Python深度學習albumentations數據增強庫
數據增強的必要性
深度學習在最近十年得以風靡得益於計算機算力的提高以及數據資源獲取的難度下降。一個好的深度模型往往需要大量具有label的數據,使得模型能夠很好的學習這種數據的分佈。而給數據打標簽往往是一件耗時耗力的工作。
拿cv裡的經典任務為例,classification需要人準確識別物品類別或者生物種類,object detection需要人工畫出bounding box, 確定其坐標,semantic segmentation甚至需要在像素級別進行標簽標註。對於一些專業領域的圖像標註,依賴於專業人士的知識素養(例如醫療,遙感等),這無疑對有標簽數據的收集帶來瞭麻煩。
那麼有沒有什麼方法能夠在數據集規模很小的情況,盡可能提高模型的表現力呢?
1.transfer learning或者說是domain adaptation,這種方法期望降低源域與目標域之間的數據分佈差異,使得具有大量標註數據的源域幫助提升模型的訓練效果。
2.對現有數據進行數據增強深度學習能夠學習到的空間不變性,像素級別的不變性特征都有限。所以對圖片進行平移,縮放,旋轉,改變色調值等方法,可以使得模型見過各種類型的數據,提高模型在測試數據上的判別力。
albumentations
上面我隻是籠統的談瞭下數據增強的必要性,對於其更加深刻的理解往往需要在實驗中不斷體會或者總結。
albumentations的安裝
這步沒什麼好說,利用包管理工具直接安裝。
pip install albumentations
albumentations的流水線工作方式
導入所需要的庫
import albumentations as A from PIL import Image import numpy as np
讀入數據這步需要其它庫進行配合,可以利用CV2,PIL等,這裡出於習慣我選擇使用PIL
image_path = './your/image/path' image = np.array(Image.open(image_path)) # 獲得瞭一個[H, W, C]的三維數組
創建流水線
transform = A.Compose([ A.Resize(width=256, height=256), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.2) ])
A.Compose中需要傳入一個list, list包含瞭一系列數據增強操作的對象。這裡可以理解為A.Compose返回一條工業流水線, 第一步進行A.Resize操作,將圖片縮放成256 * 256;第二步在上一步的基礎上以0.5的概率對圖片進行鏡像翻轉(p這個參數代表進行這個操作的概率);第三步同理,對第一步第二步處理完的圖像以0.2的概率進行亮度和對比度的改變。
transform就是我們將要對圖片進行的操作流程,下一步就需要將圖片數據傳入進去。
獲得數據增強完的圖片數據
transformed = transform(image=image) tranformed_image = transformed['image']
將圖片數據傳遞給transform(很明顯這是個可調用的對象)的image參數,它會返回一個處理完的對象,對象的key值image對應的value就是處理完的圖像數據。
圖像處理結果展示

object detection的數據增強
上述對albumentations流水線工作過程的簡要說明其實就是classification任務的大致流程。
當然,albumentations如果僅僅隻能做到上述的功能,那麼torchvision中transform API可以把它完全替代,並且它也滿足不瞭大多數cv任務的數據增強需求。
拿object detection為例,一張圖片數據往往對應瞭若幹個bounding box,如果你對圖片數據進行的操作具有空間變換性,那麼原有的bounding box數據畫出的目標框必然已經對應不瞭圖片中的對象瞭。
所以對圖片數據進行變換的同時也必須對bounding box數據進行變換,保持二者的一致性。
繪制目標框
在介紹object detection的數據增強之前,先介紹一個繪制目標框的函數。在albumentation中展示的代碼是用cv2實現,個人覺得畫出的bounding box不太美觀,下面使用的是matplotlib實現的代碼。
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def visualize_bbox(img, bbox, class_name, color, ax):
