python基礎之貪婪模式與非貪婪模式
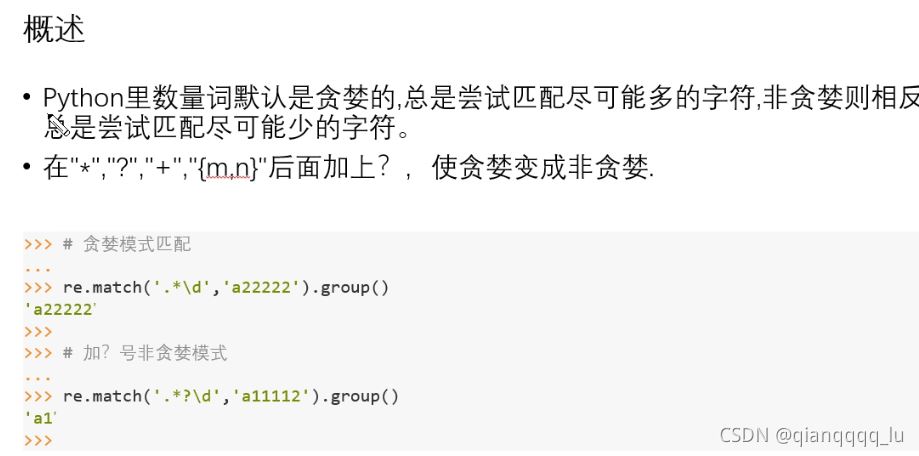
# 貪婪模式 默認的匹配規則
# 在滿足條件的情況下 盡可能多的去匹配到字符串
import re
rs = re.match('\d{6,9}', '111222333')
print(rs.group())
# 非貪婪模式 在滿足條件的情況下盡可能少的去匹配
rs = re.match('\d{6,9}?', '111222333')
print(rs.group())
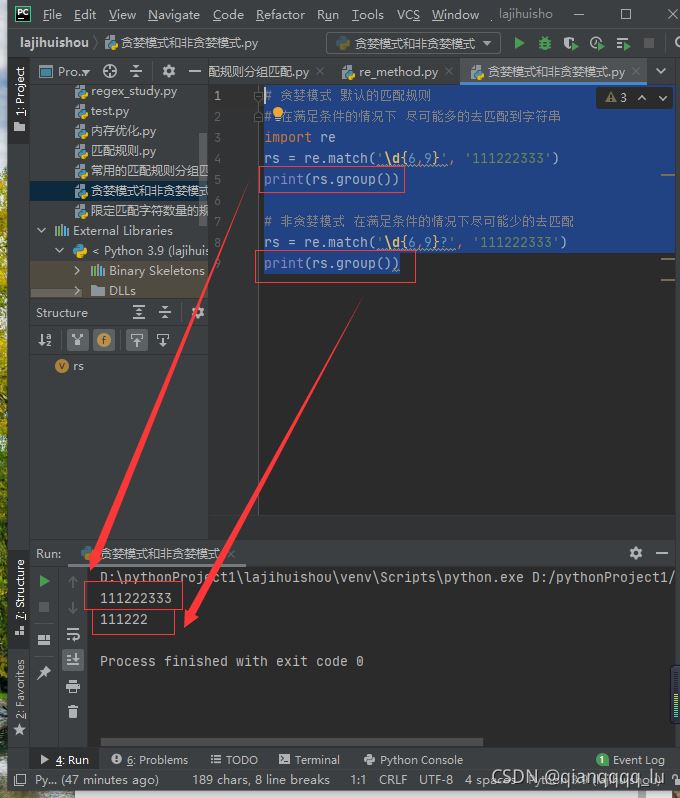
import re
content='aacbacbc'
pattren=re.compile('a.*b')
result=pattren.search(content)
print(result.group())
content='aacbacbc'
pattren=re.compile('a.*?b') #非貪婪模式匹配
result=pattren.search(content)
print(result.group())
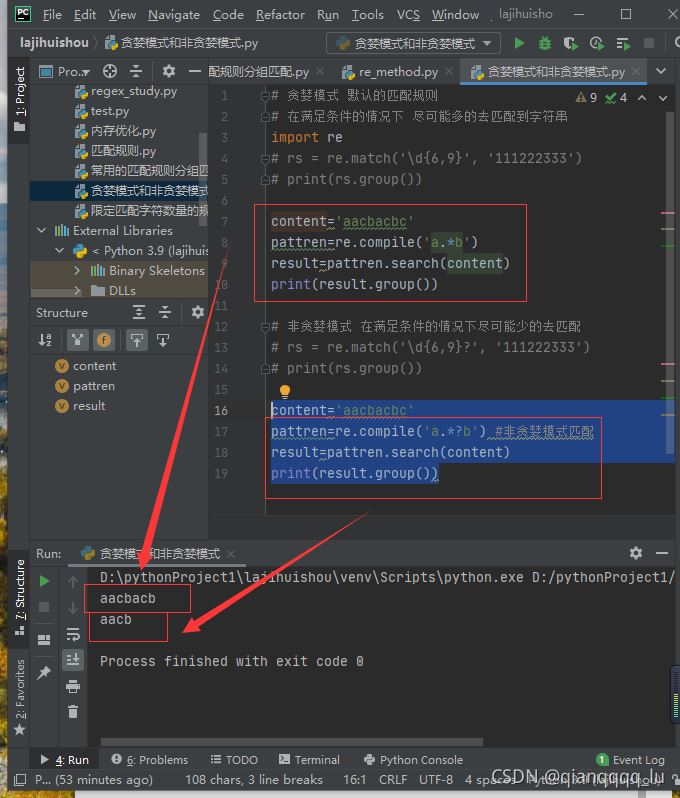






課後作業
import re
# 1.'save your heart for someone who cares' 請使用正則將文本中的
# “s” 替換成S 請寫python代碼完成匹配替換
data='save your heart for someone who cares'
res=re.sub('s','S',data)
print(res)
# 2.'<span>三生三世,十裡桃花
# </span><span>莫斯科行動</span><span>九州海上牧雲記</span>'
# 請使用正則將<span>標簽中的全部內容匹配出來 用python代碼實現
data='<span>三生三世,十裡桃花</span>' \
