Python爬蟲進階Scrapy框架精文講解
一、前情提要
為什麼要使用Scrapy 框架?
前兩篇深造篇介紹瞭多線程這個概念和實戰
多線程網頁爬取
多線程爬取網頁項目實戰
經過之前的學習,我們基本掌握瞭分析頁面、分析動態請求、抓取內容,也學會使用多線程來並發爬取網頁提高效率。這些技能點已經足夠我們寫出各式各樣符合我們要求的爬蟲瞭。
但我們還有一個沒解決的問題,那就是工程化。工程化可以讓我們寫代碼的過程從「想一段寫一段」中解脫出來,變得有秩序、風格統一、不寫重復的東西。
而Scrapy 就是爬蟲框架中的佼佼者。它為我們提前想好瞭很多步驟和要處理的邊邊角角的問題,而使用者可以專心於處理解析頁面、分析請求這種最核心的事情。
二、Scrapy框架的概念
Scrapy 是一個純 Python 實現的、流行的網絡爬蟲框架,它使用瞭一些高級功能來簡化網頁的抓取,能讓我們的爬蟲更加的規范、高效。
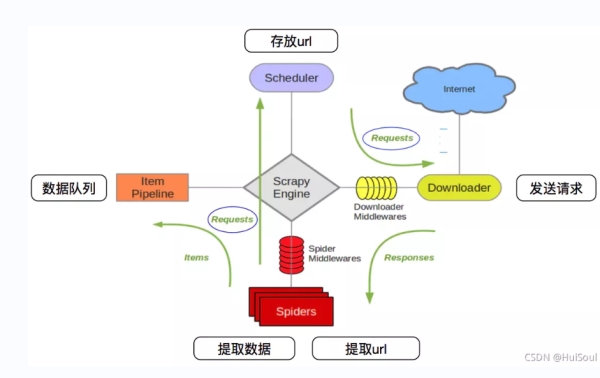
它可以分為如下幾個部分
| 組件 | 功能 |
|---|---|
| Scrapy Engine | Scrapy 引擎,負責控制整個系統的數據流和事件的觸發 |
| Scheduler | 調度器,接收 Scrapy 引擎發來的請求並將其加入隊列中,等待引擎後續需要時使用 |
| Downloader | 下載器,爬取網頁內容,將爬取到的數據返回給 Spiders(爬蟲) |
| Spiders | 爬蟲,這部分是核心代碼,用於解析、提取出需要的數據 |
| Item Pipeline | 數據管道,處理提取出的數據,主要是數據清洗、驗證和數據存儲 |
| Downloader middlewares | 下載器中間件,處理 Scrapy 引擎和下載器之間的請求和響應 |
| Spider middlewares | 爬蟲中間件,處理爬蟲輸入的響應以及輸出結果或新的請求 |
Scrapy 中數據流的過程如下
| 步驟 | 數據流 |
|---|---|
| 1 | 引擎打開一個網站,找到處理該網站對應的爬蟲,並爬取網頁的第一個頁面 |
| 2 | 引擎從爬蟲中獲取第一個頁面地址,並將其作為請求放進調度器中進行調度 |
| 3 | 引擎從調度器中獲取下一個頁面的地址 |
| 4 | 調度器返回下一個頁面的地址給 Scrapy 引擎,Scrapy 引擎通過下載器中間件傳遞給下載器進行爬取 |
| 5 | 爬取到數據後,下載器通過下載器中間件回傳給 Scrapy 引擎 |
| 6 | Scrapy 引擎將爬取到的數據通過爬蟲中間件傳遞給爬蟲進行數據解析、提取 |
| 7 | 爬蟲處理完數據後,將提取出的數據和新的請求回傳給 Scrapy 引擎 |
| 8 | Scrapy 將提取出的數據傳給數據管道進行數據清洗等操作,同時將新的請求傳遞給調度器準備進行下一頁的爬取 |
| 9 | 重復 2-8 步,直到調度器中沒有新的請求,數據爬取結束 |
三、Scrapy安裝
Win + R打開運行,點擊確定
然後在命令行上敲上
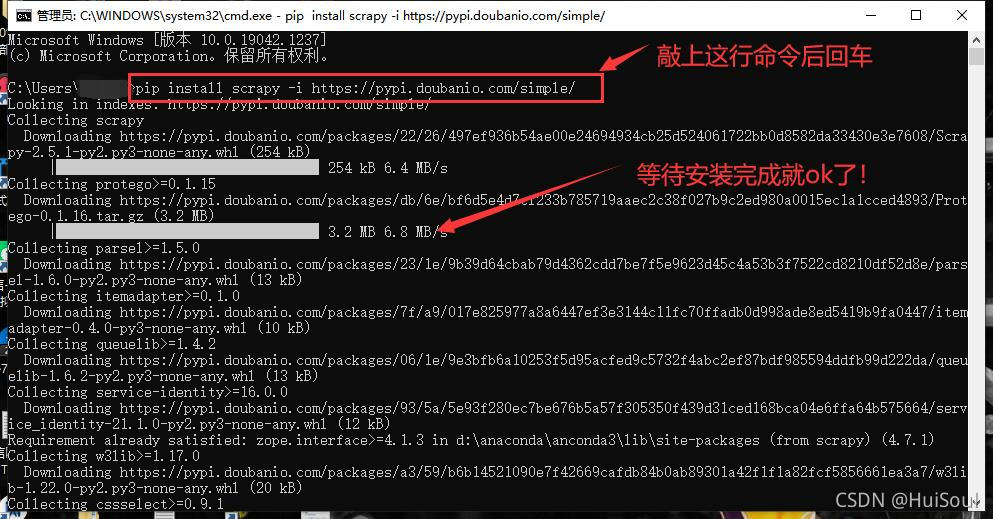
pip install scrapy -i https://pypi.doubanio.com/simple/ # 這句話後面 -i https://pypi.doubanio.com/simple/ 表示使用豆瓣的源,這樣安裝會更快
之後點擊回車,等待它自己安裝完成便可!