"""
img:圖片數據 (H, W, C)數據格式
bbox:array或者tensor, 假定數據格式是 [x_mid, y_mid, width, height]
classname:str 目標框對應的種類
color:str
thickness:目標框的寬度
"""
x_mid, y_mid, width, height = bbox
x_min = int(x_mid - width / 2)
y_min = int(y_mid - height / 2)
# 畫目標檢測框
rect = patches.Rectangle((x_min, y_min),
width,
height,
linewidth=3,
edgecolor=color,
facecolor="none"
)
ax.imshow(img)
ax.add_patch(rect)
ax.text(x_min + 1, y_min - 3, class_name, fontSize=10, bbox={'facecolor':color, 'pad': 3, 'edgecolor':color})
def visualize(img, bboxes, category_ids, category_id_to_name, category_id_to_color):
fig, ax = plt.subplots(1, figsize=(8, 8))
ax.axis('off')
for box, category in zip(bboxes, category_ids):
class_name = category_id_to_name[category]
color = category_id_to_color[category]
visualize_bbox(img, box, class_name, color, ax)
plt.show()

對bounding box進行空間變換
導入所需要的庫
import albumentations as A from PIL import Image import numpy as np image_path = './your/image/path' image = np.array(Image.open(image_path))
構造流水線
transform = A.Compose([ A.Resize(width=256, height=256), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.2) ], bbox_params = A.BboxParams(format='yolo'))
相較於最簡單的流水線(for classification),oject detection需要傳入一個叫做bbox_params的參數,它接收的是用於配置bounding box參數的對象。
format表示的是bounding box數據的格式,albumentations提供瞭4種格式。
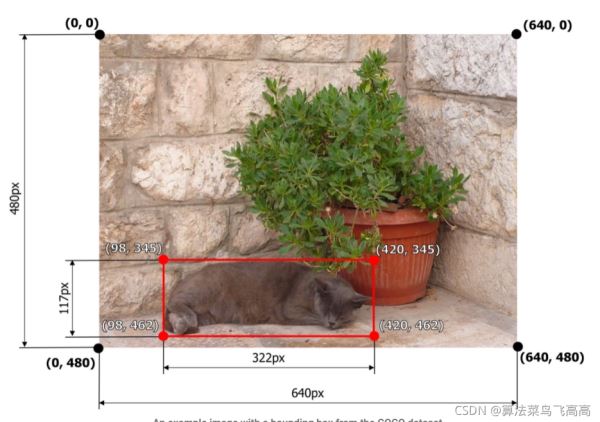
1.pascal_voc [x_min, y_min, x_max, y_max] 數值並沒有歸一化
直接使用像素值[98, 345, 420, 462]
2.albumentations [x_min, y_min, x_max, y_max] 與上一種格式不一樣的是
這裡值都是normalized 做瞭歸一化處理[0.153125, 0.71875, 0.65625, 0.9625]
3.coco [x_min, y_min, width, height] 沒有歸一化
4.yolo [x_center, y_center, width, height] 歸一化瞭
傳入image數據和bounding box數據進行變換
label = np.array([
[0.339, 0.6693333333333333, 0.402, 0.42133333333333334],
[0.379, 0.5666666666666667, 0.158, 0.3813333333333333],
[0.612, 0.7093333333333333, 0.084, 0.3466666666666667],
[0.555, 0.7026666666666667, 0.078, 0.34933333333333333]
]) # normalized (x_center, y_center, width, height) 對應format yolo
