharding。為瞭使得集群能夠水平擴展,首要解決的問題就是如何將整個數據集按照一定的規則分配到多個節點上,常用的數據分片的方法有:范圍分片,哈希分片,一致性哈希算法和虛擬哈希槽等。
范圍分片假設數據集是有序,將順序相臨近的數據放在一起,可以很好的支持遍歷操作。范圍分片的缺點是面對順序寫時,會存在熱點。比如日志類型的寫入,一般日志的順序都是和時間相關的,時間是單調遞增的,因此寫入的熱點永遠在最後一個分片。對於關系型的數據庫,因為經常性的需要表掃描或者索引掃描,基本上都會使用范圍的分片策略。
我們為瞭將不同的 key 分散放置到不同的 redis 節點,通常的做法是獲取 key 的哈希值,然後根據節點數來求模,但這種做法有其明顯的弊端,當我們需要增加或減少一個節點時,會造成大量的 key 無法命中,這種比例是相當高的,所以就有人提出瞭一致性哈希的概念。
一致性哈希有四個重要特征:
- 均衡性:也有人把它定義為平衡性,是指哈希的結果能夠盡可能分佈到所有的節點中去,這樣可以有效的利用每個節點上的資源。
- 單調性:當節點數量變化時哈希的結果應盡可能的保護已分配的內容不會被重新分派到新的節點。
- 分散性和負載:這兩個其實是差不多的意思,就是要求一致性哈希算法對 key 哈希應盡可能的避免重復。
二、Redis的分片機制
但是:Redis 集群沒有使用一致性hash, 而是引入瞭哈希槽的概念。
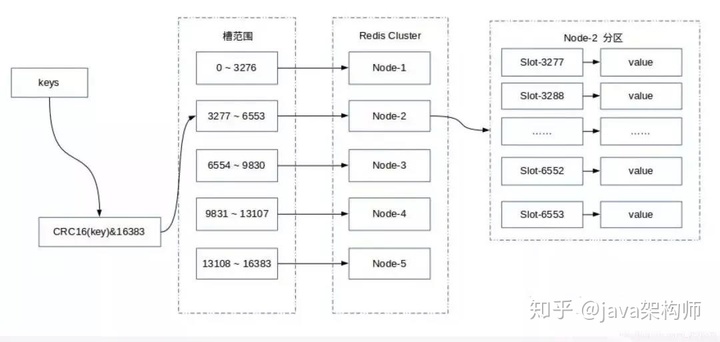
Redis Cluster 采用虛擬哈希槽分區,所有的鍵根據哈希函數映射到 0 ~ 16383 整數槽內,每個key通過CRC16校驗後對16384取模來決定放置哪個槽(Slot),每一個節點負責維護一部分槽以及槽所映射的鍵值數據。
計算公式:slot = CRC16(key) & 16383。
這種結構很容易添加或者刪除節點,並且無論是添加刪除或者修改某一個節點,都不會造成集群不可用的狀態。使用哈希槽的好處就在於可以方便的添加或移除節點。
- 當需要增加節點時,隻需要把其他節點的某些哈希槽挪到新節點就可以瞭;
- 當需要移除節點時,隻需要把移除節點上的哈希槽挪到其他節點就行瞭。
三、Redis 虛擬槽分區的特點
- 解耦數據和節點之間的關系,簡化瞭節點擴容和收縮難度。
- 節點自身維護槽的映射關系,不需要客戶端或者代理服務維護槽分區元數據
- 支持節點、槽和鍵之間的映射查詢,用於數據路由,在線集群伸縮等場景。
四、 Redis 集群伸縮的原理
Redis 集群提供瞭靈活的節點擴容和收縮方案。在不影響集群對外服務的情況下,可以為集群添加節點進行擴容也可以下線部分節點進行縮容。可以說,槽是 Redis 集群管理數據的基本單位,集群伸縮就是槽和數據在節點之間的移動。
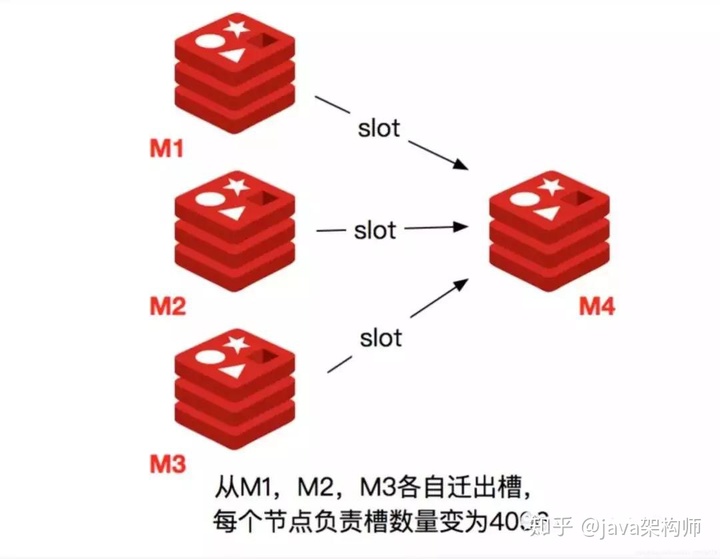
