十分鐘上手正則表達式 下篇

前面,我們就正則表達式一些常用的基本方法做瞭詳細的介紹,本篇會講解一些拓展性的知識,主要的就是常見的ERE模式符號以及shell腳本中常見的一些正則表達式例子。
快速學習正則表達式,不用死記硬背,示例讓你通透(上篇)
一、正則表達式常用符號
本章示例著重於在gawk程序腳本中的較常見的ERE模式符號。
1.1 問號【?】
問號類似於星號,不過有點細微的不同。問號表明前面的字符可以出現 0 次或 1 次,但隻限於 此。它不會匹配多次出現的字符。 示例展示:

腳本解說:
如果字符 e 並未在文本中出現,或者它隻在文本中出現瞭 1 次,那麼模式會匹配。
和星號一樣,可以將問號和字符組一起使用。
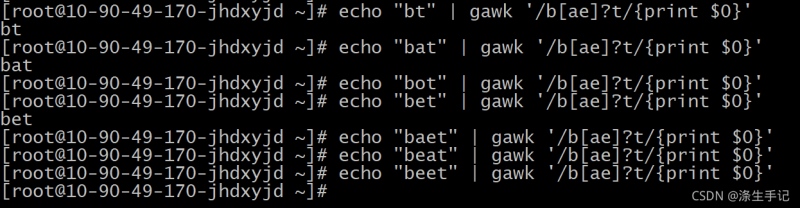
腳本解說:
如果字符組中的字符出現瞭 0 次或 1 次,模式匹配就成立。但如果兩個字符都出現瞭,或者其中一個字符出現瞭2 次,模式匹配就不成立。
1.2 加號【+】
加號是類似於星號的另一個模式符號,但跟問號也有不同。加號表明前面的字符可以出現 1次或多次,但必須至少出現1 次。如果該字符沒有出現,那麼模式就不會匹配。

示例解說:
如果字符 e 沒有出現,模式匹配就不成立。加號同樣適用於字符組,與星號和問號的使用方式相同。

腳本解讀:
如果字符組中定義的任一字符出現瞭,文本就會匹配指定的模式。
1.3 花括號{}
ERE 中的花括號允許為可重復的正則表達式指定一個上限。這通常稱為 間隔 ( interval )。 可以用兩種格式來指定區間。
- m:正則表達式準確出現m次。
- m, n:正則表達式至少出現m次,至多n次。
這個特性可以精確調整字符或字符集在模式中具體出現的次數。
重點說明:
默認情況下, gawk 程序不會識別正則表達式間隔。必須指定 gawk 程序的 –re- interval 命令行選項才能識別正則表達式間隔。
示例:

示例解讀:
通過指定間隔為 1 ,限定瞭該字符在匹配模式的字符串中出現的次數。如果該字符出現多次, 模式匹配就不成立。
同樣也可以指定上限和下限

示例解讀:
字符 e 可以出現 1 次或 2 次,這樣模式就能匹配;否則,模式無法匹配。
下面是字符組的示例:

示例解讀:
如果字母 a 或 e 在文本模式中隻出現瞭 1~2 次,則正則表達式模式匹配;否則,模式匹配失敗。
1.4 管道符號【|】
管道符號允許在檢查數據流時,用邏輯 OR 方式指定正則表達式引擎要用的兩個或多個模式。如果任何一個模式匹配瞭數據流文本,文本就通過測試。如果沒有模式匹配,則數據流文本匹配失敗。
使用格式:
expr1 |expr2|…
示例:

示例解讀:
這個例子會在數據流中查找正則表達式 cat 或 dog 。正則表達式和管道符號之間不能有空格, 否則它們也會被認為是正則表達式模式的一部分。
管道符號兩側的正則表達式可以采用任何正則表達式模式(包括字符組)來定義文本。看下面示例:

示例解讀:
這個例子會匹配數據流文本中的 cat 、 hat 或 dog 。
1.5 小括號()
正則表達式模式也可以用圓括號進行分組。當將正則表達式模式分組時,該組會被視為一個標準字符。可以像對普通字符一樣給該組使用特殊字符。
示例:

示例解讀:
結尾的 urday 分組以及問號,使得模式能夠匹配完整的 Saturday 或縮寫 Sat 。
將分組和管道符號一起使用來創建可能的模式匹配組是很常見的做法。如下示例:
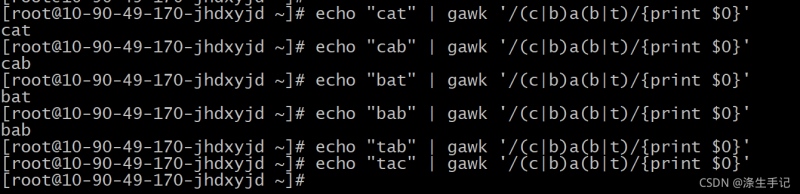
示例解讀:
模式 (c|b)a(b|t) 會匹配第一組中字母的任意組合以及第二組中字母的任意組合。
二、正則表達式實戰示例
示例1:
下面會有一個腳本,功能是對PATH環境變量中定義的目錄裡的可執行文件進行計數。
腳本內容如下:
#!/bin/bash # count number of files in your PATH mypath=$(echo $PATH | sed 's/:/ /g') #用空格來替換冒號,分割路徑 count=0 for directory in $mypath do check=$(ls $directory) for item in $check do count=$[ $count + 1 ] done echo "$directory - $count" count=0 done
執行結果:

示例2:
正則表達式解析郵件地址
郵件地址的基本格式為:username@hostname
username值可用字母數字字符以及以下特殊字符:(點號、單破折線、 加號、 下劃線)
在有效的郵件用戶名中,這些字符可能以任意組合形式出現。郵件地址的hostname部分由一個或多個域名和一個服務器名組成。服務器名和域名也必須遵照嚴格的命名規則,隻允許字母數字字符以及以下特殊字符:(點號、下劃線)
服務器名和域名都用點分隔,先指定服務器名,緊接著指定子域名,最後是後面不帶點號的
頂級域名。
頂級域名的數量在過去十分有限,正則表達式模式編寫者會嘗試將它們都加到驗證模式中。
然而遺憾的是,隨著互聯網的發展,可用的頂級域名也增多瞭。這種方法已經不再可行。
從左側開始構建這個正則表達式模式。
過濾用戶名中表達式模式。
^([a-zA-Z0-9_\-\.\+]+)@
這個分組指定瞭用戶名中允許的字符,加號表明必須有至少一個字符。下一個字符很明顯是@。
hostname模式使用同樣的方法來匹配服務器名和子域名:
([a-zA-Z0-9_\-\.]+)
頂級域名用的正則表達式模式:
\.([a-zA-Z]{2,5})$
整體組合模式:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$
封裝到腳本中:
cat isemail.sh
#!/bin/bash
# script to filter out bad phone numbers
awk --re-interval '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})/{print $0}'
註意:在awk程序中使用正則表達式間隔時,必須使用–re-interval命令行選項。
示例測試腳本:

示例解讀:
符合規則的郵件名會打印在屏幕,不符合的會被過濾掉,不會有內容輸出。
到此這篇關於十分鐘上手正則表達式 下篇的文章就介紹到這瞭,更多相關正則表達式 入門內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- shell 流程控制語句的具體使用
- Shell編程之變量的高級用法詳解
- Shell expr命令進行整數計算的實現
- MySQL DATE_ADD和ADDDATE函數實現向日期添加指定時間間隔
- 詳解Shell if else語句的具體使用方法