category_ids = [12, 14, 14, 14]
category_id_to_name = {
12: 'horse',
14: 'people'
}
category_id_to_color = {
12: 'yellow',
14: 'red'
}
transformed = transform(image=image,bboxes=label)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']
height, width, _ = transformed_image.shape
transformed_bboxes[:, [0, 2]] = transformed_bboxes[:, [0, 2]] * width
transformed_bboxes[:, [1, 3]] = transformed_bboxes[:, [1, 3]] * height
visualize(transformed_image, transformed_bboxes, category_ids, category_id_to_name, category_id_to_color)

BboxParams中不止format這一個參數。當我們做隨機裁剪操作的時候,bounding box完全可能隻保留瞭一部分,當保留比例小於某一個閾值的時候,我們可以將其drop掉,具體的操作細節可以查看albumentations的相關教程。
semantic segmentation的數據增強
object detection和semantic segmentation在像素級別的data agumentation和classification沒什麼區別,而在空間變換上segmentation沒有bounding box變換,與之對應的是mask變換。
mask是像素級別的label,與原圖中的像素一一對應。
albumentations上的教程使用的是kaggle上的數據集,這裡為瞭方便展示我們使用同樣的數據集。
數據集網址
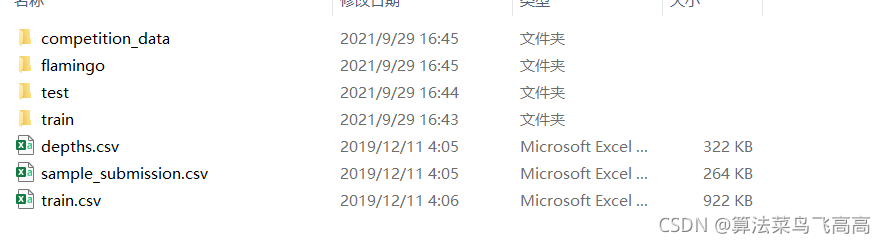
下載完數據並解壓縮完成後可以得到如上的目錄結構,通過train.csv文件可以得到所用的image和mask名稱。
image = np.array(Image.open(image_path)) # 這裡使用的是/train/images/0fea4b5049.png mask = np.array(Image.open(mask_path)) # /train/masks/0fea4b5049.png
下面介紹一下展示結果的函數
from matplotlib import pyplot as plt
def visualize(image, mask, original_image=None, original_mask=None):
fontsize=8
if original_image == None and original_mask == None:
fg, ax = plt.subplots(2, 1, figsize=(8, 8))
ax[0].axis('off')
ax[0].imshow(image)
ax[0].set_title('image', fontsize=fontsize)
ax[1].axis('off')
ax[1].imshow(mask)
ax[1].set_title('mask', fontsize=fontsize)
else:
fg, ax = plt.subplots(2, 2, figsize=(8, 8))
ax[0, 0].axis('off')
ax[0, 0].imshow(original_image)
ax[0, 0].set_title('Original Image', fontsize=fontsize)
ax[0, 1].axis('off')
ax[0, 1].imshow(original_mask)
ax[0, 1].set_title('Original Mask', fontsize=fontsize)
ax[1, 0].axis('off')
ax[1, 0].imshow(image)
ax[1, 0].set_title('Transformed Image', fontsize=fontsize)
ax[1, 1].axis('off')
ax[1, 1].imshow(mask)
ax[1, 1].set_title('Transformed Mask', fontsize=fontsize)