1.集群擴容
當一個 Redis 新節點運行並加入現有集群後,我們需要為其遷移槽和數據。首先要為新節點指定槽的遷移計劃,確保遷移後每個節點負責相似數量的槽,從而保證這些節點的數據均勻。
- 首先啟動一個 Redis 節點,記為 M4。
- 使用 cluster meet 命令,讓新 Redis 節點加入到集群中。新節點剛開始都是主節點狀態,由於沒有負責的>槽,所以不能接受任何讀寫操作,後續我們就給他遷移槽和填充數據。
- 對 M4 節點發送 cluster setslot { slot } importing { sourceNodeId } 命令,讓目標節點準備導入槽的數據。 >4) 對源節點,也就是 M1,M2,M3 節點發送 cluster setslot { slot } migrating { targetNodeId } 命令,讓源節>點準備遷出槽的數據。
- 源節點執行 cluster getkeysinslot { slot } { count } 命令,獲取 count 個屬於槽 { slot } 的鍵,然後執行步驟>六的操作進行遷移鍵值數據。
- 在源節點上執行 migrate { targetNodeIp} ” ” 0 { timeout } keys { key… } 命令,把獲取的鍵通過 pipeline 機制>批量遷移到目標節點,批量遷移版本的 migrate 命令在 Redis 3.0.6 以上版本提供。
- 重復執行步驟 5 和步驟 6 直到槽下所有的鍵值數據遷移到目標節點。
- 向集群內所有主節點發送 cluster setslot { slot } node { targetNodeId } 命令,通知槽分配給目標節點。為瞭>保證槽節點映射變更及時傳播,需要遍歷發送給所有主節點更新被遷移的槽執行新節點。
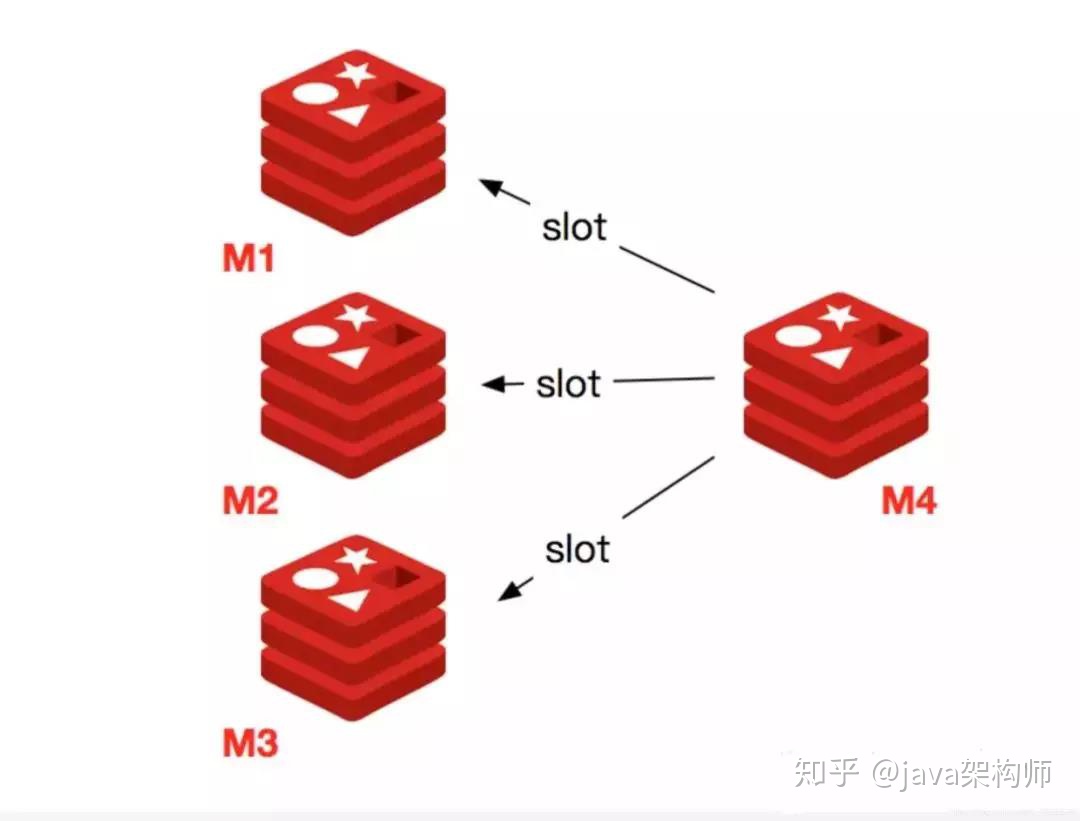
2.集群收縮
收縮節點就是將 Redis 節點下線,整個流程需要如下操作流程。
- 首先需要確認下線節點是否有負責的槽,如果是,需要把槽遷移到其他節點,保證節點下線後整個集群槽節點映射的完整性。
- 當下線節點不再負責槽或者本身是從節點時,就可以通知集群內其他節點忘記下線節點,當所有的節點忘記改節點後可以正常關閉。
下線節點需要將節點自己負責的槽遷移到其他節點,原理與之前節點擴容的遷移槽過程一致。
遷移完槽後,還需要通知集群內所有節點忘記下線的節點,也就是說讓其他節點不再與要下線的節點進行 Gossip 消息交換。
Redis 集群使用 cluster forget { downNodeId } 命令來講指定的節點加入到禁用列表中,在禁用列表內的節點不再發送 Gossip 消息。
五、總結
