Python編程pytorch深度卷積神經網絡AlexNet詳解
2012年,AlexNet橫空出世。它首次證明瞭學習到的特征可以超越手工設計的特征。它一舉打破瞭計算機視覺研究的現狀。AlexNet使用瞭8層卷積神經網絡,並以很大的優勢贏得瞭2012年的ImageNet圖像識別挑戰賽。
下圖展示瞭從LeNet(左)到AlexNet(right)的架構。
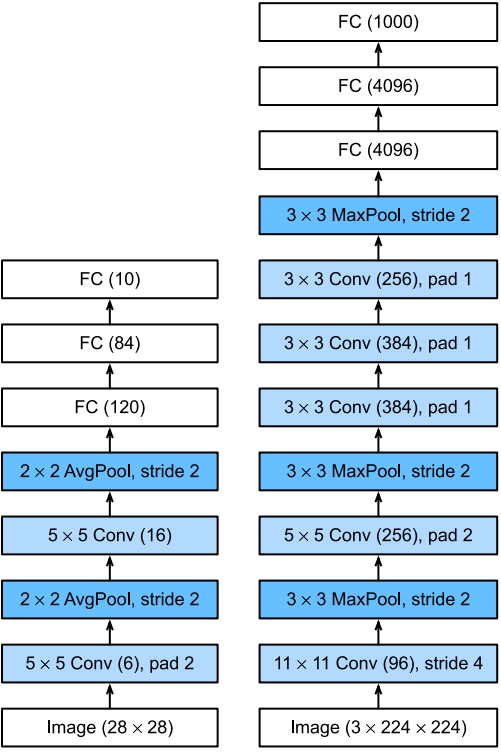
AlexNet和LeNet的設計理念非常相似,但也有如下區別:
- AlexNet比相對較小的LeNet5要深得多。
- AlexNet使用ReLU而不是sigmoid作為其激活函數。
容量控制和預處理
AlexNet通過dropout控制全連接層的模型復雜度,而LeNet隻使用瞭權重衰減。為瞭進一步擴充數據,AlexNet在訓練時增加瞭大量的圖像增強數據,如翻轉、裁剪和變色。這使得模型更加健壯,更大的樣本量有效地減少瞭過擬合。
import torch from torch import nn from d2l import torch as d2l net = nn.Sequential( # 這裡,我們使用一個11*11的更大窗口來捕捉對象 # 同時,步幅為4,以減少輸出的高度和寬度 # 另外,輸出通道的數目遠大於LeNet nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2) # 減少卷積窗口,使用填充為2來使得輸入與輸出的高和寬一致,且增大輸出通道數 nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2) # 使用三個連續的卷積層和較小的卷積窗口 # 除瞭最後的卷積層,輸出通道的數量進一步增加 # 在前兩個卷積層之後,匯聚層不用於減少輸入的高度和寬度 nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(), # 這裡,全連接層的輸出數量是LeNet中的好幾倍。使用dropout層來減輕過度擬合 nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5), # 最後是輸出層。由於這裡使用Fashion-MNIST,所以用類別數位10 nn.Linear(4096, 10) )
我們構造一個高度和寬度都為224的單通道數據,來觀察每一層輸出的形狀。它與上面離得最近的圖中的AlexNet架構相匹配。
X = torch.randn(1, 1, 224, 224) for layer in net: X = layer(X) print(layer.__class__.__name__,'Output shape:\t', X.shape)
Conv2d Output shape: torch.Size([1, 96, 54, 54]) ReLU Output shape: torch.Size([1, 96, 54, 54]) MaxPool2d Output shape: torch.Size([1, 96, 26, 26]) Conv2d Output shape: torch.Size([1, 256, 26, 26]) ReLU Output shape: torch.Size([1, 256, 26, 26]) MaxPool2d Output shape: torch.Size([1, 256, 12, 12]) Conv2d Output shape: torch.Size([1, 384, 12, 12]) ReLU Output shape: torch.Size([1, 384, 12, 12]) Conv2d Output shape: torch.Size([1, 384, 12, 12]) ReLU Output shape: torch.Size([1, 384, 12, 12]) Conv2d Output shape: torch.Size([1, 256, 12, 12]) ReLU Output shape: torch.Size([1, 256, 12, 12]) MaxPool2d Output shape: torch.Size([1, 256, 5, 5]) Flatten Output shape: torch.Size([1, 6400]) Linear Output shape: torch.Size([1, 4096]) ReLU Output shape: torch.Size([1, 4096]) Dropout Output shape: torch.Size([1, 4096]) Linear Output shape: torch.Size([1, 4096]) ReLU Output shape: torch.Size([1, 4096]) Dropout Output shape: torch.Size([1, 4096]) Linear Output shape: torch.Size([1, 10])
讀取數據集
在這裡將AlexNet直接應用於Fashion-MNIST的識別,但這裡有一個問題,那就是Fashion-MNIST圖像的分辨率( 28 × 28 28\times28 28×28像素)低於ImageNet圖像。為瞭解決這個問題,我們將它們增加到 224 × 224 224\times224 224×224(通常來講這不是一個明智的做法,但我們在這裡這樣做是為瞭有效使用AlexNet結構)。我們使用d2l.load_data_fashion_mnist函數中的resize參數執行此調整。
batch_size = 128 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
現在,我們可以開始訓練AlexNet瞭,與LeNet相比,這裡的主要變化是使用更小的學習速率訓練,這是因為網絡更深更廣、圖像分辨率更高,訓練卷積伸進網絡就更昂貴。
lr, num_epochs = 0.01, 10 d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
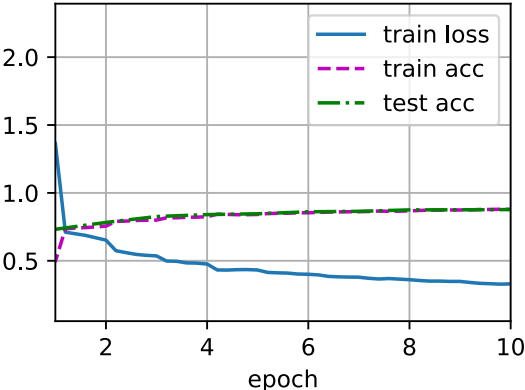
loss 0.330, train acc 0.879, test acc 0.877 4163.0 examples/sec on cuda:0
以上就是Python編程pytorch深度卷積神經網絡AlexNet詳解的詳細內容,更多關於pytorch卷積神經網絡的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- Python深度學習pytorch神經網絡塊的網絡之VGG
- Python深度學習pytorch卷積神經網絡LeNet
- 淺談Pytorch 定義的網絡結構層能否重復使用
- PyTorch零基礎入門之構建模型基礎
- Python LeNet網絡詳解及pytorch實現