data agumentation的流水線操作
aug = A.PadIfNeeded(min_height=128, min_width=128, p=1) augmented = aug(image=image, mask=mask) augmented_img = augmented['image'] augmented_mask = augmented['mask'] visualize(augmented_img, augmented_mask, original_image=image, original_mask=mask)
這裡相較於classification就是多瞭個mask函數,將mask數據直接傳進入即可。
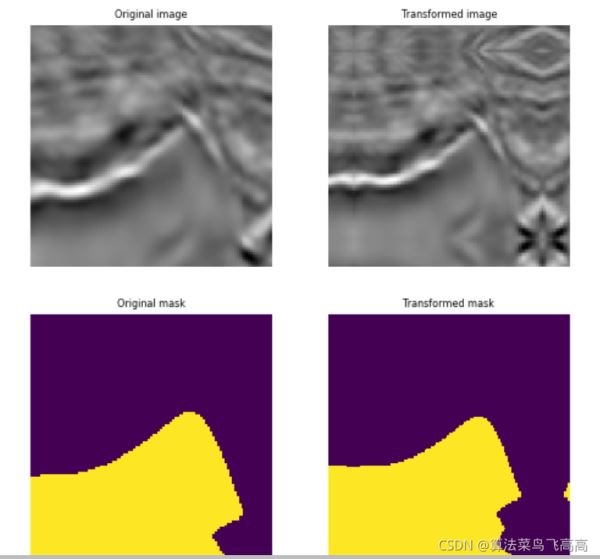
padding的填充方式默認是reflection, 可以看到變換以後的mask右側多瞭些黃色區域。
對於一些分割任務而言,我們不想增加或者刪除額外的信息,所以往往采用 Non destructive transformations(非破壞性變換)如HorizontalFlip(水平翻轉), VerticalFlip(垂直翻轉), RandomRotate90(Randomly rotates by 0, 90, 180, 270 degrees)
aug = A.RandomRotate(p=1) augmented = aug(image=image, mask=mask) augmented_image = augmented['image'] augmented_mask = augmented['mask'] visualize(augmented_image, augmented_mask, original_image=image, original_mask=mask)
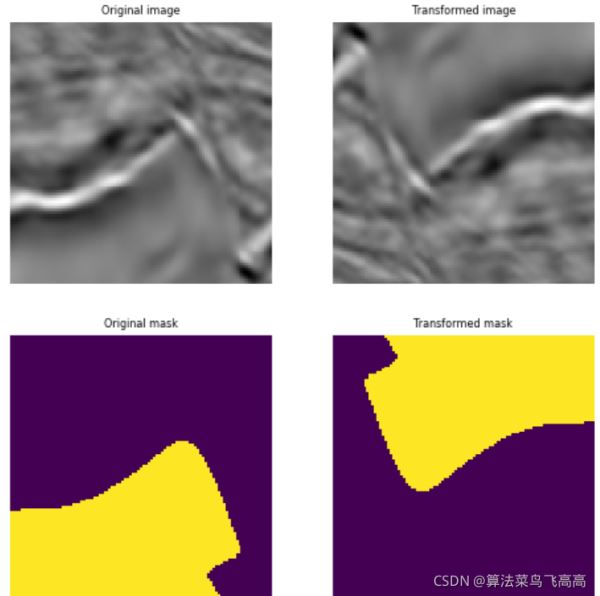
下面介紹下多個transform綜合起來的流水線操作
original_height, original_width = image.shape[:2]
aug = A.Compose([
A.OneOf([
A.RandomSizedCrop(min_max_height=(50, 101), height=original_height, width=original_width, p=0.5),
A.PadIfNeeded(min_height=original_height, min_width=original_width, p=0.5)
]),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.OneOf([
A.ElasticTransform(p=0.5, alpha=120, sigma=120 * 0.05, alpha_affine=120 * 0.03),
A.GridDistortion(p=0.5),
A.OpticalDistortion(distort_limit=1, shift_limit=0.5, p=1)
], p=0.8)
])
augmented = aug(image=image, mask=mask)
image_medium = augmented['image']
mask_medium = augmented['mask']
visualize(image_medium, mask_medium, original_image=image, original_mask=mask)
這裡一個較新的知識點是A.OneOf,它接收的transform對象的list, 從中按照權重隨機選擇一個進行變換,它本身也有概率。
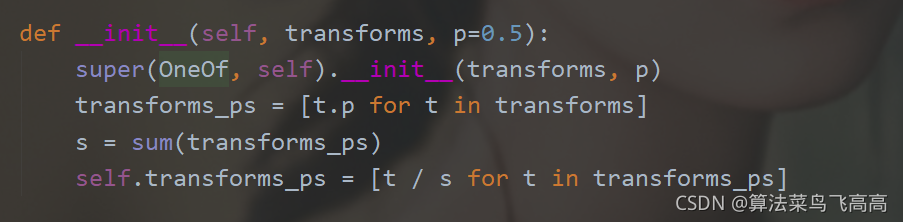
可以看到OneOf將list中的transform的概率進行歸一化再重新分配。所以這裡transform的p不再理解為概率,而是權重,取到1,甚至比1大都沒有關系。
以上就是Python深度學習albumentations數據增強庫的詳細內容,更多關於Python數據增強庫albumentations的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- Python實現隨機從圖像中獲取多個patch
- Python基於域相關實現圖像增強的方法教程
- python OpenCV圖像直方圖處理
- python詞雲庫wordcloud自定義詞雲制作步驟分享
- Python OpenCV對圖像像素進行操作