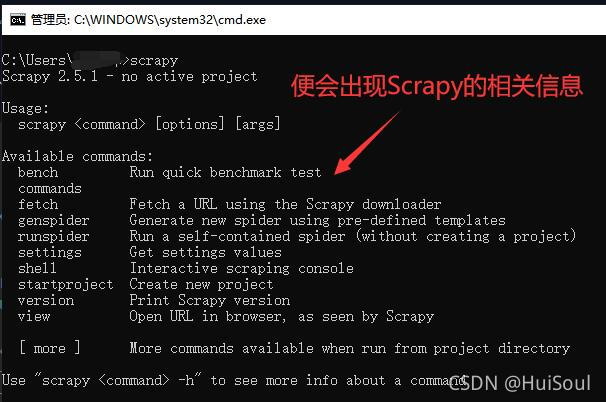
然後,我們在命令行上敲上scrapy,便會顯示scrapy的信息,這樣就代表安裝成功啦!
註意!!再然後我們在命令行敲上 explorer . (Mac 中是 open .,註意 . 前面有個空格) 命令並回車,可以打開命令行當前所在的目錄。下面,我們就要在這個目錄裡開始編寫代碼。
四、Scrapy實戰運用
這次我們試著用Scrapy爬取的網站是:小眾軟件 https://www.appinn.com/category/windows/
在進行網頁爬取前,我們先需要創建代碼文件,然後利用Scrapy命令進行執行。
在上面我們利用 explorer . 命令打開瞭目錄,在這個目錄下我們創建一個 spider.py 的文件↓
方法:創建文本文件改後綴名即可

然後將爬蟲代碼放進去,現在大傢先復制黏貼代碼,進行嘗試一下,之後我再來講解代碼的含義!

爬蟲代碼
import scrapy
# 定義一個類叫做 TitleSpider 繼承自 scrapy.Spider
class TitleSpider(scrapy.Spider):
name = 'title-spider'
# 設定開始爬取的頁面
start_urls = ['https://www.appinn.com/category/windows/']
def parse(self, response):
# 找到所有 article 標簽
for article in response.css('article'):
# 解析 article 下面 a 標簽裡的鏈接和標題
a = article.css('h2.title a')
if a:
result = {
