C和C++的區別詳解
通過程序來介紹
//c++ program
#include<iostream>
using namespace std;
int main(void)
{
cout << "This is a c++ program." << endl;
return 0;
}
1.iostream文件
iostream中的io指的是輸入(進入程序的信息)和輸出(從程序中發送出去的信息)。
並且c++的輸入、輸出方案涉及iostream文件中的多個定義。比如用來輸出信息的cout就在其中。
2.頭文件名的區別
C語言
C語言的傳統是頭文件使用擴展名 h,將其作為一種通過名稱標識文件類型的簡單方式。例如 math.h支持一些數學函數。
C++
C++頭文件沒有擴展名。
有些C頭文件被轉換成C++頭文件,這些文件被重新命名,去掉瞭擴展名h,並在文件名稱前面加上前綴c(表示來自C語言)
3.名稱空間namespace
如果使用的是iostream,而不是iostream.h,則應使用名稱空間編譯指令來使iostream中的定義對程序可用,即
using namespace std;
有瞭這句using編譯指令,才能使用cout、cin等,或者用第二種方式:
using std::cout; using std::cin; using std::endl;
名稱空間是C++的特性之一,簡單理解為:可以將自己的產品封裝起來。
示例
封裝性
示例:
首先定義一個頭文件

在裡面寫上我們自己編的東西:
#pragma once
namespace AA
{
typedef int INT;
typename char CHAR;
};
然後在cpp文件中引入該頭文件,但我們卻無法使用之前寫好的東西。
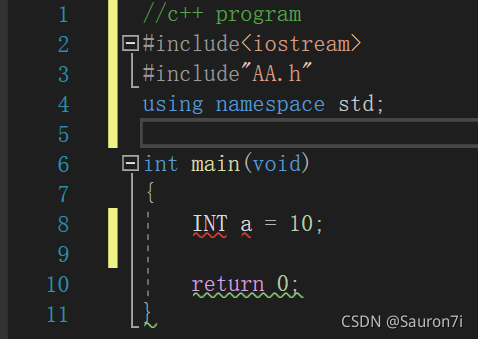
INT a會報錯,因為我們隻引入瞭頭文件,沒有使用裡面的名稱空間。
正確做法:
//c++ program
#include<iostream>
#include"AA.h"
using namespace std;
using namespace AA;
//using AA::INT;
int main(void)
{
INT a = 10;
cout << a << endl;
return 0;
}
需要第六行的該名稱空間才可以使用其中的產品。或者可以用第七行這種寫法來確定自己隻需要哪個產品。
運行結果:
4.使用cout進行C++的輸出
上面的程序有這條C++語句:
cout << "This is a C++ program." << endl;
<<符號表示該語句將把這個字符串發送給cout,該符號指出瞭信息流動路徑。 cout是一個預定義的對象。
從概念上看,輸出是一個流,即從程序流出的一系列字符。cout對象表示這種流,其屬性是在iostream文件中定義的。
cout的對象屬性包括一個插入運算符(<<),它可以將其右側的信息插入到流中。
圖示

指針和數組名的區別
程序示例:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int* p = &a;
int arr[] = { 0,1,2,3,4 };
cout << p << endl;
cout << arr << endl;
return 0;
}
這裡定義瞭一個指針p和一個數組arr。
運行結果都是地址

反匯編查看區別
cout << p << endl;
cout << p << endl; 008F52AF mov esi,esp 008F52B1 push offset std::endl<char,std::char_traits<char> > (08F103Ch) 008F52B6 mov edi,esp 008F52B8 mov eax,dword ptr [p] 008F52BB push eax
cout << arr << endl;
cout << arr << endl; 008F52DE mov esi,esp 008F52E0 push offset std::endl<char,std::char_traits<char> > (08F103Ch) 008F52E5 mov edi,esp 008F52E7 lea eax,[arr] 008F52EA push eax
區別

