使用PyCharm批量爬取小說的完整代碼
使用pycharm批量爬取小說
爬取小說的思路:
1.獲取小說地址
本文以搜書網一小說為例《噓,梁上有王妃!》
目錄網址:https://www.soshuw.com/XuLiangShangYouWangFei/
加載需要的包:
import re from bs4 import BeautifulSoup as ds import requests
獲取小說目錄文件,返回<Response [200]>,表示可正常爬取該網頁
base_url='https://www.soshuw.com/XuLiangShangYouWangFei/' chapter_html=requests.get(base_url) print(chapter_html)
2.分析小說地址結構
解析目錄網頁 , 輸出結果為目錄網頁的源代碼
chapter_page_html=ds(chapter_page,'lxml') print(chapter_page)
打開目錄網頁,發現在正文的目錄前面有一個最新章節目錄(這裡有九個章節),再完整的目錄中是包含最新章節的,所以這裡最新章節是不需要的。
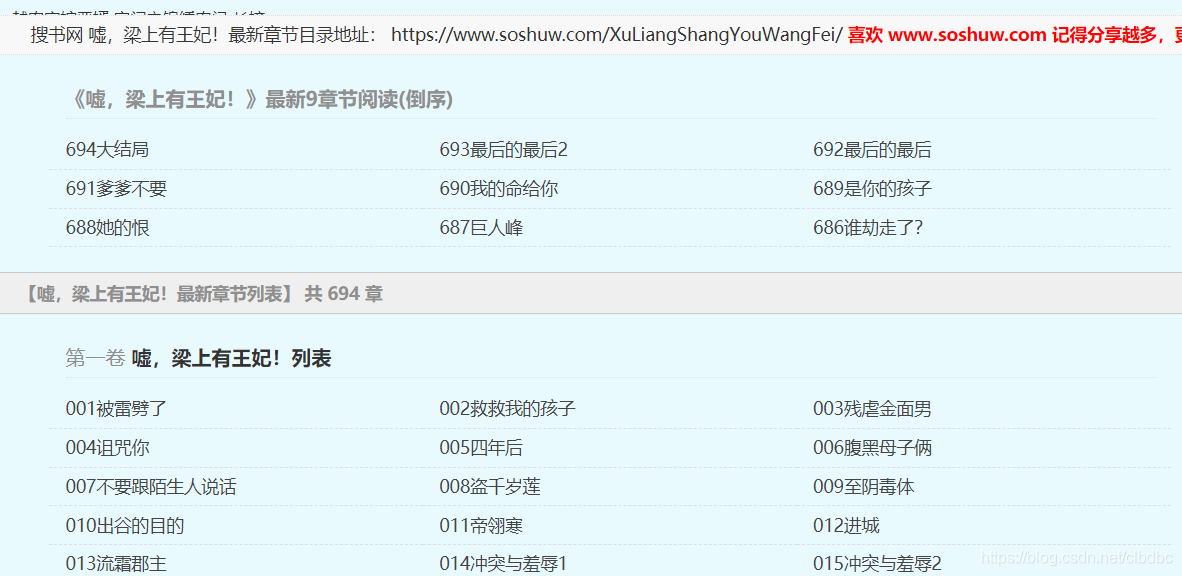
在網頁單擊右鍵選擇“檢查”(或者“屬性”,不同的瀏覽器的叫法不一致,我用的是IE)選擇“元素”列,鼠標再右側代碼塊上移動時。左側網頁會高亮顯示其對應網頁區域,找到完整目錄對應的代碼塊。如下圖:

完整目錄的錨有兩個,分別是class=”novel_list”和id=“novel108799”,仔細觀察後發現class不唯一,所以我們選用id提取該塊內容

將完整目錄塊提取出來
chapter_novel=chapter_page.find(id="novel108799") print(chapter_novel)
結果如下(僅部分結果):

對比小說章節內容網址和目錄網址(base_url)發現,我們隻需要將base_url和章節內容網址的後半段拼接到一起就可以得到完整的章節內容網址
3.拼接地址
利用正則語言庫將地址後半段提取出來
chapter_novel_str=str(chapter_novel) regx = '<dd><a href="/XuLiangShangYouWangFei(.*?)"' chapter_href_list = re.findall(regx, chapter_novel_str) print(chapter_href_list)
拼接url:
定義一個列表chapter_url_list接收完整地址
chapter_url_list = [] for i in chapter_href_list: url=base_url+i chapter_url_list.append(url) print(chapter_url_list)
4.分析章節內容結構
打開章節,右鍵→“屬性”,查看內容結構,發現小說正文有class和id兩個錨,class是不變的,id隨著章節而變化,所以我們用class提取正文

提取正文段
chapter_novel=chapter_page.find(id="novel108799") print(chapter_novel)
提取正文文本和標題
body_html=requests.get('https://www.soshuw.com/XuLiangShangYouWangFei/3647144.html')
body_page=ds(body_html.content,'lxml')
body = body_page.find(class_='content')
body_content=str(body)
print(body_content)
body_regx='<br/> (.*?)\n'
content_list=re.findall(body_regx,body_content)
print(content_list)
title_regx = '<h1>(.*?)</h1>'
title = re.findall(title_regx, body_html.text)
print(title)
5.保存文本
with open('1.txt', 'a+') as f:
f.write('\n\n')
f.write(title[0] + '\n')
f.write('\n\n')
for e in content_list:
f.write(e + '\n')
print('{} 爬取完畢'.format(title[0]))
6.完整代碼
import re
from bs4 import BeautifulSoup as ds
import requests
base_url='https://www.soshuw.com/XuLiangShangYouWangFei'
chapter_html=requests.get(base_url)
chapter_page=ds(chapter_html.content,'lxml')
chapter_novel=chapter_page.find(id="novel108799")
#print(chapter_novel)
chapter_novel_str=str(chapter_novel)
regx = '<dd><a href="/XuLiangShangYouWangFei(.*?)"'
chapter_href_list = re.findall(regx, chapter_novel_str)
#print(chapter_href_list)
chapter_url_list = []
for i in chapter_href_list:
url=base_url+i
chapter_url_list.append(url)
#print(chapter_url_list)
for u in chapter_url_list:
body_html=requests.get(u)
body_page=ds(body_html.content,'lxml')
body = body_page.find(class_='content')
body_content=str(body)
# print(body_content)
body_regx='<br/> (.*?)\n'
content_list=re.findall(body_regx,body_content)
#print(content_list)
title_regx = '<h1>(.*?)</h1>'
title = re.findall(title_regx, body_html.text)
#print(title)
with open('1.txt', 'a+') as f:
f.write('\n\n')
f.write(title[0] + '\n')
f.write('\n\n')
for e in content_list:
f.write(e + '\n')
print('{} 爬取完畢'.format(title[0]))
到此這篇關於使用PyCharm批量爬取小說的文章就介紹到這瞭,更多相關PyCharm批量爬取小說內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found