'title': a.attrib['title'],
'url': a.attrib['href'],
}
# 得到結果
yield result
# 解析下一頁的鏈接
next_page = response.css('a.next::attr(href)').get()
if next_page is not None:
# 開始爬下一頁,使用 parse 方法解析
yield response.follow(next_page, self.parse)
然後在命令行中執行 scrapy 的 runspider 命令
scrapy runspider spider.py -t csv -o apps.csv # spider.py 是剛剛寫的爬蟲代碼的文件名 # -t 表示輸出的文件格式,我們用 csv,方便用 Excel 等工具打開 # -o 表示輸出的文件名,所以執行完會出現一個 apps.csv 的文件
敲完上面這句命令,稍等一下,你應該能看見很多的輸出
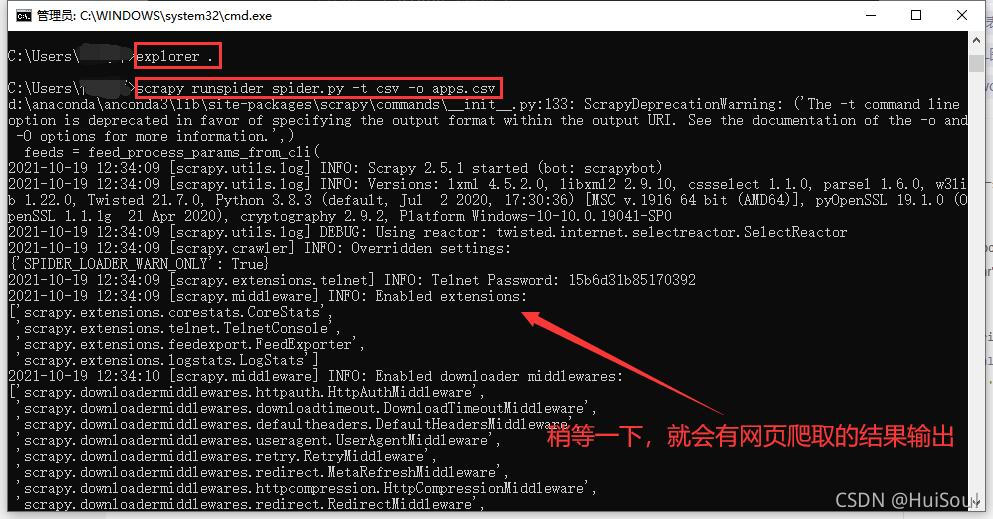
網頁爬取結果
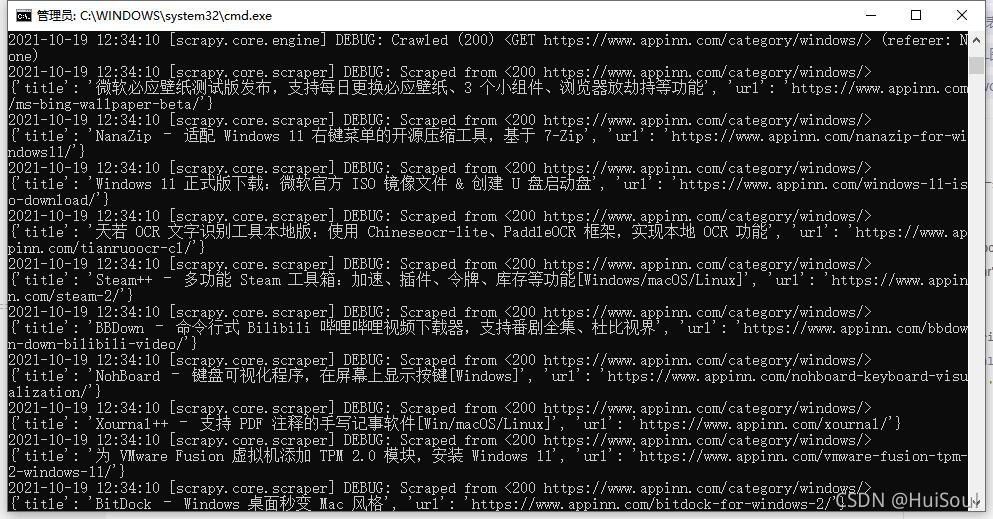
以及目錄裡多出來一個 apps.csv 文件。有 Excel 的同學可以用 Excel 打開 apps.csv,或者直接用記事本或者其他編輯器打開它。

打開後能看見 400 多篇小眾軟件的軟件推薦文章的標題和鏈接
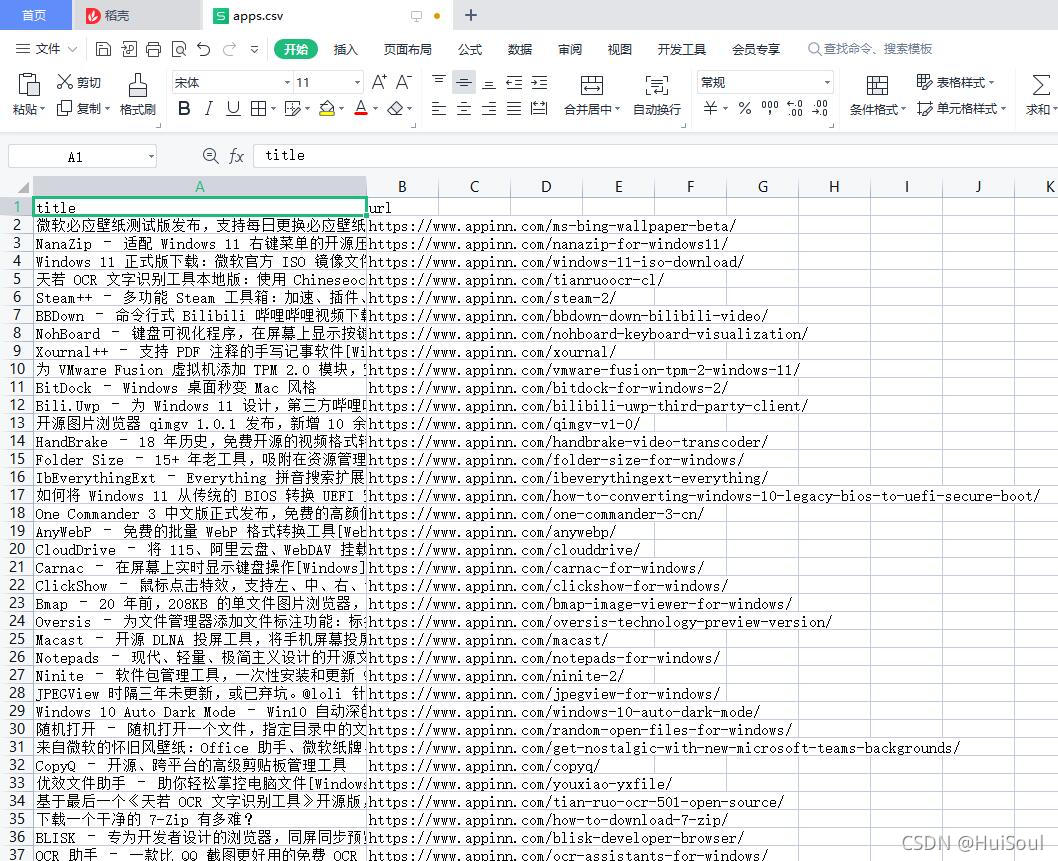
可是我們的代碼裡完全沒有用到 requests、beautifulsoup、concurrent 以及文件相關的庫,是怎麼完成瞭一次快速的爬取並寫到文件的呢?別急,讓我為你慢慢講解!
