Python獲取網頁數據詳解流程
Requests 庫是 Python 中發起 HTTP 請求的庫,使用非常方便簡單。
發送 GET 請求
當我們用瀏覽器打開東旭藍天股票首頁時,發送的最原始的請求就是 GET 請求,並傳入url參數.
import requests url='http://push2his.eastmoney.com/api/qt/stock/fflow/daykline/get'
用Python requests庫的get函數得到數據並設置requests的請求頭.
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
得到network的參數.
data={
'cb': 'jQuery1123026726575651052076_1633873068863',
'lmt': '0',
'klt':' 101',
'fields1': 'f1,f2,f3,f7',
'fields2': 'f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61,f62,f63,f64,f65',
'ut': 'b2884a393a59ad64002292a3e90d46a5',
'secid': '0.000040',
'_': '1633873068864'
}
我們使用 content 屬性來獲取網站返回的數據,並命名為sd.
sd=requests.get(url=url,headers=header,data=data).content
json庫可以自字符串或文件中解析JSON。 該庫解析JSON後將其轉為Python字典或者列表。re模塊是python獨有的匹配字符串的模塊,該模塊中提供的很多功能是基於正則表達式實現的,而正則表達式是對字符串進行模糊匹配,提取自己需要的字符串部分.
import json import re text=str(sd,'utf-8') res=re.findall(r'[(](.*?)[)]',text) re=json.loads(res[0]) p=re['data']['klines']
將雜亂無章的數據排版到excel中,代碼如下:
all_list=re['data']['klines']
data_list=[]
latest_price_list=[]
price_limit_list=[]
net_amount_list1=[]
net_proportion_list1=[]
net_amount_list2=[]
net_proportion_list2=[]
net_amount_list3=[]
net_proportion_list3=[]
net_amount_list4=[]
net_proportion_list4=[]
net_amount_list5=[]
net_proportion_list5=[]
for i in range(len(all_list)):
data=all_list[i].split(',')[0]
data_list.append(data)
##收盤價
latest_price=all_list[i].split(',')[11]
latest_price_list.append(latest_price)
##漲跌幅
price_limit=all_list[i].split(',')[12]
price_limit_list.append(price_limit)
##主力凈流入
####凈額
net_amount1=all_list[i].split(',')[1]
net_amount_list1.append(net_amount1)
##占比
net_proportion1=all_list[i].split(',')[6]