在輸出指針時,需要先從p裡面取出四字節,再放到寄存器裡push;
在輸出arr時,直接把arr放到寄存器裡再push。
結論
指針是變量;
數組名是一個地址——常量。
解引用
在C語言中學到,對指針解引用後得到的值就是它寸的地址對應的變量值。
可以來探索原理
程序示例
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int* p = &a;
*p = 20;
return 0;
}
反匯編代碼:
int a = 10; 000D18FF mov dword ptr [a],0Ah int* p = &a; 000D1906 lea eax,[a] 000D1909 mov dword ptr [p],eax *p = 20; 000D190C mov eax,dword ptr [p] 000D190F mov dword ptr [eax],14h
對於*p = 20
先從p的內存中取四個字節,即變量a的地址放入寄存器,再將20給到寄存器所存的的四字節中。完成對變量a的改變。
所以解引用的意思就是從地址中把值取出來,這裡是去p的地址裡取出所存的變量a的地址。
程序示例2:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10, b = 20;
int* p = &a;
b = *p;
return 0;
}
反匯編代碼:
int a = 10, b = 20; 000818FF mov dword ptr [a],0Ah 00081906 mov dword ptr [b],14h int* p = &a; 0008190D lea eax,[a] 00081910 mov dword ptr [p],eax b = *p; 00081913 mov eax,dword ptr [p] 00081916 mov ecx,dword ptr [eax] 00081918 mov dword ptr [b],ecx
對於 b = *p;
1.先去p裡取出四字節放入寄存器
2.再從寄存器eax取出四字節放入寄存器ecx再把ecx
3.的內容放入到變量b的四字節中。
也可以看出:解引用這一步其實是去地址裡取值的。
這樣也可以得出:用一個變量賦值給另一個變量,其實也是在解引用。
示例:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int b;
b = a;
return 0;
}
反匯編:
int a = 10; 002D18F5 mov dword ptr [a],0Ah int b; b = a; 002D18FC mov eax,dword ptr [a] 002D18FF mov dword ptr [b],eax
對於 b = a;
也是從a地址裡取出四字節放到寄存器,再通過寄存器給入b。
結論
解引用:到地址裡去取值。
const的區別
C語言中為常變量
示例:
//const
#include<stdio.h>
int main(void)
{
const int a = 10;
int b = 100; //常量賦值
b = a; //常變量賦值
return 0;
}
兩次賦值的區別:
const int a = 10; 00311825 mov dword ptr [a],0Ah int b = 100; 0031182C mov dword ptr [b],64h b = a; 00311833 mov eax,dword ptr [a] 00311836 mov dword ptr [b],eax
常量賦值時,是直接把值給到b的四字節中;
用const修飾的a賦值時,還是需要從a裡取出四字節再賦給b。
所以C語言中const修飾的變量叫做常變量——不能作為左值。
甚至可以用指針改變它的值:
#include<stdio.h>
int main(void)
{
const int a = 10;
int b = 100;
b = a;
int* p = &a;
*p = 20;
return 0;
}
a的變化:const修飾的變量a居然能被改變

C++中的const
在C++中,const修飾的變量就是常量,和常量性質一樣:
在編譯期間直接將常量的值替換到常量的使用點。
示例:
int main(void)
{
const int a = 10;
int b, c;
b = 16;
c = a;
return 0;
}
反匯編代碼:
const int a = 10; 00B917F5 mov dword ptr [a],0Ah int b, c; b = 16; 00B917FC mov dword ptr [b],10h c = a; 00B91803 mov dword ptr [c],0Ah
可以看出,對b賦值常量是直接賦值;
對c賦值const修飾的變量a,同樣是用常量賦值的。所以:
在C++中, const修飾的變量和常量性質一樣,都是在編譯期將常量值替換到常量的使用點。
另外
1.而且const修飾的變量必須初始化,同樣因為編譯期間就會替換為常量,不初始化,後面也沒有機會再對其賦值。
2.如果用變量對const修飾的變量賦值,則會使其退化成常變量。
聲明時const位置不同的區別
示例:
const可在不同位置修飾變量
int main(void)
{
int a = 10;
int* p1 = &a;
const int* p2 = &a;
int const* p3 = &a;
int* const p4 = &a;
int* q1 = &a;
const int* q2 = &a;
int const* q3 = &a;
int* const q4 = &a;
return 0;
}
要註意的是:
const與離他最近的類型結合,是該變量的類型,除瞭最近的類型,剩下的就是const修飾的內容。
const修飾的內容是不可作為左值。
根據上面的原理,來判斷以下內容:
p1 = q1; p1 = q2; p1 = q3; p1 = q4; p2 = q1; p2 = q2; p2 = q3; p2 = q4; p3 = q1; p3 = q2; p3 = q3; p3 = q4; p4 = q1; p4 = q2; p4 = q3; p4 = q4;
p1是普通指針。
對於
const int* p2和int const* p3
const修飾的類型是離他最近的類型,即int,剩下的為const所修飾的內容,所以它們兩個所修飾的內容為 *p2 、*p3。
對於int* const p4
const修飾的類型為int*,那修飾的內容就是p4。
下面的四個q同理。
可以推出錯誤的是:
p1 = q2; p1 = q3; p4 = q1; p4 = q2; p4 = q3; p4 = q4;
因為 *q2 和 *q3不能改變,所以把 q2/q3賦值給普通指針時,會造成普通指針來改變其中內容的後果,即 泄露常量地址給非常量指針 ,所以不能這樣賦值。
p4為const修飾的內容,不能被改變。
const修飾形參
這裡主要說能否形成函數重載的問題
程序示例:
int fun(int a)
{
return a;
}
int fun(const int a)
{
return a;
}
編譯器並沒有報錯,但編譯無法通過,原因如下