這一串代碼幹瞭什麼?
上面用到的爬蟲代碼
import scrapy
# 定義一個類叫做 TitleSpider 繼承自 scrapy.Spider
class TitleSpider(scrapy.Spider):
name = 'title-spider'
# 設定開始爬取的頁面
start_urls = ['https://www.appinn.com/category/windows/']
def parse(self, response):
# 找到所有 article 標簽
for article in response.css('article'):
# 解析 article 下面 a 標簽裡的鏈接和標題
a = article.css('h2.title a')
if a:
result = {
'title': a.attrib['title'],
'url': a.attrib['href'],
}
# 得到結果
yield result
# 解析下一頁的鏈接
next_page = response.css('a.next::attr(href)').get()
if next_page is not None:
# 開始爬下一頁,使用 parse 方法解析
yield response.follow(next_page, self.parse)
當運行scrapy runspider spider.py -t csv -o apps.csv時,Scrapy 會執行我們寫在 spider.py裡的爬蟲,也就是上面那段完整的代碼
1、首先,Scrapy 讀到我們設定的啟動頁面 start_urls,開始請求這個頁面,得到一個響應。
// An highlighted block start_urls = ['https://www.appinn.com/category/windows/']
2、之後,Scrapy 把這個響應交給 默認 的解析方法 parse 來處理。響應 response 就是 parse 的第一個參數
def parse(self, response):
3、在我們自己寫的 parse 方法裡,有兩個部分:一是解析出頁面裡的 article 標簽,得到標題和鏈接作為爬取的結果;二是解析 下一頁 按鈕這個位置,拿到下一頁的鏈接,並同樣繼續請求、然後使用 parse 方法解析
# 把這條結果告訴 Scrapy yield result # 通知 Scrapy 開始爬下一頁,使用 parse 方法解析 yield response.follow(next_page, self.parse)
yield 是 Python 中一個較高級的用法,在這裡我們隻需要知道,我們通過 yield 通知 Scrapy 兩件事:我們拿到瞭結果,快去處理吧、我們拿到瞭下一個要爬的鏈接,快去爬取吧。
流程圖
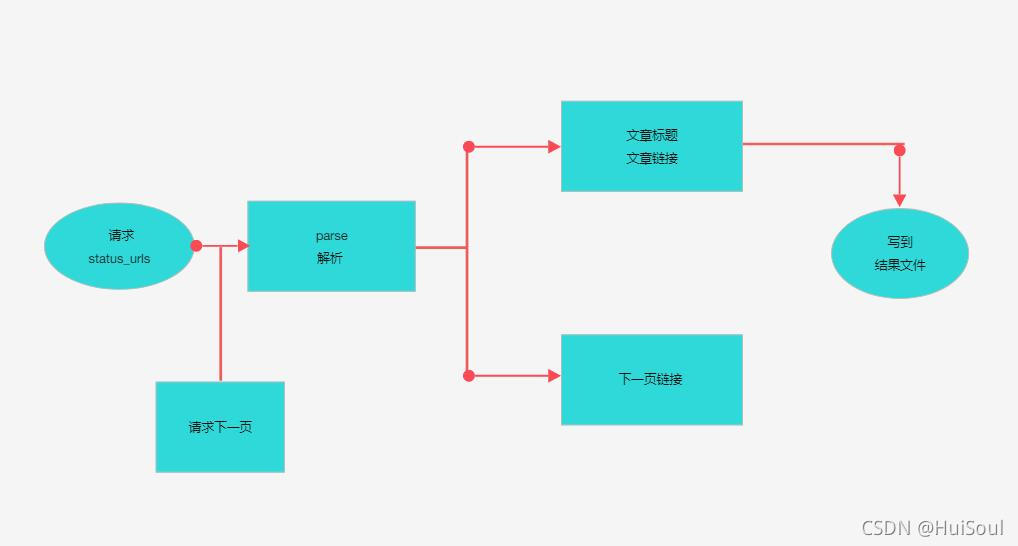
沒錯,除瞭解析想要的數據,其他的一切都是 Scrapy 替你完成的。這就是 Scrapy 的最大優勢:
requests 去哪瞭?不需要,隻要把鏈接交給 Scrapy 就會自動幫你完成請求;
concurrent 去哪瞭?不需要,Scrapy 會自動把全部的請求都變成並發的;
怎麼把結果寫到文件?不用實現寫文件的代碼,使用 yield 通知一下 Scrapy 結果即可自動寫入文件;
怎麼繼續爬取下一個頁面?使用 yield 通知 =Scrapy下一個頁面的鏈接和處理方法就好;
BeautifulSoup 去哪瞭?可以不需要,Scrapy 提供瞭好用的 CSS 選擇器。
解析數據這件事情還是值得我們關心的,即使 Scrapy 沒有強制讓我們使用什麼,因此我們非要繼續使用 BeautifulSoup也是可以的,隻需在 parse() 方法裡將 response.text 傳遞給 BeautifulSoup 進行解析、提取即可。
但是 Scrapy 提供瞭很好用的工具,叫做 CSS 選擇器。CSS 選擇器我們在 BeautifulSoup 中簡單介紹過,你還有印象嗎?
