Python機器學習pytorch模型選擇及欠擬合和過擬合詳解
訓練誤差和泛化誤差
訓練誤差是指,我們的模型在訓練數據集上計算得到的誤差。
泛化誤差是指,我們將模型應用在同樣從原始樣本的分佈中抽取的無限多的數據樣本時,我們模型誤差的期望。
在實際中,我們隻能通過將模型應用於一個獨立的測試集來估計泛化誤差,該測試集由隨機選取的、未曾在訓練集中出現的數據樣本構成。
模型復雜性
在本節中將重點介紹幾個傾向於影響模型泛化的因素:
可調整參數的數量。當可調整參數的數量(有時稱為自由度)很大時,模型往往更容易過擬合。參數采用的值。當權重的取值范圍較大時,模型可能更容易過擬合。訓練樣本的數量。即使模型非常簡單,也很容易過擬合隻包含一兩個樣本的數據集。而過擬合一個有數百萬個樣本的數據集則需要一個極其靈活的模型。
模型選擇
在機器學習中,我們通常在評估幾個候選模型後選擇最終的模型。這個過程叫做模型的選擇。有時,需要進行比較的模型在本質上是完全不同的(比如,決策樹與線性模型)。又有時,我們需要比較不同的超參數設置下的同一類模型。
例如,訓練多層感知機模型時,我們可能希望比較具有不同數量的隱藏層、不同數量的隱藏單元以及不同的激活函數組合的模型。為瞭確定候選模型的最佳模型,我們通常會使用驗證集。
驗證集
原則上,在我們確定所有的超參數之前,我們不應該用到測試集。如果我們在模型選擇過程中使用瞭測試數據,可能會有過擬合測試數據的風險。
如果我們過擬合瞭訓練數據,還有在測試數據上的評估來判斷過擬合。
但是如果我們過擬合瞭測試數據,我們又應該怎麼知道呢?
我們不能依靠測試數據進行模型選擇。也不能僅僅依靠訓練數據來選擇模型,因為我們無法估計訓練數據的泛化誤差。
解決此問題的常見做法是將我們的數據分成三份,除瞭訓練和測試數據集之外,還增加一個驗證數據集(validation dataset),也叫驗證集(validation set)。
但現實是,驗證數據和測試數據之間的界限非常模糊。在之後實際上是使用應該被正確地稱為訓練數據和驗證數據的東西,並沒有真正的測試數據集。因此,之後的準確度都是驗證集準確度,而不是測試集準確度。
K折交叉驗證
當訓練數據稀缺時,我們甚至可能無法提供足夠的數據來構成一個合適的驗證集。這個問題的一個流行的解決方案是采用 K K K折交叉驗證。這裡,原始訓練數據被分成 K個不重疊的子集。然後執行K次模型訓練和驗證,每次在K−1個子集上進行訓練,並在剩餘的一個子集(在該輪中沒有用於訓練的子集)上進行驗證。最後,通過K次實驗的結果取平均來估計訓練和驗證誤差。
欠擬合還是過擬合?
當我們比較訓練和驗證誤差時,我們要註意兩種常見的情況。
首先,我們要註意這樣的情況:訓練誤差和驗證誤差都很嚴重,但它們之間僅有一點差距。如果模型不能降低訓練誤差,這可能意味著我們的模型過於簡單(即表達能力不足),無法捕獲我們試圖學習的模式。此外,由於我們的訓練和驗證誤差之間的泛化誤差很小,我們有理由相信可以用一個更復雜的模型降低訓練誤差。這種現象被稱為欠擬合。
另一方面,當我們的訓練誤差明顯低於驗證誤差時要小心,這表明嚴重的過擬合。註意,過擬合並不總是一件壞事。
我們是否過擬合或欠擬合可能取決於模型的復雜性和可用數據集的大小,這兩個點將在下面進行討論。
模型復雜性

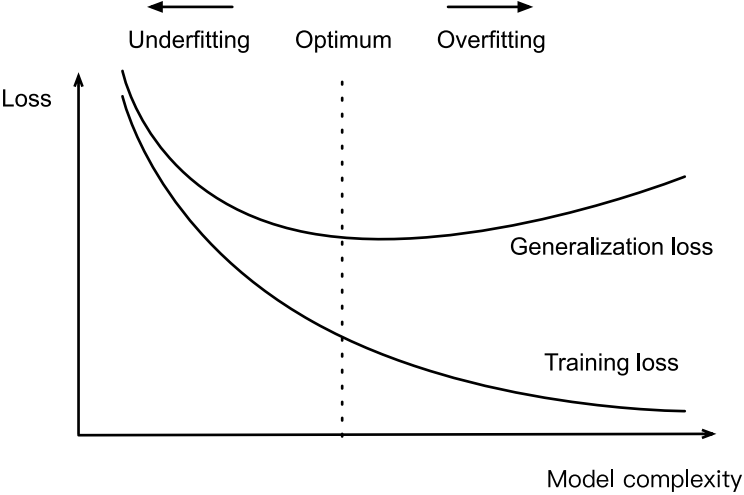
告誡多項式函數比低階多項式函數復雜得多。高階多項式的參數較多,模型函數的選擇范圍較廣。因此在固定訓練數據集的情況下,高階多項式函數相對於低階多項式的訓練誤差應該始終更低(最壞也是相等)。事實上,當數據樣本包含瞭 x的不同取值時,函數階數等於數據樣本數量的多項式函數可以完美擬合訓練集。在下圖中,我們直觀地描述瞭多項式的階數和欠擬合與過擬合之間的關系。
數據集大小
訓練數據集中的樣本越少,我們就越可能(且更嚴重地)遇到過擬合。隨著訓練數據量的增加,泛化誤差通常會減小。此外,一般來說,更多的數據不會有什麼壞處。
以上就是Python機器學習pytorch模型選擇及欠擬合和過擬合詳解的詳細內容,更多關於pytorch模型選擇及欠擬合和過擬合的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- Anaconda安裝pytorch及配置PyCharm 2021環境
- 使用pytorch加載並讀取COCO數據集的詳細操作
- M1 mac安裝PyTorch的實現步驟
- Win10系統下Pytorch環境的搭建過程
- 人工智能學習Pytorch張量數據類型示例詳解