利用pandas進行數據清洗的方法
我們有下面的一個數據,利用其做簡單的數據分析。
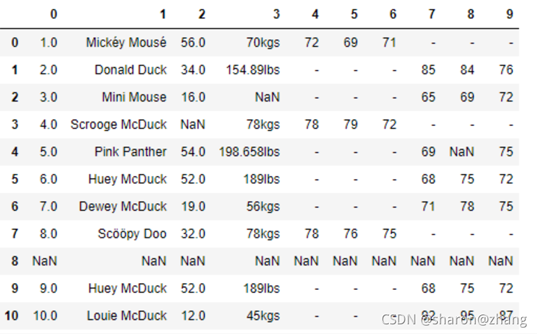
這是一傢服裝店統計的會員數據。最上面的一行是列坐標,最左側一列是行坐標。列坐標中,第 0 列代表的是序號,第 1 列代表的會員的姓名,第 2 列代表年齡,第 3 列代表體重,第 4~6 列代表男性會員的三圍尺寸,第 7~9 列代表女性會員的三圍尺寸。
數據清洗規則總結為以下 4 個關鍵點,統一起來叫“完全合一”,下面來解釋下:
- 完整性:單條數據是否存在空值,統計的字段是否完善。
- 全面性:觀察某一列的全部數值,比如在 Excel 表中,我們選中一列,可以看到該列的平均值、最大值、最小值。我們可以通過常識來判斷該列是否有問題,比如:數據定義、單位標識、數值本身。
- 合法性:數據的類型、內容、大小的合法性。比如數據中存在非 ASCII 字符,性別存在瞭未知,年齡超過瞭 150 歲等。
- 唯一性:數據是否存在重復記錄,因為數據通常來自不同渠道的匯總,重復的情況是常見的。行數據、列數據都需要是唯一的,比如一個人不能重復記錄多次,且一個人的體重也不能在列指標中重復記錄多次。
1、完整性
1.1 缺失值
一般情況下,由於數據量巨大,在采集數據的過程中,會出現有些數據單元沒有被采集到,也就是數據存在缺失。通常面對這種情況,我們可以采用以下三種方法:
- 刪除:刪除數據缺失的記錄
- 均值:使用當前列的均值填充
- 高頻:使用當前列出現頻率最高的數據
比如我們相對data[‘Age’]中缺失的數值使用平均年齡進行填充,可以寫:
df['Age'].fillna(df['Age'].mean(), inplace=True)
如果我們用最高頻的數據進行填充,可以先通過 value_counts 獲取 Age 字段最高頻次 age_maxf,然後再對 Age 字段中缺失的數據用 age_maxf 進行填充:
age_maxf = train_features['Age'].value_counts().index[0] train_features['Age'].fillna(age_maxf, inplace=True)
1.2 空行
我們發現數據中有一個空行,除瞭 index 之外,全部的值都是 NaN。Pandas 的 read_csv() 並沒有可選參數來忽略空行,這樣,我們就需要在數據被讀入之後再使用 dropna() 進行處理,刪除空行。
# 刪除全空的行 df.dropna(how='all',inplace=True)
2、全面性
列數據的單位不統一
如果某一列數據其單位並不統一,比如weight列,有的單位為千克(Kgs),有的單位是磅(Lbs)。
這裡我們使用千克作為統一的度量單位,將磅轉化為千克:
# 獲取 weight 數據列中單位為 lbs 的數據
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
print df[rows_with_lbs]
# 將 lbs轉換為 kgs, 2.2lbs=1kgs
for i,lbs_row in df[rows_with_lbs].iterrows():
# 截取從頭開始到倒數第三個字符之前,即去掉lbs。
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
3、合理性
非ASCII字符
假設在數據集中 Firstname 和 Lastname 有一些非 ASCII 的字符。我們可以采用刪除或者替換的方式來解決非 ASCII 問題,這裡我們使用刪除方法,也就是用replace方法:
# 刪除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
4、唯一性
4.1 一列有多個參數
假設姓名(Name)包含瞭兩個參數 Firstname和Lastname。為瞭達到數據整潔的目的,我們將 Name 列拆分成 Firstname 和 Lastname 兩個字段。我們使用 Python 的 split 方法,str.split(expand=True),將列表拆成新的列,再將原來的 Name 列刪除。
# 切分名字,刪除源數據列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
4.2 重復數據
我們校驗一下數據中是否存在重復記錄。如果存在重復記錄,就使用 Pandas 提供的 drop_duplicates() 來刪除重復數據。
# 刪除重復數據行 df.drop_duplicates(['first_name','last_name'],inplace=True)
這樣,我們就將上面案例中中的會員數據進行瞭清理,來看看清理之後的數據結果。

到此這篇關於利用pandas進行數據清洗的方法的文章就介紹到這瞭,更多相關pandas 數據清洗內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- pandas數據清洗(缺失值和重復值的處理)
- 淺談dataframe兩列相乘構造新特征
- pd.drop_duplicates刪除重復行的方法實現
- Pandas缺失值填充 df.fillna()的實現
- Python Pandas中DataFrame.drop_duplicates()刪除重復值詳解