對BeautifulSoup這個庫忘記瞭的同學,可以看看我之前寫的一篇文章:requests庫和BeautifulSoup庫
Scrapy 中的 CSS 選擇器語法和 BeautifulSoup 中的差不多,Scrapy 中的 CSS 選擇器更加強大一些
# 從響應裡解析出所有 article 標簽
response.css('article')
# 從 article 裡解析出 class 為 title 的 h2 標簽 下面的 a 標簽
article.css('h2.title a')
# 取出 a 裡面的 href 屬性值
a.attrib['href']
# 從響應裡解析出 class 為 next 的 a 標簽的 href 屬性,並取出它的值
response.css('a.next::attr(href)').get()
scrapy 中的 CSS 選擇器可以取代 beautifulsoup 的功能,我們直接用它就解析、提取獲取到的數據。看到這裡,再回頭看上面的完整代碼,試著結合流程圖再理解一下就會有不錯的瞭解瞭。
五、Scrapy的css選擇器教學
我們還是打開之前爬取的網站:小眾軟件 https://www.appinn.com/category/windows/
用網頁開發者工具選中 下一頁↓
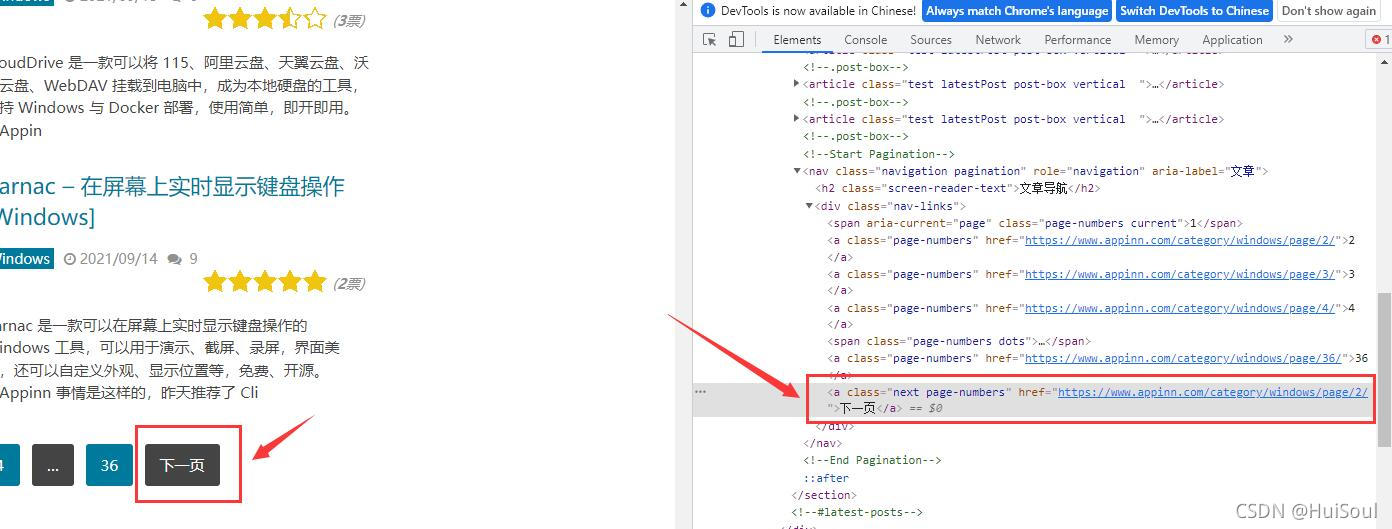
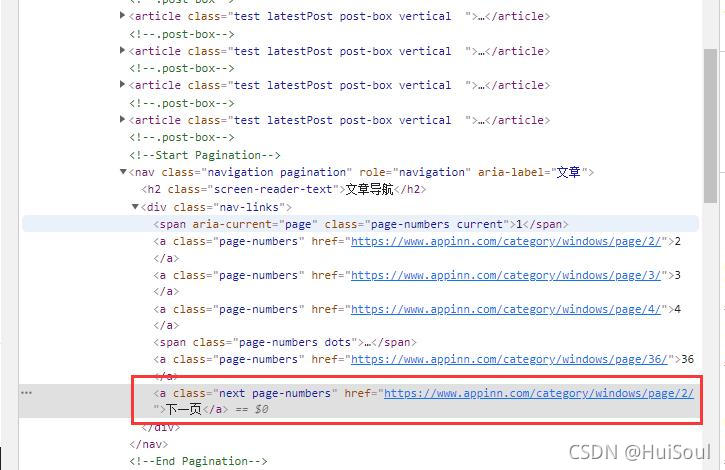
註意截圖中被框住的部分,瀏覽器已經展示出來這個按鈕的 CSS 選擇方法是什麼瞭。它告訴我們下一頁按鈕的選擇方式是a.next.page-numbers。
開始css選擇器教學前,我建議你使用 Scrapy 提供的互動工具來體驗一下 CSS 選擇器。方式是在命令行中輸入以下命令並回車
scrapy shell "https://www.appinn.com/category/windows/"
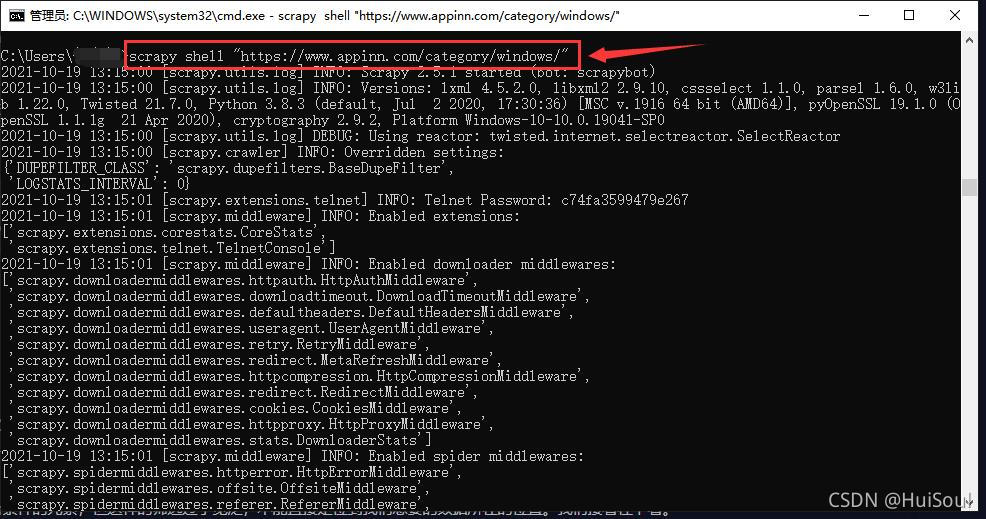
這時 Scrapy 已經訪問瞭這個鏈接,並把獲取到的結果記錄瞭下來,你會進入到一個交互環境,我們可以在這個環境裡寫代碼並一句一句執行。輸入 response 並回車,你能看見類似下面的響應,這就是上面獲取到的網頁結果。
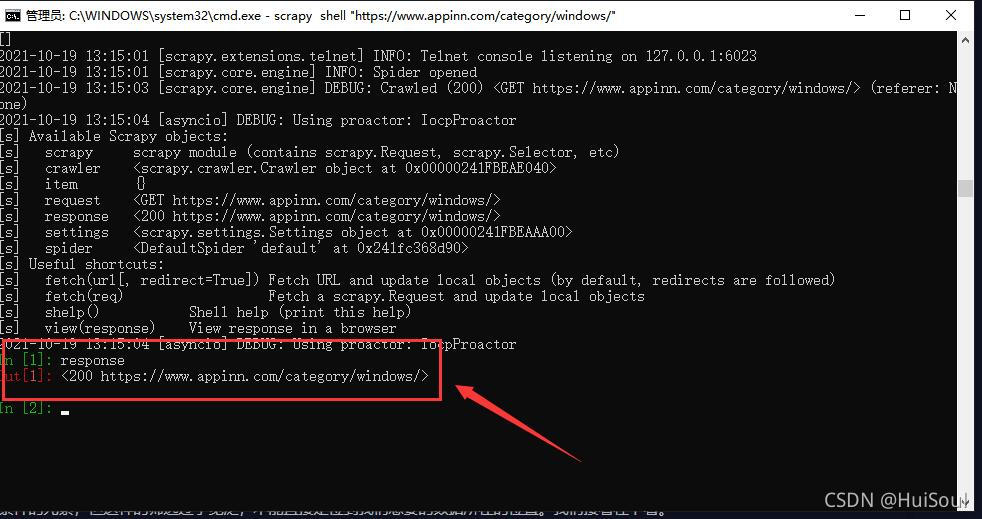
我之前有說過,輸出的200其實就是一個響應狀態碼,意思就是請求成功瞭!