結論:如果const修飾的內容不包括指針,則不參與類型問題。
引用變量
之前C語言學到,&符號用來指示變量的地址。
C++給該符號賦予瞭另一個含義,將其用來聲明引用。
示例,若我想用 A作為變量 a的別名,可以這樣用:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int& A = a;
A = 20;
cout << a << endl;
cout << A << endl;
return 0;
}
運行示例:

通過A可以改變a的值,這就是引用。A相當於a的別名,就和魯迅和周樹人一樣。。。
引用的原理
示例:
int a = 10; int& A = a; int* p = &a;
反匯編代碼:
int& A = a; 00ED5326 lea eax,[a] 00ED5329 mov dword ptr [A],eax int* p = &a; 00ED532C lea eax,[a] 00ED532F mov dword ptr [p],eax
可以看出:引用的實現居然和指針是一樣的。
所以引用的底層是一個指針。
結論:在使用到引用的地方,編譯期會自動替換成底層指針的解引用。
常問問題
1.引用為什麼必須初始化?
2.引用為什麼一經過初始化,就無法改變引用的方向?
答:因為隻有在初始化的時候能給它賦值,其他使用到它的地方都替換成瞭底層指針
無法改變底層指針的指向,所以無法改變引用的方向。
3.不能將const限定的變量賦給普通引用變量:
原因是將常量的地址賦給瞭普通指針。
const int a = 10; int& b = a; //錯誤
4.當引用一個不可以取地址的量的時候,使用常引用。
會生成一個臨時量,然後常引用臨時量,臨時量都有常屬性。
示例:
int& a = 10; //錯誤 const int& a = 10; //正確
動態申請空間的區別
C語言
使用malloc和free
示例:
int main(void)
{
//申請一維數組與釋放
int* arr = (int*)malloc(sizeof(int) * 10);
if (arr == NULL)
return -1;
free(arr);
//申請二維數組與釋放
int** brr = (int**)malloc(sizeof(int*) * 10);
if (brr == NULL)
return -1;
for (int i = 0; i < 10; ++i)
{
free(brr[i]);
}
return 0;
}
C++
int main(void)
{
//申請int類型變量
int* p = new int;
*p = 10;
delete p;
//申請int類型數組
int* arr = new int[10];
arr[0] = 10;
delete[]arr;
//申請二維數組
int** brr = new int* [5];
for (int i = 0; i < 5; ++i)
{
brr[i] = new int[10];
}
for (int i = 0; i < 5; ++i)
{
delete[]brr[i];
}
return 0;
}
new後面跟的類型就表示申請的大小。
面向過程和面向對象
C語言
面向過程語言
示例
void echo()
{
if (flag == 0)
{
printf("printf screen\n");
}
else if (flag == 1)
{
printf("printf file\n");
}
}
void Set_flag_file()
{
flag = 1;
}
void Set_flag_screen()
{
flag = 0;
}
對於這個打印函數,可以通過改變flag的值來控制其打印的結果。
但如果改變flag,也會改變其他地方調用的打印函數的結果。
所以C語言沒有封裝性。
C++
面向對象語言
class Note
{
public:
Note()
{
flag = 0;
}
void echo()
{
if (flag == 0)
{
printf("printf screen\n");
}
else if (flag == 1)
{
printf("printf file\n");
}
}
void Set_flag_file()
{
flag = 1;
}
void Set_flag_screen()
{
flag = 0;
}
private:
int flag;
};
使用示例:
int main(void)
{
Note n;
n.echo();
n.Set_flag_file();
n.echo();
return 0;
}
運行結果:
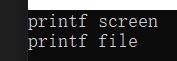
C語言作為面向過程語言,如果示例中的flag做出改變,會影響全局的改變。
C++作為半面向對象語言,具有封裝性,若想改變示例中想打印的值,隻會影響到這個模塊。
總結
本篇文章就到這裡瞭,希望能夠給你帶來幫助,也希望您能夠多多關註WalkonNet的更多內容!