基於Jupyter notebook搭建Spark集群開發環境的詳細過程
一、概念介紹:
1、Sparkmagic:它是一個在Jupyter Notebook中的通過Livy服務器 Spark REST與遠程Spark群集交互工作工具。Sparkmagic項目包括一組以多種語言交互運行Spark代碼的框架和一些內核,可以使用這些內核將Jupyter Notebook中的代碼轉換在Spark環境運行。
2、Livy:它是一個基於Spark的開源REST服務,它能夠通過REST的方式將代碼片段或是序列化的二進制代碼提交到Spark集群中去執行。它提供瞭以下這些基本功能:提交Scala、Python或是R代碼片段到遠端的Spark集群上執行,提交Java、Scala、Python所編寫的Spark作業到遠端的Spark集群上執行和提交批處理應用在集群中運行
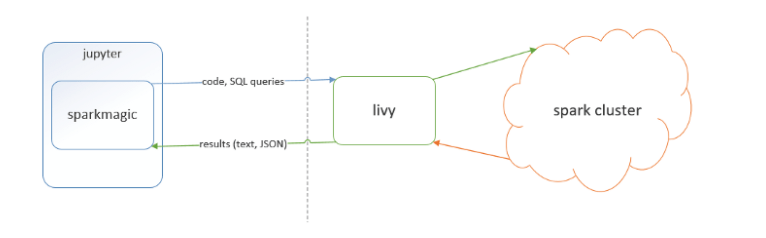
二、基本框架
為下圖所示:
三、準備工作:
具備提供Saprk集群,自己可以搭建或者直接使用華為雲上服務,如MRS,並且在集群上安裝Spark客戶端。同節點(可以是docker容器或者虛擬機)安裝Jupyter Notebook和Livy,安裝包的路徑為:https://livy.incubator.apache.org/download/
四、配置並啟動Livy:
修改livy.conf參考:https://enterprise-docs.anaconda.com/en/latest/admin/advanced/config-livy-server.html
添加如下配置:
livy.spark.master = yarn livy.spark.deploy-mode = cluster livy.impersonation.enabled = false livy.server.csrf-protection.enabled = false livy.server.launch.kerberos.keytab=/opt/workspace/keytabs/user.keytab livy.server.launch.kerberos.principal=miner livy.superusers=miner
修改livy-env.sh, 配置SPARK_HOME、HADOOP_CONF_DIR等環境變量
export JAVA_HOME=/opt/Bigdata/client/JDK/jdk export HADOOP_CONF_DIR=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop export SPARK_HOME=/opt/Bigdata/client/Spark2x/spark export SPARK_CONF_DIR=/opt/Bigdata/client/Spark2x/spark/conf export LIVY_LOG_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/logs export LIVY_PID_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/pids export LIVY_SERVER_JAVA_OPTS="-Djava.security.krb5.conf=/opt/Bigdata/client/KrbClient/kerberos/var/krb5kdc/krb5.conf -Dzookeeper.server.principal=zookeeper/hadoop.hadoop.com -Djava.security.auth.login.config=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop/jaas.conf -Xmx128m"
啟動Livy:
./bin/livy-server start
五、安裝Jupyter Notebook和sparkmagic
Jupyter Notebook是一個開源並且使用很廣泛項目,安裝流程不在此贅述
sparkmagic可以理解為在Jupyter Notebook中的一種kernel,直接pip install sparkmagic。註意安裝前系統必須具備gcc python-dev libkrb5-dev工具,如果沒有,apt-get install或者yum install安裝。安裝完以後會生成$HOME/.sparkmagic/config.json文件,此文件為sparkmagic的關鍵配置文件,兼容spark的配置。關鍵配置如圖所示

其中url為Livy服務的ip和端口,支持http和https兩種協議
六、添加sparkmagic kernel
PYTHON3_KERNEL_DIR=”$(jupyter kernelspec list | grep -w “python3″ | awk ‘{print $2}’)”
KERNELS_FOLDER=”$(dirname “${PYTHON3_KERNEL_DIR}”)”
SITE_PACKAGES=”$(pip show sparkmagic|grep -w “Location” | awk ‘{print $2}’)”
cp -r ${SITE_PACKAGES}/sparkmagic/kernels/pysparkkernel ${KERNELS_FOLDER}
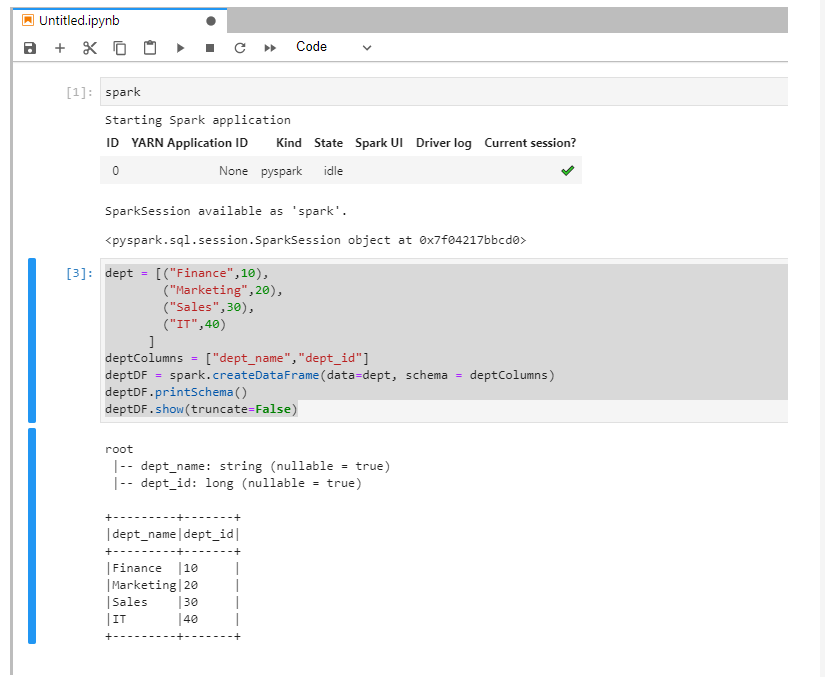
七、在Jupyter Notebook中運行spark代碼驗證:
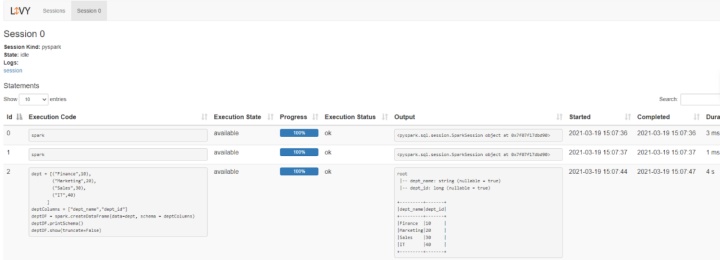
八、訪問Livy查看當前session日志:
到此這篇關於基於Jupyter notebook搭建Spark集群開發環境的詳細過程的文章就介紹到這瞭,更多相關基於Jupyter notebook搭建Spark集群開發環境內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- jupyter notebook內核配置的圖文教程
- pycharm利用pyspark遠程連接spark集群的實現
- 終端能到import模塊 解決jupyter notebook無法導入的問題
- 基於雲服務MRS構建DolphinScheduler2調度系統的案例詳解
- python入門jupyter基礎操作及文本用法