net_proportion_list1.append(net_proportion1)
##超大單凈流入
####凈額
net_amount2=all_list[i].split(',')[5]
net_amount_list2.append(net_amount2)
##占比
net_proportion2=all_list[i].split(',')[10]
net_proportion_list2.append(net_proportion2)
##大單凈流入
####凈額
net_amount3=all_list[i].split(',')[4]
net_amount_list3.append(net_amount3)
##占比
net_proportion3=all_list[i].split(',')[9]
net_proportion_list3.append(net_proportion3)
##中單凈流入
####凈額
net_amount4=all_list[i].split(',')[3]
net_amount_list4.append(net_amount4)
##占比
net_proportion4=all_list[i].split(',')[8]
net_proportion_list4.append(net_proportion4)
##小單凈流入
####凈額
net_amount5=all_list[i].split(',')[2]
net_amount_list5.append(net_amount5)
##占比
net_proportion5=all_list[i].split(',')[7]
net_proportion_list5.append(net_proportion5)
#print(data_list)
import pandas as pd
df=pd.DataFrame()
df['日期'] = data_list
df['收盤價'] = latest_price_list
df['漲跌幅(%)'] = price_limit_list
df['主力凈流入-凈額'] = net_amount_list1
df['主力凈流入-凈占比(%)'] = net_proportion_list1
df['超大單凈流入-凈額'] = net_amount_list2
df['超大單凈流入-凈占比(%)'] = net_proportion_list2
df['大單凈流入-凈額'] = net_amount_list3
df['大單凈流入-凈占比(%)'] = net_proportion_list3
df['中單凈流入-凈額'] = net_amount_list4
df['中單凈流入-凈占比(%)'] = net_proportion_list4
df['小單凈流入-凈額'] = net_amount_list5
df['小單凈流入-凈占比(%)'] = net_proportion_list5
df# 寫入excel
df.to_excel('東旭藍天資金流向一覽表.xlsx')
將爬取出的東旭藍天資金流向數據存到excel表中,得到表格的部分截圖如下:
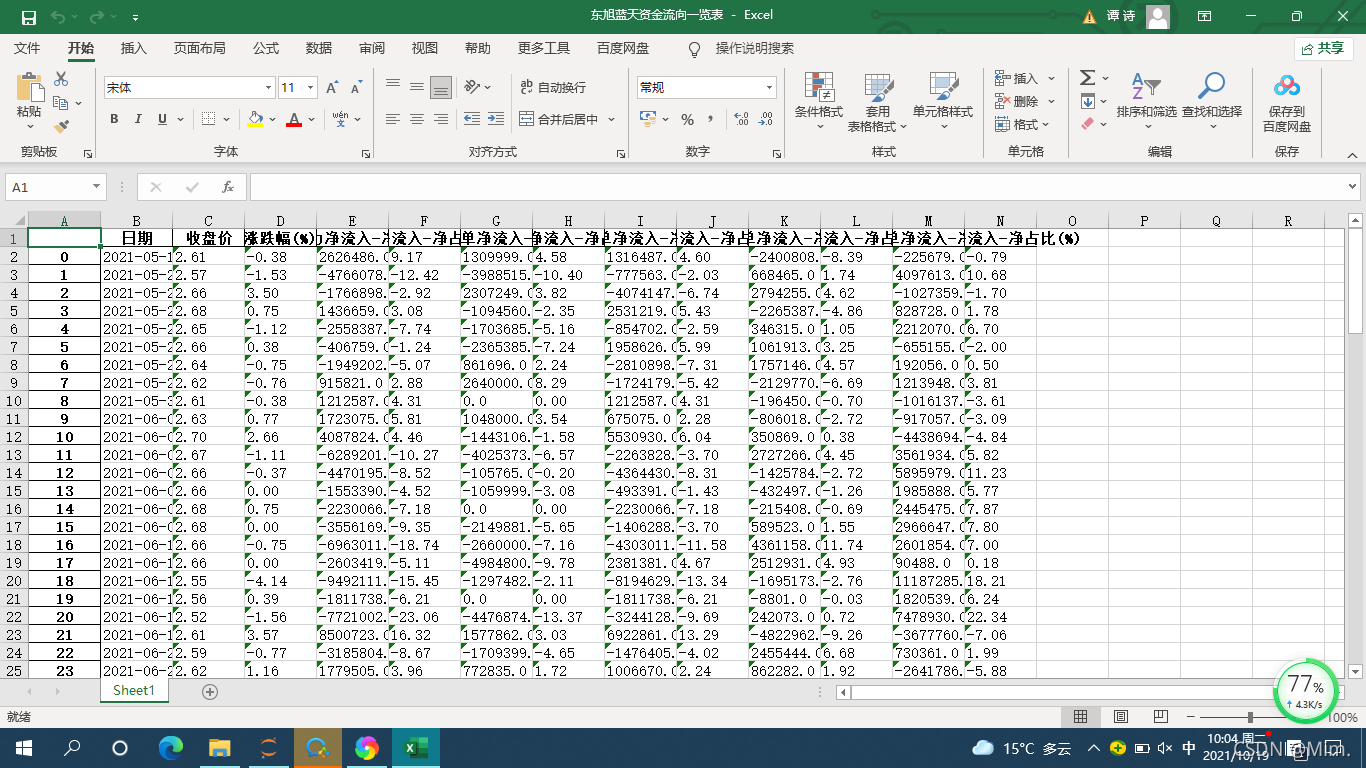
到此這篇關於Python獲取網頁數據詳解流程的文章就介紹到這瞭,更多相關Python 獲取網頁數據內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python實現生活常識解答機器人
- python3 requests 各種發送方式詳解
- 端午節將至,用Python爬取粽子數據並可視化,看看網友喜歡哪種粽子吧!
- 用Python采集《雪中悍刀行》彈幕做成詞雲實例
- 基於Python實現評論區抽獎功能詳解