Redis Cluster 是Redis的集群實現,內置數據自動分片機制,集群內部將所有的key映射到16384個Slot中,集群中的每個Redis Instance負責其中的一部分的Slot的讀寫。集群客戶端連接集群中任一Redis Instance即可發送命令,當Redis Instance收到自己不負責的Slot的請求時,會將負責請求Key所在Slot的Redis Instance地址返回給客戶端,客戶端收到後自動將原請求重新發往這個地址,對外部透明。一個Key到底屬於哪個Slot由crc16(key) % 16384 決定。
面試問題:為什麼RedisCluster會設計成16384個槽呢?
這個問題,作者是給出瞭回答的!
地址如下:https://github.com/antirez/redis/issues/2576
作者原版回答如下: The reason is:
Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with16k slots, but would use a prohibitive 8k of space using 65k slots.At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.
1.如果槽位為65536,發送心跳信息的消息頭達8k,發送的心跳包過於龐大。
如上所述,在消息頭中,最占空間的是myslots[CLUSTER_SLOTS/8]。 當槽位為65536時,這塊的大小是:65536÷8÷1024=8kb因為每秒鐘,redis節點需要發送一定數量的ping消息作為心跳包,如果槽位為65536,這個ping消息的消息頭太大瞭,浪費帶寬。
2.redis的集群主節點數量基本不可能超過1000個。
如上所述,集群節點越多,心跳包的消息體內攜帶的數據越多。如果節點過1000個,也會導致網絡擁堵。因此redis作者,不建議redis cluster節點數量超過1000個。 那麼,對於節點數在1000以內的redis cluster集群,16384個槽位夠用瞭。沒有必要拓展到65536個。
3.槽位越小,節點少的情況下,壓縮率高
Redis主節點的配置信息中,它所負責的哈希槽是通過一張bitmap的形式來保存的,在傳輸過程中,會對bitmap進行壓縮,但是如果bitmap的填充率slots / N很高的話(N表示節點數),bitmap的壓縮率就很低。 如果節點數很少,而哈希槽數量很多的話,bitmap的壓縮率就很低。
而16384÷8÷1024=2kb,怎麼樣,神奇不!
綜上所述,作者決定取16384個槽,不多不少,剛剛好!
到此這篇關於為什麼RedisCluster設計成16384個槽的文章就介紹到這瞭,更多相關RedisCluster 16384槽內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!