之前的文章:requests庫和BeautifulSoup庫
下面我們就來學習一下css選擇器吧,我們以下圖中“下一頁”按鈕為例子
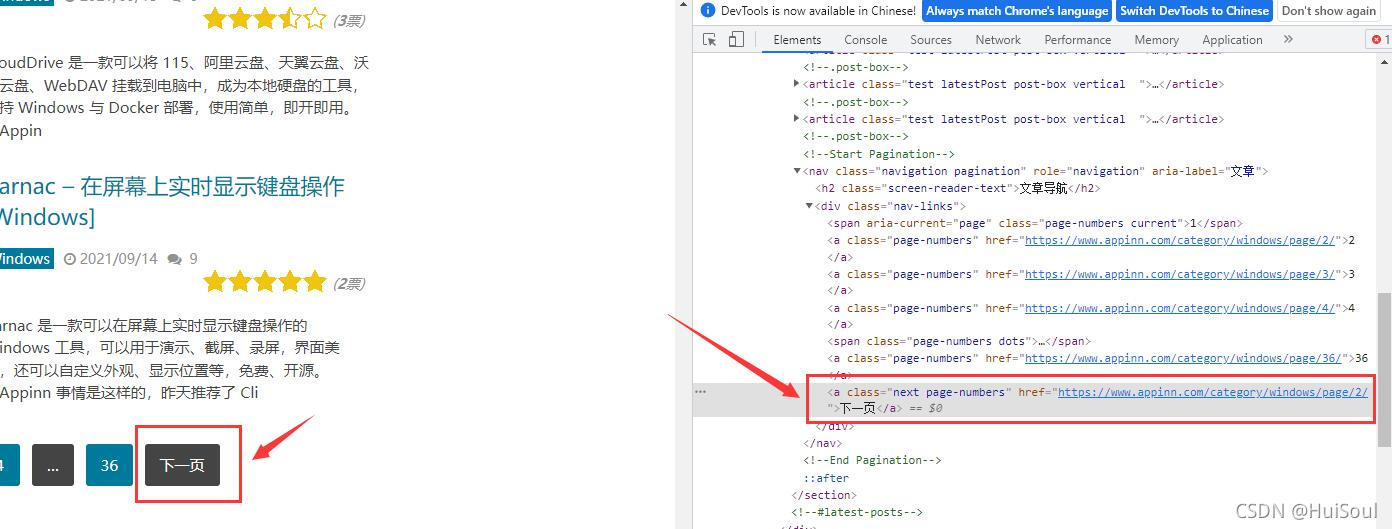
按標簽名選擇
小眾軟件網站下一頁按鈕的選擇方式是 a.next.page-numbers,其中的 a 是標簽名。試著在互動環境中,輸入 response.css(‘a’),可以看到頁面上所有的 a 元素。其他元素也是一樣,例如寫 response.css(‘ul’) 就可以選擇出所有 ul 元素,response.css(‘div’) 可以選擇出 div 元素。
按 class 選擇
a.next.page-numbers 中的.next 和 .page-numbers 表示 class的名字。當我們想要選擇 class 包含 container 的 div 元素,我們可以寫response.css(‘div.container’)。
上面的選擇器前面是標簽名,. 表示 class,後面跟著 class 的名稱。註意,它們是緊緊挨在一起的,中間不能有空格!