'<span>莫斯科行動</span><span>' \
'九州海上牧雲記</span>'
res=re.compile(r'<span>(.*)</span><span>(.*)</span><span>(.*)</span>')
result=res.findall(data)
print(result)
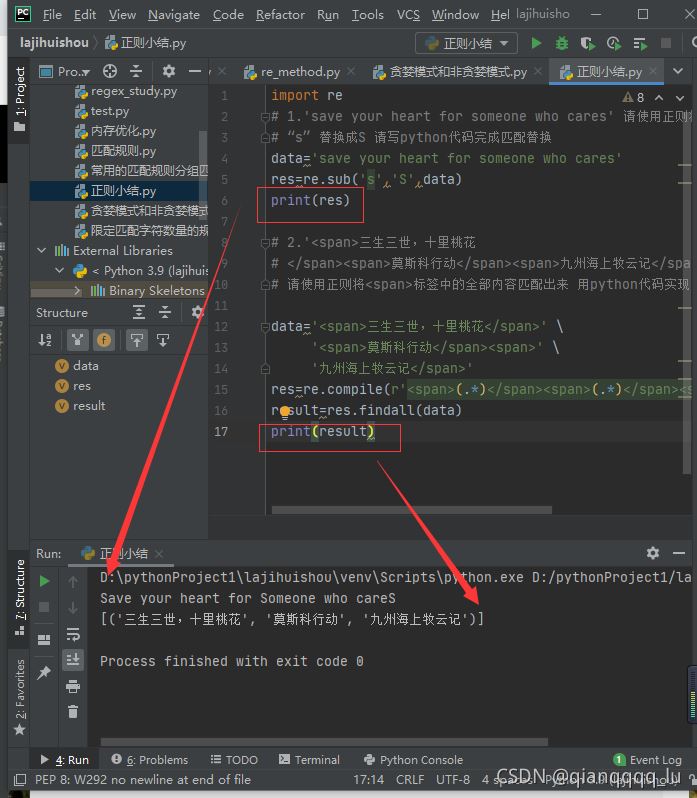
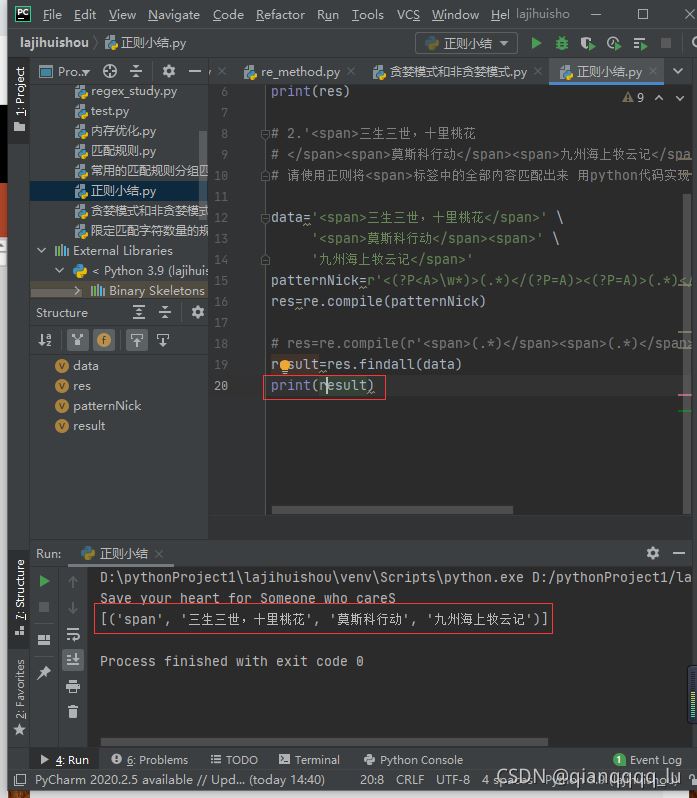
# 2.'<span>三生三世,十裡桃花
# </span><span>莫斯科行動</span><span>九州海上牧雲記</span>'
# 請使用正則將<span>標簽中的全部內容匹配出來 用python代碼實現
data='<span>三生三世,十裡桃花</span>' \
'<span>莫斯科行動</span><span>' \
'九州海上牧雲記</span>'
patternNick=r'<(?P<A>\w*)>(.*)</(?P=A)><(?P=A)>(.*)</(?P=A)><(?P=A)>(.*)</(?P=A)>'
res=re.compile(patternNick)
# res=re.compile(r'<span>(.*)</span><span>(.*)</span><span>(.*)</span>')
result=res.findall(data)
print(result)
總結
本篇文章就到這裡瞭,希望能夠給你帶來幫助,也希望您能夠多多關註WalkonNet的更多內容!
推薦閱讀:
- python接口自動化之正則用例參數化的示例詳解
- Python 正則表達式基礎知識點及實例
- python中re模塊知識點總結
- Python使用re模塊實現正則表達式操作指南
- python自動化之re模塊詳解