當要選擇的元素有多個 class 時,比如下面這樣的一個元素
<a class="next page-numbers" href="/windows/page/2/" rel="external nofollow" >下一頁</a>
這個 a 元素有 next 和 page-number 兩個 class,可以寫多個 . 來選擇:response.css(‘a.next.page-numbers’)。表示選擇 class 同時包含 next 和 page-numbers 的 a 元素,這裡它們也必須緊挨在一起,之前不能有空格。
按 id 選擇
除瞭 class 選擇器外,同樣也有 id 選擇器,Scrapy 中也是用 # 代表 id。比如網頁上的菜單按鈕,我們看到它的 id 是 pull,class 是 toggle-mobile-menu。所以可以寫 response.css(‘a#pull’),表示我們想選擇一個 id 為 pull 的 a 元素。
當然,你也可以組合使用:response.css(‘a#pull.toggle-mobile-menu’)。表示我們要選擇 id 為 pull,並且 class 包含 toggle-mobile-menu 的 a 元素。
按層級關系選擇
還是小眾軟件的這個頁面,如果我們想用 CSS 選擇器選中標題這個位置的 a 元素,使用 Chrome 選取之後發現這個 a 元素既沒有 id 也沒有 class,瀏覽器也隻給我們提示一個 a
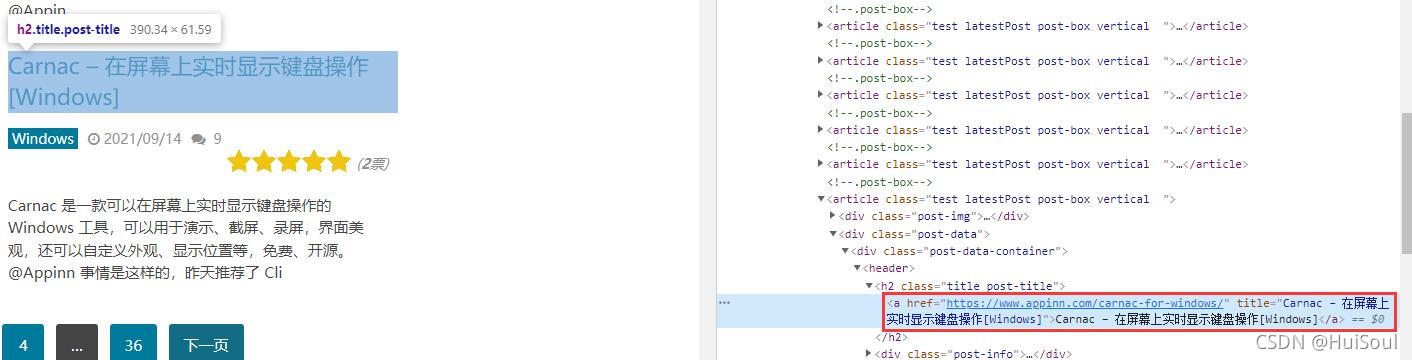
這時,我們就需要在該元素的父元素上找找線索,例如我們發現這個 a 元素在一個 h2 元素的下面,而這個 h2 元素是有 class 的,class 為 title 和 post-title。所以我們要做的是選擇 class 為 title 和 post-title 的 h2 元素下面的 a 元素,用 CSS 選擇器寫作
response.css('h2.title.post-title a::text')
可以看到,title 和 post-title 的 h2 元素寫作 h2.title.post-title,是緊緊連在一起的,而下面的 a 元素則在 a 前面加瞭一個空格。想起之前說過的規則瞭嗎?規則便是:並列關系連在一起,層級關系用空格隔開。
.title 和 .post-title 緊跟在 h2 後面,它倆都是 h2 的篩選條件。而空格後面跟著的 a 表示符合 h2.title.post-title 條件元素的子元素中的所有 a 元素。
我們之前還說過,空格後面表示的是所有的子元素,不管是處於多少層的子元素。而如果隻想要第一層的子元素則應該用 > 分隔開。這裡的 a 元素就是第一層的子元素,所以 h2.title.post-title a 和 h2.title.post-title > a 這兩種寫法的效果是一樣的。
取元素中的文本
我們拿到瞭標題位置的 a 元素,想要拿到其中的文本內容就需要在後面加上 ::text,代碼如下
response.css('h2.title.post-title a::text')
在互動環境執行一下,會發現文本內容能獲取到,但不是我們想要的純文本,如果想拿到純文本,還需要使用 get() 或者 getall() 方法,如下
# 取符合條件的第一條數據
response.css('h2.title.post-title a::text').get()
# 取符合條件的所有數據
response.css('h2.title.post-title a::text').getall()
取元素的屬性
還是用這個 a 元素舉例。如果我們想得到這個 a 元素的 href 屬性,需要調用這個元素的 attrib 屬性。在互動環境中執行下面兩句代碼
# 拿到符合選擇器條件的第一個 a 標簽
a = response.css('h2.title.post-title a')
a.attrib['href']
attrib 屬性實際上是一個字典,裡面存儲瞭元素上的所有 HTML 屬性。如果把第二句換成 a.attrib,你就能看到這個 a 元素上的所有屬性。類似的,輸入 a.attrib[‘title’],你可以得到它的 title 屬性。
現在我們試試打印所有符合 h2.title.post-title a 這個條件的標簽的 href 屬性,就像下面這樣
for a in response.css('h2.title.post-title a'):
print(a.attrib['href'])
或者另一種寫法也可以取到 href 屬性,就是加上 ::attr(href)
for href in response.css('h2.title.post-title a::attr(href)').getall():
print(href)
本次分享到此結束瞭,非常感謝大傢閱讀!!
有問題歡迎評論區留言!!
以上就是Python爬蟲進階Scrapy框架精文講解的詳細內容,更多關於Python爬蟲Scrapy框架的資料請關註WalkonNet其它相關文章!
推薦閱讀:
- Python scrapy爬取起點中文網小說榜單
- Python爬蟲教程使用Scrapy框架爬取小說代碼示例
- 一文讀懂python Scrapy爬蟲框架
- Python使用Beautiful Soup實現解析網頁
- Python Scrapy爬蟲框架使用示例淺析